By Timber.io
Why should you bother learning how to web scrape? If your job doesn’t require you to learn it, then let me give you some motivation.
What if you want to create a website which curates the cheapest products from Amazon, Walmart, and a couple of other online stores? A lot of these online stores don’t provide you with an easy way to access their information using an API. In the absence of an API, your only choice is to create a web scraper. This allows you to extract information from these websites automatically and makes that information easy to use.
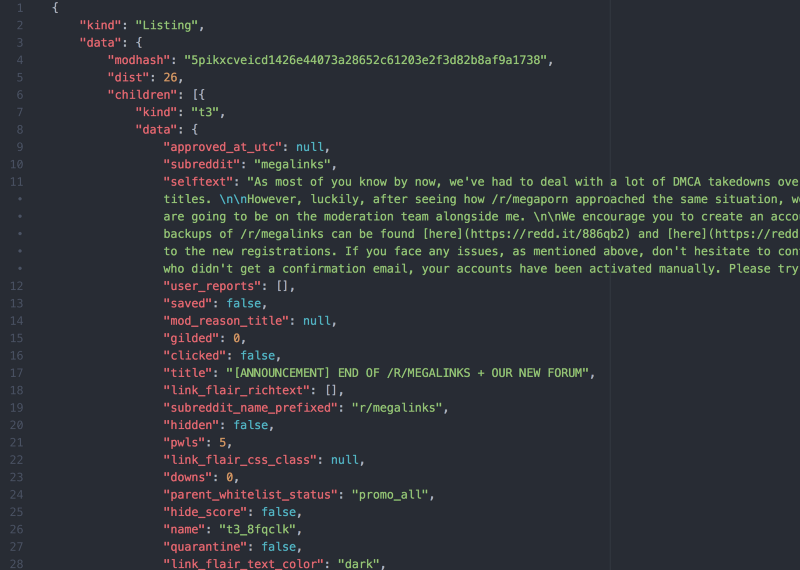
Here is an example of a typical API response in JSON. This is the response from Reddit:
There are a lot of Python libraries out there which can help you with web scraping. There is lxml, BeautifulSoup, and a full-fledged framework called Scrapy.
Most of the tutorials discuss BeautifulSoup and Scrapy, so I decided to go with lxml in this post. I will teach you the basics of XPaths and how you can use them to extract data from an HTML document. I will take you through a couple of different examples so that you can quickly get up-to-speed with lxml and XPaths.
Getting the data
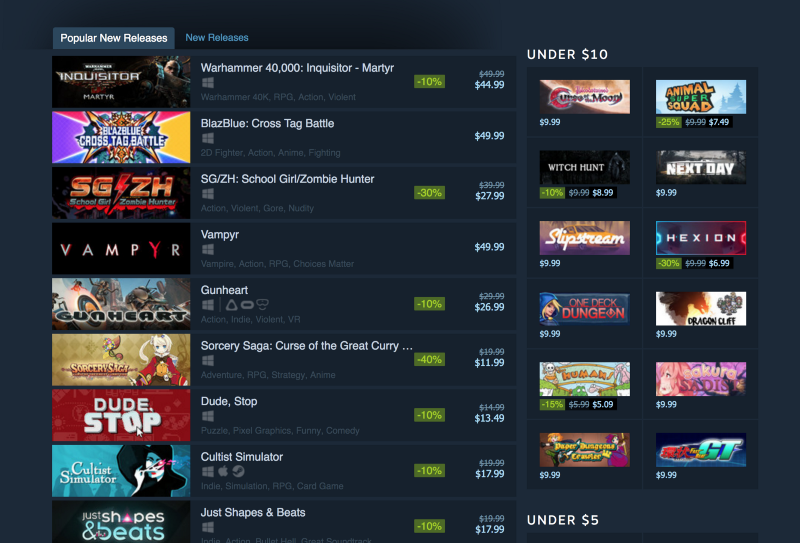
If you are a gamer, you will already know of (and likely love) this website. We will be trying to extract data from Steam. More specifically, we will be selecting from the “popular new releases” information.
I am converting this process into a two-part series. In this part, we will be creating a Python script which can extract the names of the games, the prices of the games, the different tags associated with each game and the target platforms. In the second part, we will turn this script into a Flask-based API and then host it on Heroku.
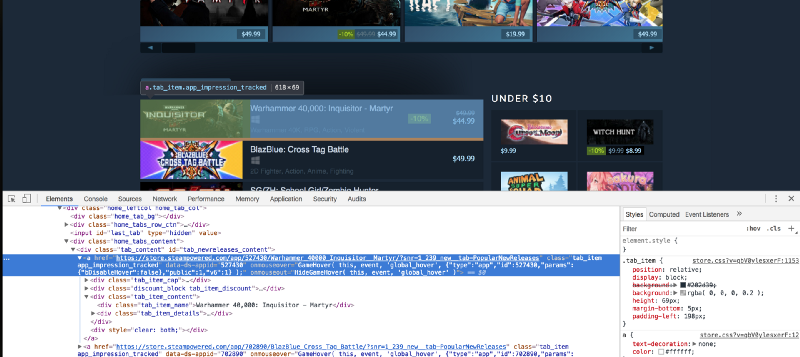
First of all, open up the “popular new releases” page on Steam and scroll down until you see the Popular New Releases tab. At this point, I usually open up Chrome developer tools and see which HTML tags contain the required data. I extensively use the element inspector tool (the button in the top left of the developer tools). It allows you to see the HTML markup behind a specific element on the page with just one click.
As a high-level overview, everything on a web page is encapsulated in an HTML tag, and tags are usually nested. You need to figure out which tags you need to extract the data from, and you’ll be good to go. In our case, if we take a look, we can see that every separate list item is encapsulated in an anchor (a) tag.
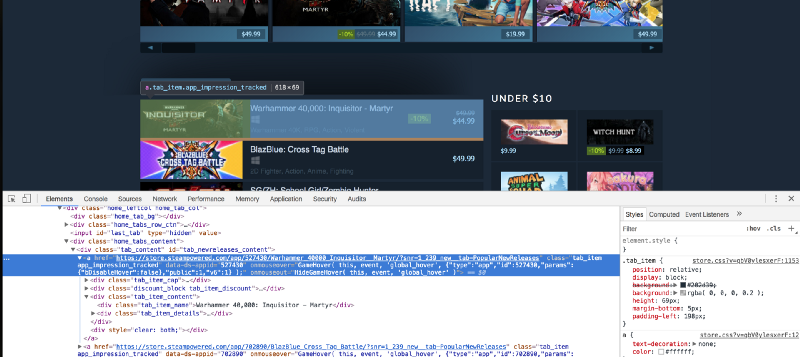
The anchor tags themselves are encapsulated in the div with an id of tab_newreleases_content. I mention the id because there are two tabs on this page. The second tab is the standard "New Releases" tab, and we don't want to extract information from that tab. So we will first extract the "Popular New Releases" tab, and then we will extract the required information from this tag.
This is a perfect time to create a new Python file and start writing down our script. I am going to create a scrape.py file. Now let's go ahead and import the required libraries. The first one is the [requests](http://docs.python-requests.org/) library and the second one is the [lxml.html](http://lxml.de/) library.
import requests import lxml.html
If you don’t have requests installed, you can easily install it by running this command in the terminal:
$ pip install requests
The requests library is going to help us open the web page in Python. We could have used lxml to open the HTML page as well, but it doesn't work well with all web pages. To be on the safe side, I am going to use requests.
Extracting and processing the info
Now let’s open up the web page using requests and pass that response to lxml.html.fromstring.
html = requests.get('https://store.steampowered.com/explore/new/') doc = lxml.html.fromstring(html.content)
This provides us with an object of HtmlElement type. This object has the xpath method which we can use to query the HTML document. This provides us with a structured way to extract information from an HTML document.
Now save this file and open up a terminal. Copy the code from the scrape.py file and paste it in a Python interpreter session.
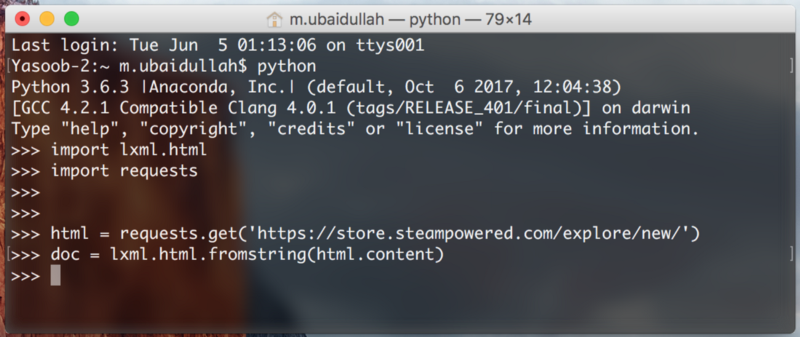
We are doing this so that we can quickly test our XPaths without continuously editing, saving and executing our scrape.py file.
Let’s try writing an XPath for extracting the div which contains the ‘Popular New Releases’ tab. I will explain the code as we go along:
new_releases = doc.xpath('//div[@id="tab_newreleases_content"]')[0]
This statement will return a list of all the divs in the HTML page which have an id of tab_newreleases_content. Now, because we know that only one div on the page has this id, we can take out the first element from the list ([0]) and that would be our required div. Let's break down the xpath and try to understand it:
//these double forward slashes telllxmlthat we want to search for all tags in the HTML document which match our requirements/filters. Another option is to use/(a single forward slash). The single forward slash returns only the immediate child tags/nodes which match our requirements/filtersdivtellslxmlthat we are searching fordivsin the HTML page[@id="tab_newreleases_content"]tellslxmlthat we are only interested in thosedivswhich have an id oftab_newreleases_content
Cool! We have the required div. Now let's go back to Chrome and check which tag contains the titles of the releases.
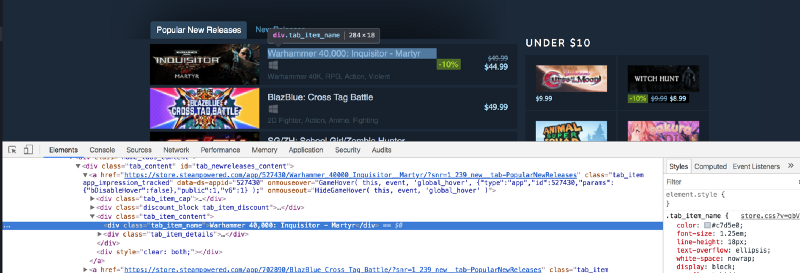
The title is contained in a div with a class of tab_item_name. Now that we have the "Popular New Releases" tab extracted, we can run further XPath queries on that tab. Write down the following code in the same Python console which we previously ran our code in:
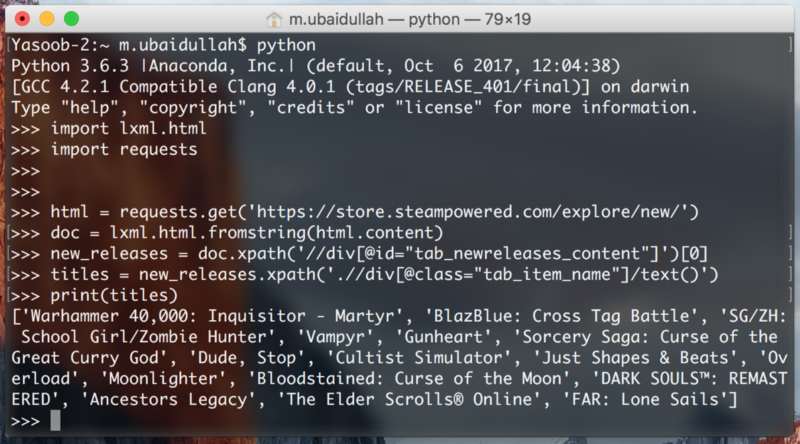
titles = new_releases.xpath('.//div[@class="tab_item_name"]/text()')
This gives us the titles of all of the games in the “Popular New Releases” tab. Here is the expected output:
Let’s break down this XPath a little bit, because it is a bit different from the last one.
.tells lxml that we are only interested in the tags which are the children of thenew_releasestag[@class="tab_item_name"]is pretty similar to how we were filteringdivsbased onid. The only difference is that here we are filtering based on the class name/text()tells lxml that we want the text contained within the tag we just extracted. In this case, it returns the title contained in the div with thetab_item_nameclass name
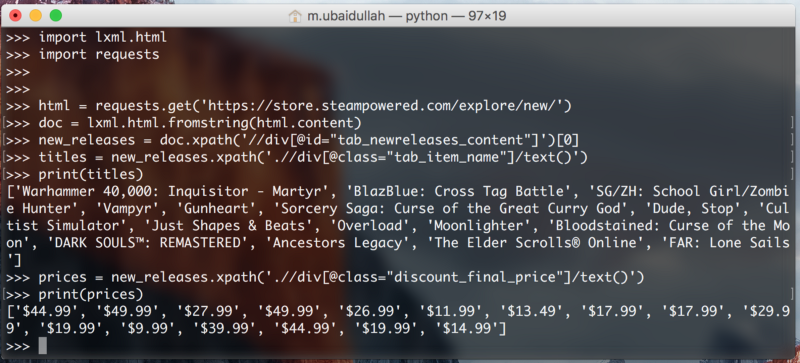
Now we need to extract the prices for the games. We can easily do that by running the following code:
prices = new_releases.xpath('.//div[@class="discount_final_price"]/text()')
I don’t think I need to explain this code, as it is pretty similar to the title extraction code. The only change we made is the change in the class name.
Now we need to extract the tags associated with the titles. Here is the HTML markup:
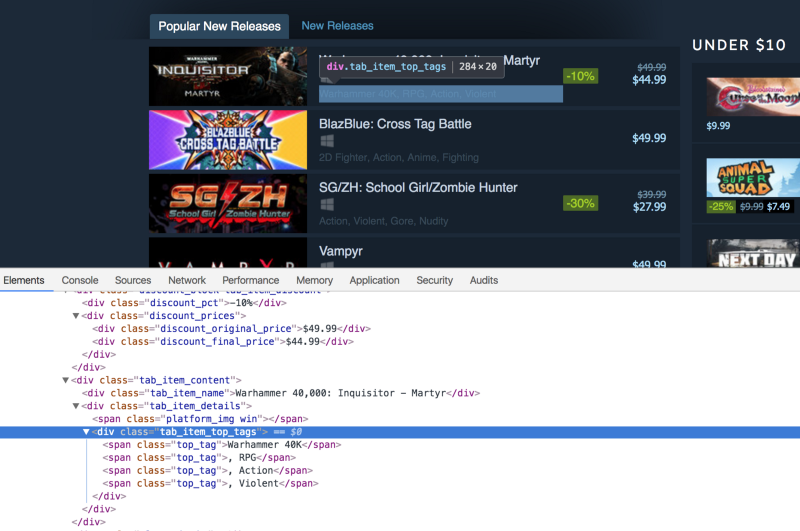
Write down the following code in the Python terminal to extract the tags:
tags = new_releases.xpath('.//div[@class="tab_item_top_tags"]')total_tags = []for tag in tags: total_tags.append(tag.text_content())
So what we are doing here is extracting the divs containing the tags for the games. Then we loop over the list of extracted tags and then extract the text from those tags using the [text_content()](http://lxml.de/lxmlhtml.html#html-element-methods) method. text_content() returns the text contained within an HTML tag without the HTML markup.
Note: We could have also made use of a list comprehension to make that code shorter. I wrote it down in this way so that even those who don’t know about list comprehensions can understand the code. Either way, this is the alternate code:
tags = [tag.text_content() for tag in new_releases.xpath('.//div[@class="tab_item_top_tags"]')]
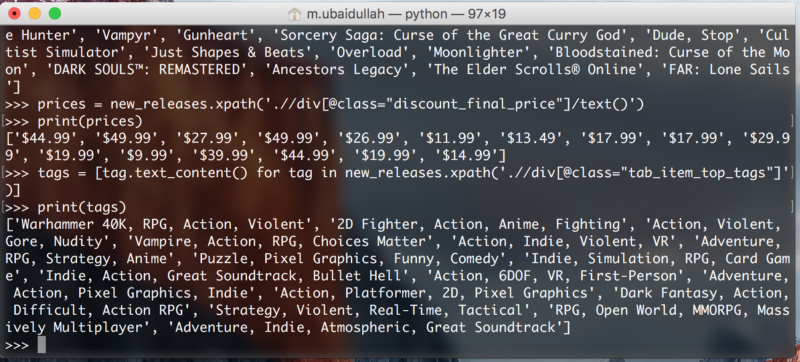
Let’s separate the tags in a list as well, so that each tag is a separate element:
tags = [tag.split(', ') for tag in tags]
Now the only thing remaining is to extract the platforms associated with each title. Here is the HTML markup:
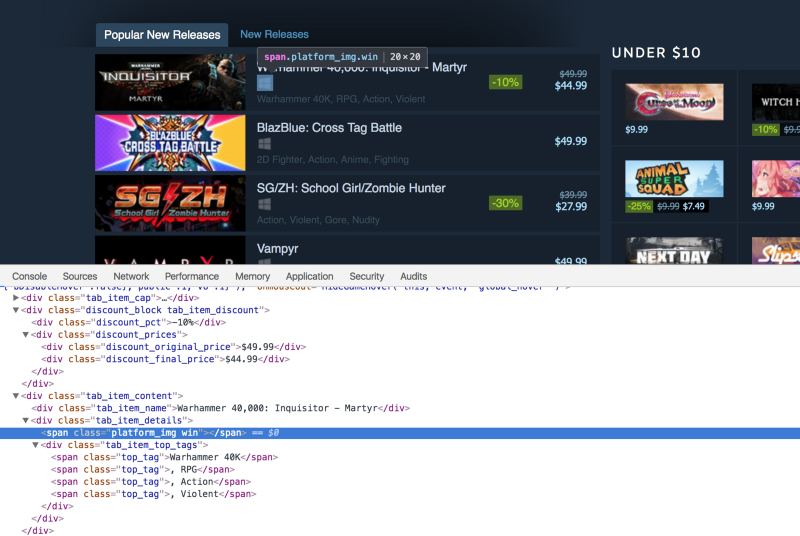
The major difference here is that the platforms are not contained as texts within a specific tag. They are listed as the class name. Some titles only have one platform associated with them, like this:
<span class="platform_img win"></span>
While some titles have 5 platforms associated with them, like this:
<span class="platform_img win"></span><span class="platform_img mac"></span><span class="platform_img linux"></span><span class="platform_img hmd_separator"></span> <span title="HTC Vive" class="platform_img htcvive"></span> <span title="Oculus Rift" class="platform_img oculusrift"></span>
As we can see, these spans contain the platform type as the class name. The only common thing between these spans is that all of them contain the platform_img class. First of all, we will extract the divs with the tab_item_details class. Then we will extract the spans containing the platform_img class. Finally, we will extract the second class name from those spans. Here is the code:
platforms_div = new_releases.xpath('.//div[@class="tab_item_details"]')total_platforms = []for game in platforms_div: temp = game.xpath('.//span[contains(@class, "platform_img")]') platforms = [t.get('class').split(' ')[-1] for t in temp] if 'hmd_separator' in platforms: platforms.remove('hmd_separator') total_platforms.append(platforms)
In line 1, we start with extracting the tab_item_details div. The XPath in line 5 is a bit different. Here we have [contains(@class, "platform_img")] instead of simply having [@class="platform_img"]. The reason is that [@class="platform_img"] returns those spans which only have the platform_img class associated with them. If the spans have an additional class, they won't be returned. Whereas [contains(@class, "platform_img")] filters all the spans which have the platform_img class. It doesn't matter whether it is the only class or if there are more classes associated with that tag.
In line 6 we are making use of a list comprehension to reduce the code size. The .get() method allows us to extract an attribute of a tag. Here we are using it to extract the class attribute of a span. We get a string back from the .get() method. In case of the first game, the string being returned is platform_img win so we split that string based on the comma and the whitespace. Then we store the last part (which is the actual platform name) of the split string in the list.
In lines 7–8 we are removing the hmd_separator from the list if it exists. This is because hmd_separator is not a platform. It is just a vertical separator bar used to separate actual platforms from VR/AR hardware.
This is the code we have so far:
import requestsimport lxml.htmlhtml = requests.get('https://store.steampowered.com/explore/new/')doc = lxml.html.fromstring(html.content)new_releases = doc.xpath('//div[@id="tab_newreleases_content"]')[0]titles = new_releases.xpath('.//div[@class="tab_item_name"]/text()')prices = new_releases.xpath('.//div[@class="discount_final_price"]/text()')tags = [tag.text_content() for tag in new_releases.xpath('.//div[@class="tab_item_top_tags"]')]tags = [tag.split(', ') for tag in tags]platforms_div = new_releases.xpath('.//div[@class="tab_item_details"]')total_platforms = []for game in platforms_div: temp = game.xpath('.//span[contains(@class, "platform_img")]') platforms = [t.get('class').split(' ')[-1] for t in temp] if 'hmd_separator' in platforms: platforms.remove('hmd_separator') total_platforms.append(platforms)
Now we just need this to return a JSON response so that we can easily turn this into a Flask based API. Here is the code:
output = []for info in zip(titles,prices, tags, total_platforms): resp = {} resp['title'] = info[0] resp['price'] = info[1] resp['tags'] = info[2] resp['platforms'] = info[3] output.append(resp)
This code is self-explanatory. We are using the [zip](https://docs.python.org/3/library/functions.html#zip) function to loop over all of those lists in parallel. Then we create a dictionary for each game and assign the title, price, tags, and platforms as a separate key in that dictionary. Lastly, we append that dictionary to the output list.
Wrapping up
In the next post, we will take a look at how we can convert this into a Flask based API and host it on Heroku.
I am Yasoob from Python Tips. I hope you guys enjoyed this tutorial. If you want to read more tutorials of a similar nature, please go to Python Tips. I regularly write Python tips, tricks, and tutorials on that blog. And if you are interested in learning intermediate Python, then please check out my open source book here.
Just a disclaimer: we’re a logging company here @ Timber. We’d love it if you tried out our product (it’s seriously great!), but you’re here to learn about web scraping in Python and we didn’t want to take away from that.
Originally published at timber.io.