
By Cher Don
How does the DNS work, and why is it important?
Overview
Throughout this series, we will be tackling the basics such as:
- How does DNS work? [You are here!]
- Network Stack, OSI Model
- HTTP Methods and Formats
- Client Identification
- Basic/Digest Authentication
- HTTPS working with SSL/TLS
What is HTTP?
HyperText Transfer Protocol (HTTP) is a protocol devised by Sir Tim Berners Lee in 1989. It forms the basis for how web pages communicate from the web server to the client’s browser.

DNS Servers
Is the connection to the webpage established immediately after typing in the Domain Name, such as medium.com? Definitely not!
Machines, unlike us, recognize the location of webpages by IP Addresses. These string of numbers, such as 104.16.121.127, are more machine friendly especially since there are millions of domain names on the Web.

The Domain Name System (DNS) plays a crucial role in the whole HTTP request process, as it allows us to call a webpage by typing a simple domain name, www.medium.com instead of 104.16.121.127 every time you want to access the site.
Without DNS, your brain would be filled with numbers just trying to remember the IP Addresses for every single website you use!
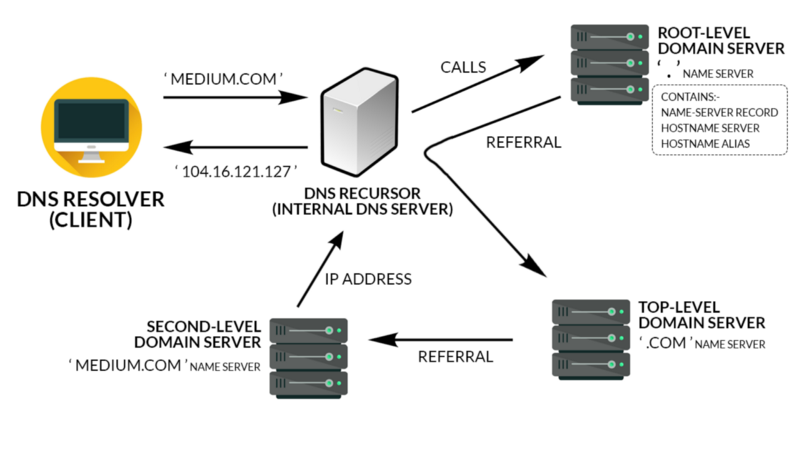
Now that we know that an IP Address is requested every time we type in the domain name, let’s find out where this request searches for the correct IP Address.
Local Cache
A cache is a block of memory for temporary storage of data that has a high probability of being used again. The first thing that happens is the DNS Resolver (residing in your computer) will check the browser’s cache, followed by the computer’s DNS cache. If you accessed the website recently, it would have the IP address cached in the system.
In that case, the browser can immediately call the IP Address to retrieve the webpage!
One thing to note here is that every cache has an expiry date, called the “Time to Live” setting. This setting determines how long the cache may be stored when the website is accessed. We will address how that works later on.
DNS Recursor
If the IP Address can’t be found in the local cache, it will then request from the DNS Recursor. The DNS Recursor is often the DNS Server of your Internet Service Provider (ISP).
These Internal DNS Servers have caches from websites that their clients have visited recently. Again, if the IP Address can’t be found here, it will be passed on to the next Domain Server.
Root-Level Domain Server
The Root-Level Domain Server (RLDS), or sometimes called the ‘ . ’ Name Server, is simply a gatekeeper for requests. It reads the request and locates the appropriate domain server to redirect to.

As such, it plays an important role in redirection to the next layer of Domain Servers. They are dispersed all around the world to prevent malicious attacks from bringing down the World Wide Web by targeting the RLDS.
Top-Level Domain Server
The Top-Level Domain Server (TLDS) is the name server for domains that end with their specific domain suffixes such as .com, .org or .io. After being passed down by RLDS, this layer works in the same way as the second gatekeeper. It takes the requests and runs through its DNS Server to redirect the request to the last and final stop, the Second-Level Domain Server.
The number of domain names are increasing exponentially. It is impossible for the RLDS to be able to store or redirect such a sheer amount of IP Addresses. As such, it is redirected to the TLDS to diversify the processing power and memory required.
Second-Level Domain Server
This layer is where all the information is stored about the domain is accessible. This DNS Server is usually owned by the institute that is responsible for hosting your website.
As such, a request for the record of the domain is sent to this DNS Server. It returns the IP Address, along with other important information such as the server it is on, and the alias it has.
Success!
The browser now receives the IP Address. It uses it to establish a connection with the host server using TCP/IP and retrieve the webpage via HTTP. We will discuss this in Part 2.
“Time to Live” Setting

DNS Records have a Time to Live (TTL) Setting. This determines the amount of time that any of the domain servers can cache the record.
Caching is important. It reduces the loading time for the page, since the DNS information will have to be reacquired every time the domain name is requested. Hence, a high TTL would allow the DNS records to stay alive for a longer period of time. This allow webpages to load faster.
Why don’t all DNS Records have a high TTL then?
By having a high TTL, it would mean that visitors would not see changes to the DNS immediately. Visitors only see the change after the DNS Record has expired.
For example, if we were to change the host for this webpage, and have a high TTL, the changes would not appear on the visitors browser immediately. This might result in broken links and users not being able to access the webpage.
Hostname — IP Address Relationship
So a single domain name is attached to one IP Address?
The answer is yes… and no. It can be, but doesn’t have to be a one-to-one relationship.
Single Hostname, Multiple IP Addresses
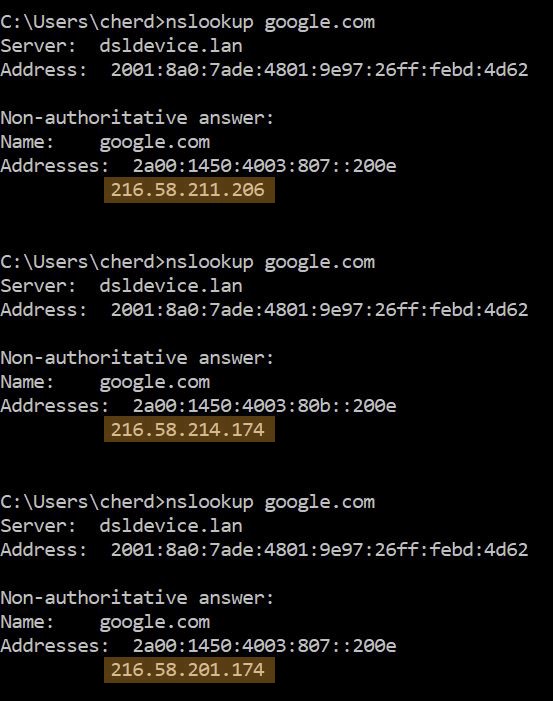
A single hostname such as www.google.com can correspond to multiple IP Addresses, to balance the load on the server since there is a significant amount of users calling on the same webpage at any one given point in time.
DNS Servers use a “Round Robin” method, such that all IP Addresses are equally utilized.
Multiple Hostname, Single IP Address
The purpose for this might be for referral links. For example, searching amazon.com/products/pc will show the product screen for PCs. Although amazon.com/products/pc?user=cherdon will also show the same webpage, any purchase would tell Amazon that I was the referrer, allowing me to gain commission from it.
Companies often buy multiple domains that link to the same webpage as well. For example, google.com and google.net would link you to the same search engine webpage.
Conclusion
The DNS Server is very important as it stores a database for machine-friendly IP Addresses under user-friendly Domain Names. Now that we have learnt how DNS Servers work together in a distributed database, let us explore how the connection with the host server is established with the IP Address in Part 2!
Hi! I’m Cher Don, currently pursuing a Major in Data Science. I’m the CTO of Paralegal Bot, and you can find my website below. Thanks for reading!
Piqued;
_Quality Content We offer the best content for difficult to grasp concepts. We've been there, and felt the same you do…_www.piqued.co