
By Hiren Patel
With the e-commerce boom, businesses have gone online. Customers, too, look for products online. Unlike the offline marketplace, a customer can compare the price of a product available at different places in real time.
Therefore, competitive pricing is something that has become the most crucial part of a business strategy.
In order to keep prices of your products competitive and attractive, you need to monitor and keep track of prices set by your competitors. If you know what your competitors’ pricing strategy is, you can accordingly align your pricing strategy to get an edge over them.
Hence, price monitoring has become a vital part of the process of running an e-commerce business.
You might wonder how to get hold of the data to compare prices.
The top 3 ways of getting the data you need for price comparison
1. Feeds from Merchants
As you might be aware, there are several price comparison sites available on the internet. These sites get into a sort of understanding with the businesses wherein they get the data directly from them and which they use for price comparison.
These businesses put into place an API, or utilize FTP to provide the data. Generally, a referral commission is what makes a price comparison site financially viable.
2. Product feeds from third-party APIs
On the other hand, there are services which offer e-commerce data through an API. When such a service is used, the third party pays for the volume of data.
3. Web Scraping
Web scraping is one of the most robust and reliable ways of getting web data from the internet. It is increasingly used in price intelligence because it is an efficient way of getting the product data from e-commerce sites.
You may not have access to the first and second option. Hence, web scraping can come to your rescue. You can use web scraping to leverage the power of data to arrive at competitive pricing for your business.
Web scraping can be used to get current prices for the current market scenario, and e-commerce more generally. We will use web scraping to get the data from an e-commerce site. In this blog, you will learn how to scrape the names and prices of products from Amazon in all categories, under a particular brand.
Extracting data from Amazon periodically can help you keep track of the market trends of pricing and enable you to set your prices accordingly.
Table of contents
1. Web scraping for price comparison
As the market wisdom says, price is everything. The customers make their purchase decisions based on price. They base their understanding of the quality of a product on price. In short, price is what drives the customers and, hence, the market.
Therefore, price comparison sites are in great demand. Customers can easily navigate the whole market by looking at the prices of the same product across the brands. These price comparison websites extract the price of the same product from different sites.
Along with price, price comparison websites also scrape data such as the product description, technical specifications, and features. They project the whole gamut of information on a single page in a comparative way.
This answers the question the prospective buyer has asked in their search. Now the prospective buyer can compare the products and their prices, along with information such as features, payment, and shipping options, so that they can identify the best possible deal available.
Pricing optimization has its impact on the business in the sense that such techniques can enhance profit margins by 10%.
E-commerce is all about competitive pricing, and it has spread to other business domains as well. Take the case of travel. Now even travel-related websites scrape the price from airline websites in real time to provide the price comparison of different airlines.
The only challenge in this is to update the data in real time and stay up to date every second as prices keep changing on the source sites. Price comparison sites use Cron jobs or at the view time to update the price. However, it will rest upon the configuration of the site owner.
This is where this blog can help you — you will be able to work out a scraping script that you can customize to suit your needs. You will be able to extract product feeds, images, price, and all other relevant details regarding a product from a number of different websites. With this, you can create your powerful database for price comparison site.
2. Web scraping in R
Price comparison becomes cumbersome because getting web data is not that easy — there are technologies like HTML, XML, and JSON to distribute the content.
So, in order to get the data you need, you must effectively navigate through these different technologies. R can help you access data stored in these technologies. However, it requires a bit of in-depth understanding of R before you get started.
What is R?
Web scraping is an advanced task that not many people perform. Web scraping with R is, certainly, technical and advanced programming. An adequate understanding of R is essential for web scraping in this way.
To start with, R is a language for statistical computing and graphics. Statisticians and data miners use R a lot due to its evolving statistical software, and its focus on data analysis.
One reason R is such a favorite among this set of people is the quality of plots which can be worked out, including mathematical symbols and formulae wherever required.
R is wonderful because it offers a vast variety of functions and packages that can handle data mining tasks.
rvest, RCrawler etc are R packages used for data collection processes.
In this segment, we will see what kinds of tools are required to work with R to carry out web scraping. We will see it through the use case of Amazon website from where we will try to get the product data and store it in JSON form.
Requirements
In this use case, knowledge of R is essential and I am assuming that you have a basic understanding of R. You should be aware of at least any one R interface, such as RStudio. The base R installation interface is fine.
If you are not aware of R and the other associated interfaces, you should go through this tutorial.
Now let’s understand how the packages we’re going to use will be installed.
Packages:
1. rvest
Hadley Wickham authored the rvest package for web scraping in R. rvest is useful in extracting the information you need from web pages.
Along with this, you also need to install the selectr and ‘xml2’ packages.
Installation steps:
install.packages(‘selectr’)
install.packages(‘xml2’)
install.packages(‘rvest’)
rvest contains the basic web scraping functions, which are quite effective. Using the following functions, we will try to extract the data from web sites.
read_html(url): scrape HTML content from a given URLhtml_nodes(): identifies HTML wrappers.html_nodes(“.class”): calls node based on CSS classhtml_nodes(“#id”): calls node based onidhtml_nodes(xpath=”xpath”): calls node based on xpath (we’ll cover this later)html_attrs(): identifies attributes (useful for debugging)html_table(): turns HTML tables into data frameshtml_text(): strips the HTML tags and extracts only the text
2. stringr
stringr comes into play when you think of tasks related to data cleaning and preparation.
There are four essential sets of functions in stringr:
- stringr functions are useful because they enable you to work around the individual characters within the strings in character vectors
- there are whitespace tools which can be used to add, remove, and manipulate whitespace
- there are locale sensitive operations whose operations will differ from locale to locale
- there are pattern matching functions. These functions recognize four parts of pattern description. Regular expressions are the standard one but there are other tools as well
Installation
install.packages(‘stringr’)
3. jsonlite
What makes the jsonline package useful is that it is a JSON parser/generator which is optimized for the web.
It is vital because it enables an effective mapping between JSON data and the crucial R data types. Using this, we are able to convert between R objects and JSON without loss of type or information, and without the need for any manual data wrangling.
This works really well for interacting with web APIs, or if you want to create ways through which data can travel in and out of R using JSON.
Installation
install.packages(‘jsonlite’)
Before we jump-start into it, let’s see how it works:
It should be clear at the outset that each website is different, because the coding that goes into a website is different.
Web scraping is the technique of identifying and using these patterns of coding to extract the data you need. Your browser makes the website available to you from HTML. Web scraping is simply about parsing the HTML made available to you from your browser.
Web scraping has a set process that works like this, generally:
- Access a page from R
- Instruct R where to “look” on the page
- Convert data in a usable format within R using the rvest package
Now let’s go to implementation to understand it better.
3. Implementation
Let’s implement it and see how it works. We will scrape the Amazon website for the price comparison of a product called “One Plus 6”, a mobile phone.
You can see it here.
Step 1: Loading the packages we need
We need to be in the console, at R command prompt to start the process. Once we are there, we need to load the packages required as shown below:
#loading the package:> library(xml2)> library(rvest)> library(stringr)
Step 2: Reading the HTML content from Amazon
#Specifying the url for desired website to be scrappedurl <- ‘https://www.amazon.in/OnePlus-Mirror-Black-64GB-Memory/dp/B0756Z43QS?tag=googinhydr18418-21&tag=googinkenshoo-21&ascsubtag=aee9a916-6acd-4409-92ca-3bdbeb549f80’
#Reading the html content from Amazonwebpage <- read_html(url)
In this code, we read the HTML content from the given URL, and assign that HTML into the webpage variable.
Step 3: Scrape product details from Amazon
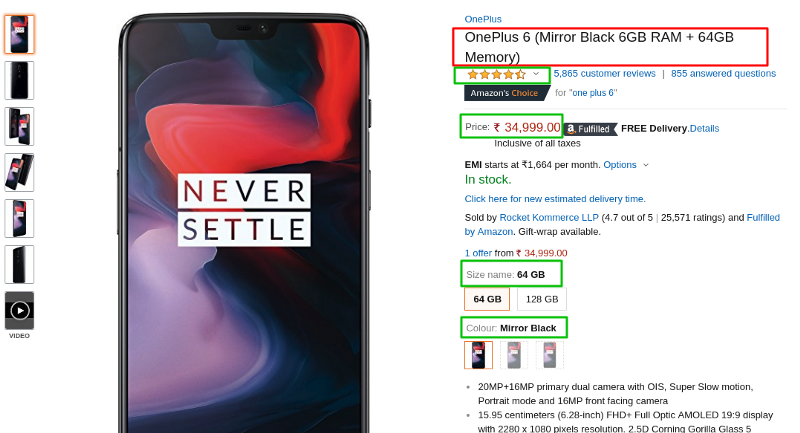
Now, as the next step, we will extract the following information from the website:
Title: The title of the product.
Price: The price of the product.
Description: The description of the product.
Rating: The user rating of the product.
Size: The size of the product.
Color: The color of the product.
This screenshot shows how these fields are arranged.
Next, we will make use of HTML tags, like the title of the product and price, for extracting data using Inspect Element.
In order to find out the class of the HTML tag, use the following steps:
=> go to chrome browser => go to this URL => right click => inspect element
NOTE: If you are not using the Chrome browser, check out this article.
Based on CSS selectors such as class and id, we will scrape the data from the HTML. To find the CSS class for the product title, we need to right-click on title and select “Inspect” or “Inspect Element”.
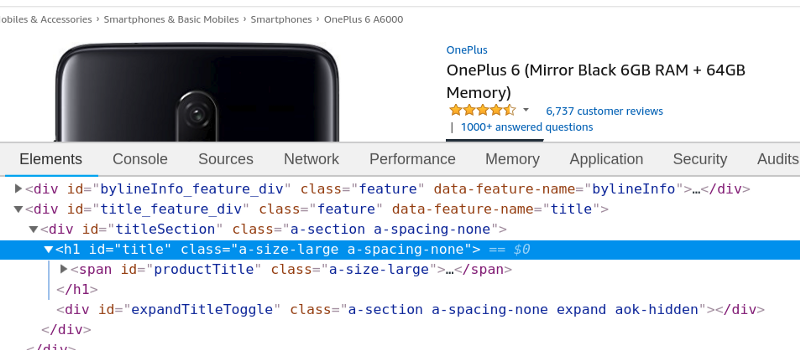
As you can see below, I extracted the title of the product with the help of html_nodes in which I passed the id of the title — h1#title — and webpage which had stored HTML content.
I could also get the title text using html_text and print the text of the title with the help of the head () function.
#scrape title of the product> title_html <- html_nodes(webpage, ‘h1#title’)> title <- html_text(title_html)> head(title)
The output is shown below:

We could get the title of the product using spaces and \n.
The next step would be to remove spaces and new line with the help of the str_replace_all() function in the stringr library.
# remove all space and new linesstr_replace_all(title, “[\r\n]” , “”)
Output:
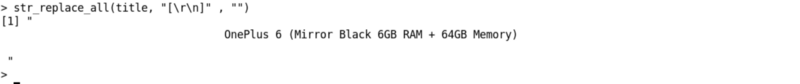
Now we will need to extract the other related information of the product following the same process.
Price of the product:
# scrape the price of the product> price_html <- html_nodes(webpage, ‘span#priceblock_ourprice’)> price <- html_text(price_html)
# remove spaces and new line> str_replace_all(title, “[\r\n]” , “”)
# print price value> head(price)
Output:

Product description:
# scrape product description> desc_html <- html_nodes(webpage, ‘div#productDescription’)> desc <- html_text(desc_html)
# replace new lines and spaces> desc <- str_replace_all(desc, “[\r\n\t]” , “”)> desc <- str_trim(desc)> head(desc)
Output:

Rating of the product:
# scrape product rating > rate_html <- html_nodes(webpage, ‘span#acrPopover’)> rate <- html_text(rate_html)
# remove spaces and newlines and tabs > rate <- str_replace_all(rate, “[\r\n]” , “”)> rate <- str_trim(rate)
# print rating of the product> head(rate)
Output:
Size of the product:
# Scrape size of the product> size_html <- html_nodes(webpage, ‘div#variation_size_name’)> size_html <- html_nodes(size_html, ‘span.selection’)> size <- html_text(size_html)
# remove tab from text> size <- str_trim(size)
# Print product size> head(size)
Output:
Color of the product:
# Scrape product color> color_html <- html_nodes(webpage, ‘div#variation_color_name’)> color_html <- html_nodes(color_html, ‘span.selection’)> color <- html_text(color_html)
# remove tabs from text> color <- str_trim(color)
# print product color> head(color)
Output:
Step 4: We have successfully extracted data from all the fields which can be used to compare the product information from another site.
Let’s compile and combine them to work out a dataframe and inspect its structure.
#Combining all the lists to form a data frameproduct_data <- data.frame(Title = title, Price = price,Description = desc, Rating = rate, Size = size, Color = color)
#Structure of the data framestr(product_data)
Output:

In this output we can see all the scraped data in the data frames.
Step 5: Store data in JSON format:
As the data is collected, we can carry out different tasks on it such as compare, analyze, and arrive at business insights about it. Based on this data, we can think of training machine learning models over this.
Data would be stored in JSON format for further process.
Follow the given code and get the JSON result.
# Include ‘jsonlite’ library to convert in JSON form.> library(jsonlite)
# convert dataframe into JSON format> json_data <- toJSON(product_data)
# print output> cat(json_data)
In the code above, I have included jsonlite library for using the toJSON() function to convert the dataframe object into JSON form.
At the end of the process, we have stored data in JSON format and printed it.
It is possible to store data in a csv file also or in the database for further processing, if we wish.
Output:

Following this practical example, you can also extract the relevant data for the same from product from https://www.oneplus.in/6 and compare with Amazon to work out the fair value of the product. In the same way, you can use the data to compare it with other websites.
4. End note
As you can see, R can give you great leverage in scraping data from different websites. With this practical illustration of how R can be used, you can now explore it on your own and extract product data from Amazon or any other e-commerce website.
A word of caution for you: certain websites have anti-scraping policies. If you overdo it, you will be blocked and you will begin to see captchas instead of product details. Of course, you can also learn to work your way around the captchas using different services available. However, you do need to understand the legality of scraping data and whatever you are doing with the scraped data.
Feel free to send to me your feedback and suggestions regarding this post!