
By Zaid Humayun
Concurrency is a programming term you'll need to be familiar with if you code in C++. It's especially relevant if you want to get more out of your available compute resources.
But concurrency comes with certain problems. Some of them can be solved using mutexes, although mutexes have their own set of challenges.
This is where atomics come in. However, atomics require an understanding of the memory model of a computer, which is a challenging topic to fully grasp.
This is what we'll cover in this article. Hopefully you'll gain a good understanding of how memory ordering works and how to use atomics in conjunction with memory ordering to build a lock-free queue in C++.
Pre-requisites
To get the most out of this guide, you need to have written some basic concurrent programs. Programming experience with C++ helps.
Note: If you want to actually compile the code and run it, make sure to do so with the TSan flag enabled for the CLang compiler. TSan is a reliable way of detecting data races in your code, instead of trying to repeatedly run the code in a loop hoping for a data race to occur.
Getting Started
Imagine you have some concurrent code operating on some shared data in memory. You have two threads or processes, one writing and one reading on some shared piece of state.
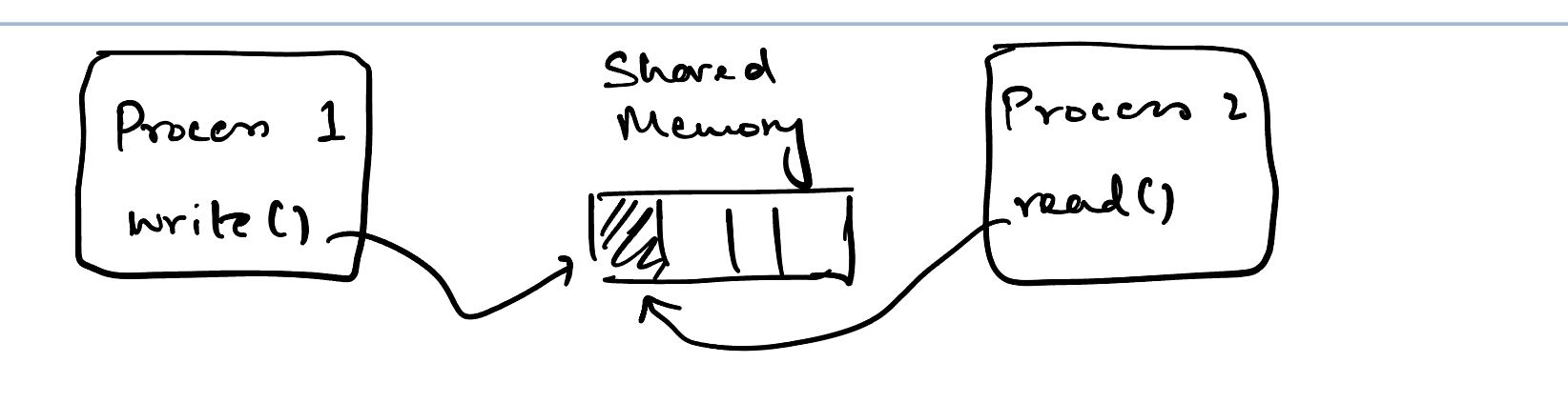 Processes sharing memory
Processes sharing memory
The "safe" way of dealing with this is mutexes. But mutexes tend to add overhead. Atomics are a more performant but much more complicated way of dealing with concurrent operations.
What Are Atomics in C++?
This section is very simple. Atomics are simply operations or instructions that cannot be split by the compiler or the CPU or re-ordered in any way.
The simplest possible example of an atomic in C++ is an atomic flag. It looks like this:
#include <atomic>
std::atomic<bool> flag(false);
int main() {
flag.store(true);
assert(flag.load() == true);
}
We define an atomic boolean, initialise it, and then call store on it. This method sets the value on the flag. You can then load the flag from memory and assert its value.
Operations with Atomics
The operations you can perform with atomics are straightforward:
- You can store some value into them with the
store()method. This is a write operation. - You can load some value from them with the
load()method. This is a read operation. - You can do a Compare-and-Set (CAS) with them using the
compare_exchange_weak()orcompare_exchange_strong()method. This is a read-modify-write (RMW) operation.
The important thing to remember is that each of these cannot be split into separate instructions.
Note: There are more methods available, but this is all we need for now.
There are various atomics available in C++ and you can use them in combination with memory orderings.
Memory Ordering
This section is a lot more complicated and is the meat of the matter. There are some great references to help you understand memory ordering in more depth that I've linked at the bottom.
Why Memory Ordering Matters
The compiler and CPU are capable of re-ordering your program instructions, often independently of one another. That is, your compiler can re-order instructions and your CPU can re-order instructions again. See this post for more detail.
But this is only allowed if the compiler can definitely not establish a relationship between the two sets of instructions.
For instance, the below code can be re-ordered because there is no relationship between the assignment to x and the assignment to y. That is, the compiler or CPU might assign y first and then x. But, this doesn't change the semantic meaning of your program.
int x = 10;
int y = 5;
On the other hand, the following code example cannot be re-ordered because the compiler cannot establish the absence of a relationship between x and y. It's pretty easy to see here because y depends on the value of x.
int x = 10;
int y = x + 1;
This doesn't seem like a big problem – until there's multi-threaded code. Let's see what I mean with an example.
Intuition for Ordering
#include <cassert>
#include <thread>
int data = 0;
void producer() {
data = 100; // Write data
}
void consumer() {
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
The multi-threaded example above will fail to compile with TSan because there is a clear data race when thread 1 is trying to set the value of data and thread 2 is trying to read the value of data. The easy answer here is a mutex to protect the write and read of data, but there's a way to do this with an atomic boolean.
We loop on the atomic boolean until we find that it is set to the value we are looking for and then check the the value of data.
#include <atomic>
#include <cassert>
#include <thread>
int data = 0;
std::atomic<bool> ready(false);
void producer() {
data = 100;
ready.store(true); // Set flag
}
void consumer() {
while (!ready.load())
;
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
When you compile this with TSan, it doesn't complain about any race conditions. Note: I'm going to refer back to why TSan doesn't complain here a little further on.
Now, I'm going to break it by adding a memory ordering guarantee to it. Just replace ready.store(true); with ready.store(true, std::memory_order_relaxed); and replace while (!ready.load()) with while (!ready.load(std::memory_order_relaxed)).
TSan will complain that there is a data race. But, why is it complaining?
The issue here is that we have no order among the operations of the two threads anymore. The compiler or CPU is free to re-order instructions in the two threads. If we go back to our abstract visualisation from earlier, this is what it looks like now:
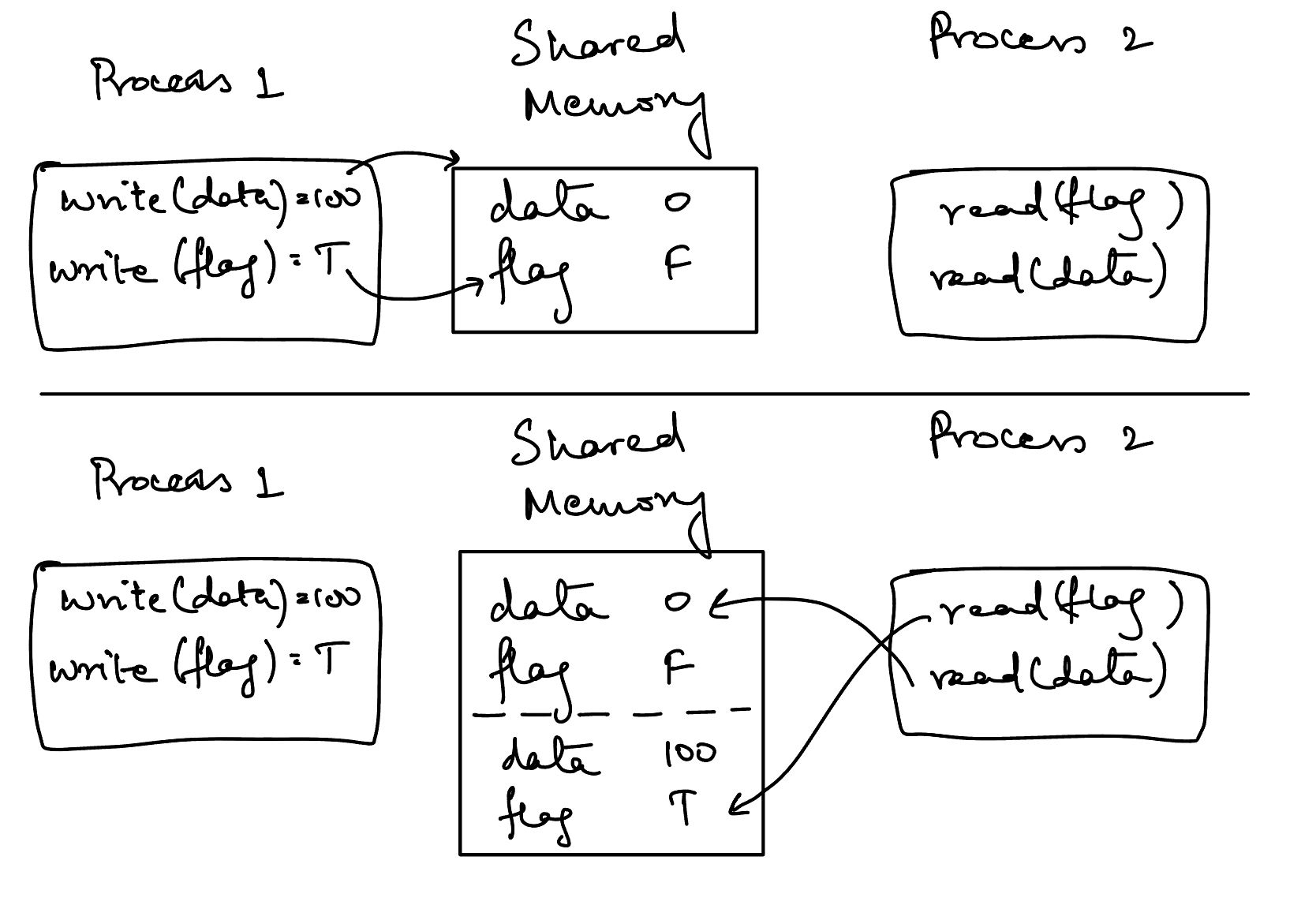 Relaxed memory model ordering
Relaxed memory model ordering
The visualisation above shows us that our two processes (threads) have no way of agreeing upon the current state or the order in which that state has changed.
Once process 2 determines that the flag has been set to true, so it tries to read the value of data. But, thread 2 believes that the value of data has not yet changed even though it believes the value of flag has been set to true.
This is confusing because the classic model of interleaving concurrent operations doesn't apply here. In the classic model of concurrent operations, there is always some order that can be established. For instance, we can say that this is one possible scenario of operations:
Thread 1 Memory Thread 2
--------- ------- ---------
| | |
| write(data, 100) | |
| -----------------------> | |
| | load(ready) == true |
| | <---------------------- |
| | |
| store(ready, true) | |
| -----------------------> | |
| | |
| | read(data) |
| | <---------------------- |
| | |
But, the above graphic assumes that both threads have agreed upon some global order of events, which isn't true at all anymore! This is still confusing for me to wrap my head around.
In a memory_order_relaxed mode, two threads have no way of agreeing upon the order of operations on shared variables. From thread 1's point of view, the operations it executed were the following:
write(data, 100)
store(ready, true)
However, from thread 2's point of view, the order of operations it saw thread 1 execute were:
store(ready, true)
write(data, 100)
Without agreeing upon the order in which operations occurred on shared variables, it isn't safe to make changes to those variables across threads.
Okay, let's fix the code by replacing std::memory_order_relax with std::memory_order_seq_cst.
So, ready.store(true, std::memory_order_relaxed); becomes ready.store(true, std::memory_order_seq_cst); and while (!ready.load(std::memory_order_relaxed)) becomes while (!ready.load(std::memory_order_seq_cst)).
If you run this again with TSan, there are no more data races. But why did that fix it?
Memory Barrier
So, we saw our problem earlier was about two threads being unable to agree upon a single view of events and we wanted to prevent that. So, we introduced a barrier using sequential consistency.
Thread 1 Memory Thread 2
--------- ------- ---------
| | |
| write(data, 100) | |
| -----------------------> | |
| | |
| ================Memory Barrier=================== |
| store(ready, true) | |
| -----------------------> | |
| | load(ready) == true |
| | <---------------------- |
| ================Memory Barrier=================== |
| | |
| | read(data) |
| | <---------------------- |
| | |
The memory barrier here says that nothing before the store operation and nothing after the load operation can be re-ordered. That is, thread 2 now has a guarantee that the compiler or the CPU will not place the write to data after the write to the flag in thread 1. Similarly, the read operation in thread 2 cannot be re-ordered above the memory barrier.
The region inside the memory barrier is akin to a critical section that a thread needs to a mutex to enter. We now have a way to synchronise the two threads on the order of events across them.
This brings us back to our classic model of interleaving in concurrency because we now have an order of events both threads agree upon.
Types Of Memory Order
There are 3 main types of memory order:
- Relaxed memory model (std::memory_order_relaxed)
- Release-acquire memory model (std::memory_order_release and std::memory_order_acquire)
- Sequentially consistent memory order (std::memory_order_seq_cst)
We already covered 1 and 3 in the examples above. The second memory model literally lies between the other two in terms of consistency.
#include <atomic>
#include <cassert>
#include <iostream>
#include <thread>
int data = 0;
std::atomic<bool> ready(false);
void producer() {
data = 100;
ready.store(true, std::memory_order_release); // Set flag
}
void consumer() {
while (!ready.load(std::memory_order_acquire))
;
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
The above is the same example from earlier, expect with std::memory_order_release used for ready.store() and memory_order_acquire used for read.load(). The intuition here for ordering is similar to the pervious memory barrier example.
Except, this time the memory barrier is formed on the pair of ready.store() and ready.load() operations and will only work when used on the same atomic variable across threads.
Assuming you have a variable x being modified across 2 threads, you could do x.store(std::memory_order_release) in thread 1 and x.load(std::memory_order_acquire) in thread 2 and you would have a synchronization point across the two threads on this variable.
The difference between the sequentially consistent model and the release-acquire model is that the former enforces a global order of operations across all threads, while the latter enforces an order only among pairs of release and acquire operations.
Now, we can revisit why TSan didn't complain about a data race initially when there was no memory order specified. It's because C++ by default assumes a std::memory_order_seq_cst when no memory order is specified. Since this is the strongest memory mode, there is no data race possible.
Hardware Considerations
Different memory models have different performance penalties on different hardware.
For instance, the x86 architectures instruction set implements something called total store ordering (TSO). The gist of it is that the model resembles all threads reading and writing to a shared memory. You can read more about that here.
This means that the x86 processors can provide sequential consistency for a relatively low computational penalty.
On the other side are the ARM family of processors has a weakly ordered instruction set architecture. This is because each thread or process reads and writes to its own memory. Again, the link above provides context.
This means that the ARM processors provide sequential consistency for a much higher computational penalty.
How to Build a Concurrent Queue
I'm going to use the operations we have discussed so far to build the basic operations of a lock-free concurrent queue. This is by no means even a complete implementation, just my attempt to re-create something basic using atomics.
I'm going to represent the queue using a linked list and wrap each node inside an atomic.
class lock_free_queue {
private:
struct node {
std::shared_ptr<T> data;
std::atomic<node*> next;
node() : next(nullptr) {} // initialise the node
};
std::atomic<node*> head;
std::atomic<node*> tail;
}
Now, for the enqueue operation, this is what it's going to look like:
void enqueue(T value) {
std::shared_ptr<T> new_data = std::make_shared<T>(value);
node* new_node = new node();
new_node->data = new_data;
// do an infinite loop to change the tail
while (true) {
node* current_tail = this->tail.load(std::memory_order_acquire);
node* tail_next = current_tail->next;
// everything is correct so far, attempt the swap
if (current_tail->next.compare_exchange_strong(
tail_next, new_node, std::memory_order_release)) {
this->tail = new_node;
break;
}
}
}
The main focus is on the load and compare_exchange_strong operations. The load works with an acquire and the CAS works with a release so that reads and writes to the tail are synchronized.
Similarly for the dequeue operation:
std::shared_ptr<T> dequeue() {
std::shared_ptr<T> return_value = nullptr;
// do an infinite loop to change the head
while (true) {
node* current_head = this->head.load(std::memory_order_acquire);
node* next_node = current_head->next;
if (this->head.compare_exchange_strong(current_head, next_node,
std::memory_order_release)) {
return_value.swap(next_node->data);
delete current_head;
break;
}
}
return return_value;
}
Note: This queue doesn’t handle the ABA problem. It's out of the scope of this tutorial to bring in hazard pointers, so I’m leaving that out – but you can look into them if you're curious.
Conclusion
So there you have it – atomics in C++. They're difficult to reason about but give you massive performance benefits. If you want to see production grade implementations of lock-free data structures, you can read more here.
Typically, you'd see lock-based concurrent data structures put into production, but there is increasing research around the area of lock-free and wait-free implementations of concurrent algorithms to improve compute efficiency.
If you want to read this and other tutorials, you can visit my website here.