
By David Rieger
Reflections allow us to inspect and modify a program’s structure at its own runtime. In this article we will be looking at some parts of the go reflect package API and applying them to a real-world use case by building a generic application configuration mechanism.
What we have and what we want
We have implemented a Go data analysis application which will take data from an inventory database of a bookshop, process it, and turn it into human-readable statistical models that reflect the status of our inventory.
The output could, for example, be a list of books that were published by a certain author, or a bar chart depicting the number of books in our inventory per decade of publishing.
What we want is a way for us to configure what the application generates from the raw data in an abstract manner. There might be hundreds of algorithms that all process the raw data in different ways and produce different outputs, but not all outputs are relevant to us every time we run the application. We want to be able to configure our application to suit our needs and then just let it do what it has to do in order to deliver what we want from it.
We also want to be able to let the analytical process run — with a fixed configuration — autonomously and periodically on a job scheduler (e.g. Jenkins, Rundeck or cron) and report to us the output we are interested in, without having to interact with it before each run.
Eventually, we want the application to be easily extensible so that we can add new algorithms with as little effort as possible and without breaking any workflows.
Our core requirements on the architecture, therefore, are, in short:
- Persistent and abstracted configuration
- An interface through which both human users as well as other software (the job scheduler) can run the application
- Intuitive extensibility
Approach 1: The complacent
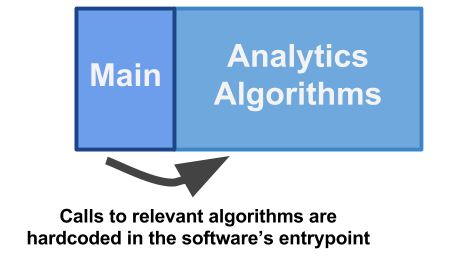
The most straightforward way to implement this is by first loading the raw data into our program, calling every analytical algorithm we want to run against it from the application’s main function, and eventually putting it all together in one nice report.
package main
func main() {
rawData := Parse("books_db.flatfile")
// Run algorithms of our choice against the data
bpDChart := amountOfBooksPerDecade(rawData)
bpAList := booksPerAuthor(rawData)
createReport(bpDChart, bpAList)
}
In terms of intuitive extensibility, this is probably as good as it gets (intuitive doesn’t imply good). Whenever we want to add a new analytical algorithm, we just implement it and call it in the main function if we want to run it.
However, there’s an obvious drawback: We need to touch the core application code and recompile the application not only whenever we extend the business logic, but also each time we want to change what is being generated by it (that is, each time we want to reconfigure it).
This approach doesn’t provide any sort of interface for the user to configure the application. It also doesn’t really address our requirement in an abstract manner to define what the application does. The developer of the software is basically the only one who can configure its behavior.
Of course, we could add a configuration file to the mix. This would allow us to select what algorithms to execute and which ones to omit without having to touch or recompile the application code. However, it will require some logic that maps the entries in the configuration file to (potentially hundreds of) functions in my application.
This logic will need to be adjusted each time I extend the application by a new analytical algorithm. Eventually, we will probably end up with a bunch of if statements running or omitting algorithms based on the presence or absence of strings in the configuration file. More on this later.
Approach 2: The client-friendly
The most common and perhaps cleanest way would be to provide a nice interface — a published API — on top of the analysis software, and a separate client, which talks to this API. The client can then decide whichever output it is interested in and call the appropriate API endpoints with according parameters. On the server side — our original analytics software — we then just run the relevant algorithms against the raw data, produce a report, and send it back to the client.
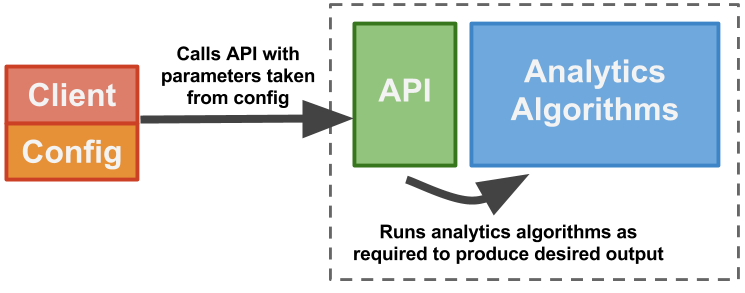
This probably makes for the cleanest architecture, but there are cases when it just isn’t the most ideal.
Looking at the requirements above and the previous approach, creating a separate client just moves the original problem from one place to another. Say I want to run the analytics application periodically with a certain setup (that is, with a certain definition of what output I’m interested in) and without having to interact with the application or its client each time it is run. I will need some sort of persistent configuration that maps to functions in my application. Whether I do that directly on the backend or on the client side doesn’t really matter to me.
Additionally, the extra interface and the client introduce a lot of inertia in terms of extensibility. Whenever we add a new analytical algorithm, which produces a different kind of statistical model, we need to adapt the interface of the service as well as the client which talks to this interface. Depending on who the client is, this might be well worth the effort, but in our case, it could just be unjustifiable overhead.
If my client was a human user who wants to press a couple of buttons to receive certain results at certain times, then yes, having a clean API exposing my analytics software is a must. But in this case, where the client is some job scheduler which we only touch every now and then, something else might be more suitable.
Approach 3: The generic
In order to address our requirements, we need to do two things: provide a design that doesn’t require us to maintain separate application layers (such as a segregated interface and a client) when extending the business logic, while at the same time allowing the client to define behavior without having to touch the application’s source code.
The first approach plus a configuration file would provide such a design. Writing a simple configuration file, parsing it, and then finding the appropriate algorithms to run is obvious enough. However, it doesn’t address extensibility very well.
Extending the business logic by adding new analytical algorithms will also require us to map parameters from the configuration file to the new algorithms. It will be necessary to adapt the config reader in order to support the new functionality. So we still have this extra layer that makes our software harder to extend.
It would be great if we could map parameters from the configuration file to functions in our business logic without having to explicitly implement a one to one (config to code) mapping for each of our (potentially hundreds of) analytical algorithms. Reflections enter the room.

Thankfully, each of our analytical algorithms has a unique name, and we can identify which one we want to run by specifying their names in the configuration. We tell the program which statistics we would like to see in the final report by typing the names of the associated algorithms into the config file. Now we only need something that takes these names from the config file, finds the functions with the same names in the business logic, and executes them (plus some code to put all results together in a report).
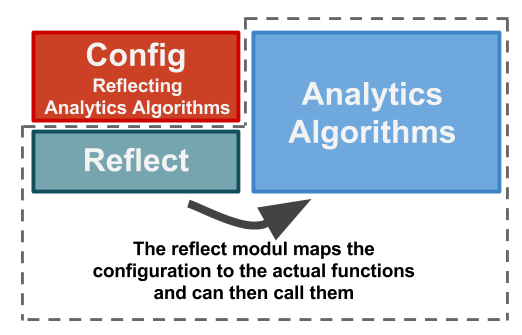
The part that finds the functions (given their names) is done by reflections. Reflections allow us to examine the business logic code structure and retrieve the actual function type given the function’s name.
This architecture allows us to easily extend out business logic without having to maintain another layer of our application or touch an existing code. The mapping of the configuration parameters to the analytics algorithms is done in a generic manner.
It also allows us to reconfigure the behavior of the application through an abstracted interface.
Note that we still need to recompile the whole application each time we extend the application by a new analytical algorithm. Plugin frameworks could help us avoid that, but this is beyond the scope of this article.
Of course, this architecture doesn’t come without drawbacks. Our reflect layer will just blindly retrieve functions and call them without knowing what these functions require or return. So we will need to implement all our analytical algorithms in a way that they can accept a generic type of input and return a generic type of output.
Each algorithm will return a different statistical model, but we need to return those models wrapped up in something the caller (that is, the reflect layer) can deal with. It can then send the wrapped-up model forward to the layer that produces the report which, of course, needs to be able to access the actual statistical model.
The way this is realized varies from language to language. We will look at (one way) to solve it in Go.
Finding Functions by their Names
The first step of getting from a plain YAML, JSON or XML configuration file to a callable algorithm (after loading the file into the application, of course) is to find a function in the software that matches the function name given in the configuration file.
Unfortunately, there is not really an intuitive way of retrieving a function residing in a package by its name in Go. We can’t just hand in a function name on one end and retrieve something callable on the other end.
However, it is possible to find a method of a type by its name.
A method in Go is a function that has a receiver, whereas a receiver can be any type that has been defined in the same package as the method.
type Library struct {
books []Book
}
func (l *Library) GetMostSoldBooks(startYear, endYear int) SoldStat {
...
}
Here we define a type Library which is based on type struct. We now take the above defined function GetMostSoldBooks, pull the library parameter out, and turn it into a receiver type which turns the function into a method of the *Library type. On the other hand, *Library describes a pointer to Library.
This is practical, not only because Go offers a way to find methods of types by their names, but also because it allows us to tie all statistical algorithms to the *Library type. We will need an instance of this anyway in all these algorithms, as it contains all the data about the library we want to process in the algorithms.
Instead of passing the library as just another parameter to each function, we can use the library as a receiver and — in return — get stronger coupling. In this case, it makes our code cleaner. Each new statistical algorithm that is to be added to the application now must be a method of the *Library type.
Now let’s take a look at how we can actually use the reflect package to retrieve the above method if all we’ve got is its name.
import "reflect"
m := reflect.ValueOf(&Library{}).MethodByName("GetMostSoldBooks")
First we need to take an instance of the receiver type (receiver type being *Library) and turn it into a reflect.Value by passing it to reflect.ValueOf(). On the returned value, we can then call MethodByName() with the name of the method we want to retrieve.
What we get in return is a callable function wrapped in reflect.Value which will accept exactly the parameters as we defined them in the method definition. Note that upon the call of this function, the instance of *Library we passed to reflect.ValueOf() will be used as the receiver type. This means it is important that you already passed the correct instance to the reflect.ValueOf()function.
To make the returned value m in the above example actually callable, we will need to cast it from reflect.Value to an actual function type with the correct signatures. This will look as follows:
mCallable := m.Interface().(func(int, int) SoldStat)
Note how we need to first turn it into an interface type and only then cast it to the function type.
Making Methods Generic
Ok, great. We now have a callable method which we retrieved by passing the function’s name to our application and letting reflections do the rest. But when it comes to calling the actual function, we’ve still got a bit of a problem.
We need to know the function’s signature in order to to be able to cast the reflect.Value returned by MethodByName() into a callable function. Since we have a lot of different analytical algorithms, chances are that the parameters they accept differ (we definitely don’t want to force a specific function signature onto developers who want to extend the application). This means that the method signatures vary and that we can’t just cast all values returned by the reflection into the exact same function type.
What we have to do is provide a generic function signature. We can do this by creating a wrapper method.
func (l *Library) GetMostSoldBooksWrap(p GenericParams) Reportable {
return l.GetMostSoldBooks(p.(*MostSoldBooksParams))
}
Here we’ve got a wrapper method GetMostSoldBooksWrap for the concrete method GetMostSoldBooks. Like the concrete method, the wrapper is a method of type *Library. The difference is its signature. It accepts a generic prameter GenericParams and returns an instance of type Reportable. In its body, it invokes the concrete analytical method that processes the library data. Also new is the type MostSoldBooksParams which wraps the parameters for the concrete method.
Now, let’s see where those new types come from.
In order to be able to pass the GenericParams parameter to the concrete GetMostSoldBooks() method, the concrete method also needs to only accept one single parameter which we can cast the generic parameter to. We do this by changing the method signature of the concrete function to accept a *MostSoldBooksParams parameter.
This may first sound as though we are forcing a method signature upon the analytical algorithms after all, therefore contradicting the statement made above. And in some ways that is true. But in some way it isn’t, because MostSoldBooksParams is of type struct and can therefore contain multiple fields.
type MostSoldBooksParams struct {
startYear int
endYear int
}
func (l *Library) GetMostSoldBooks(p *MostSoldBooksParams) SoldStat {
...
}
As you can see, the parameter for the analytical method still incorporates both integer parameters startYear and endYear we had defined in the method signature originally. The method also still returns the concrete type SoldStat.
Let’s go back to the wrapper method.
As we now need to map the strings from the configuration file to the wrapper methods rather than the concrete methods, we need a wrapper for each analytical algorithm. It needs to be named so that it makes sense to add this name to the config file.
In this solution here, we name wrappers with <concrete method name>Wrap. In the config file, we can then just provide the same concrete method’s name and the reflect logic will append “Wrap” to the string before looking for the method.
The signatures, however, are the exact same for every wrapper function (otherwise they would be futile).
type GenericParams interface {
IsValid() (bool, string)
}
The GenericParam parameter type is an interface. We declare one method IsValid() (bool, string) for this interface, meaning that every struct which defines this method automatically implements the GenericParams interface.
This is relevant because in our wrapper method, we cast the GenericParams interface to the concrete struct type MostSoldBooksParams . This only works if MostSoldBooksParams implements the GenericParams interface.
We therefore now provide a IsValid() method to our concrete parameter type.
func (p *MostSoldBooksParams) IsValid() (bool, string) {
…
return true, “”
}
The IsValid() function itself can be used to check the validity of the parameters passed to the concrete analytical method. We can call it at the very beginning of the method.
func (l *Library) GetMostSoldBooks(p *MostSoldBooksParams) SoldStat
{
if isValid, reason := p.IsValid(); !isValid {
log.Fatalf(“\nParams invalid:: %s”, reason)
}
...
}
Lastly, we have the Reportable type, which is our generic return value.
type Reportable interface {
Report() HTMLStatisticReport
}
Like the generic parameter type, Reportable is an interface. It declares one method Report() which will return a statistical report in HTML format.
Since our generic wrapper method directly returns the output of the concrete method, the concrete method’s return type must be of the generic wrapper method’s return type. This means that our SoldStat type, which is the type returned by the concrete analytical method, must implement the Reportabe interface.
We do this again by writing an implementation of the method declared by the interface.
func (p SoldStat) Report() HTMLStatisticReport {
...create report...
}
We will need to implement these methods for all different return types of all statistics algorithms so that the types can be returned by the generic wrappers. While this may appear to introduce a lot of overhead effort, converting the statistical output of each algorithm into a human-readable report is something that needs to be done either way.
Now that we have our generic design, we can go back to the reflections.
m := reflect.ValueOf(library).MethodByName("GetMostSoldBooksWrap")
mCallable = m.Interface().(func(GenericParams) Reportable)
These two lines of reflection can now be used to retrieve any analytical method wrapper by its name, whereby mCallable will be the callable wrapper method.
Passing Parameters
What’s missing are the method parameters. These will need to be parsed from the config file just like the method name and then passed to the wrapper method we retrieved through the reflection. This is where things become a bit convoluted.
statistics:
— statsMethodName: GetMostSoldBooks
startYear: 1984
endYear: 2018
The above shows an example configuration file in YAML format. We have a root element statistics which maps to a list. Each element in the list is an analytical algorithm we want to run and include its output in the report. The elements consist of a key statsMethodName, with the name of the analytical method as the value, and one key per parameter with their corresponding values. Note that the names of the parameters must match the names of the fields in the parameter struct declared for the associated method. In this case here, the parameter struct is the one we declared before, namely MostSoldBooksParams, with fields startYear and endYear, both of which are of type integer.
What we need to add to our reflection now is the mapping of the strings (and other value types) defining the parameters, from the configuration file to the method parameter struct’s fields.
Since the concrete method parameter struct is in the concrete method’s signature but not in the signature of the wrapper method, we will need to retrieve the concrete method through the reflection logic in addition to the wrapper method.
methodName := "GetMostSoldBooks" // taken from configuration file
conreteMethod := reflect.ValueOf(library).MethodByName(methodName)
wrapperName := fmt.Sprintf("%sWrap", methodName)
wrapperMethod := reflect.ValueOf(library).MethodByName(wrapperName)
Next we need to access the parameter type passed to the concrete method.
concreteMethodParamsType := conreteMethod.Type().In(0).Elem()
concreteMethodParamsType will now hold the type of the method parameter struct. For the case of the GetMostSoldBooks this is MostSoldBooksParams.
In order to be able to retrieve the struct fields (which represent the parameters needed by the analytical algorithm) by their names (which are given in the configuration file), we need to create an instance of the method parameter struct type. We need both a pointer to the instance as well as the instance itself (as will be seen later).
concreteMethodParamsPtr := reflect.New(concreteMethodParamsType)
concreteMethodParams := concreteMethodParamsPtr.Elem()
At this stage, you can iterate over the keys of the stats element from the configuration file and map the parameter types one-by-one to the fields in the parameter (that is, retrieving the fields of the method parameter struct according to their names). To retrieve a field of a struct by its name, we can use reflect.FieldByName().
parameterField := concreteMethodParams.FieldByName(configParam)
Once we have the parameter fields retrieved, we can map the value given for this parameter in the configuration file to the actual field.
if configValueInt, isInt := configValue.(int); isInt {
parameterField.SetInt(int64(configValueInt)
)
The above is for the case of integer values, but we could do the same for each value type we expect (in a trial and error fashion) for each parameter given in the configuration file. Setting the value on the parameter field here will also directly affect the method parameters struct, so we don’t need to explicitly alter concreteMethodParams in order to store the parameter value retrieved from the configuration file.
Lastly, just as we did with the wrapper method, we will cast the concreteMethodParams struct to a GenericParams type. Note that we need to use the pointer type there.
wrapperParams := concreteMethodParamsPtr.Interface().(GenericParams)
Putting it all together
Once we have our wrapper method and our generic method parameter, we can call the wrapper as follows.
wrapperMethod(wrapperParams)
As you can see, that’s just a normal function call. It does exactly the same as calling the wrapper would do without going through the reflection process.
Finally, you will just need a function that calls Report() on all of the return values from the invoked analytical method’s wrapper functions and puts the reports of each statistic into one coherent report file.
Now the question that you should ask is: Is this good code?
My answer: I don’t know.
What I can tell you is that it is an option worth exploring. Especially if you end up in a situation where you are in the need of a software design with similar requirements as the ones in this example — even if it’s just for the purpose of learning about reflections.
If you want to see the full code of an application using this design, check out: https://github.com/Demonware/harbor-analytics