
I’ll assume that, one way or another, you’re already familiar with many of AWS’s core deployment services. That means you now know about:
• EC2 instances and AMIs (Amazon Machine Images), and the “peripheral” tools that support their deployment like security groups and EBS volumes
• Incorporating databases into our applications, both on-instance and through the managed RDS service
• Using S3 buckets to deliver media files through our EC2 applications and for server backup storage
• Controlling access to our AWS resources with IAM (Identity and Access Management)
• Managing growing resource sets by intelligently applying tags, and
• Accessing our resources using either the browser interface or the AWS CLI (Command Line Interface)
All that can be represented by the schematic in figure 1.
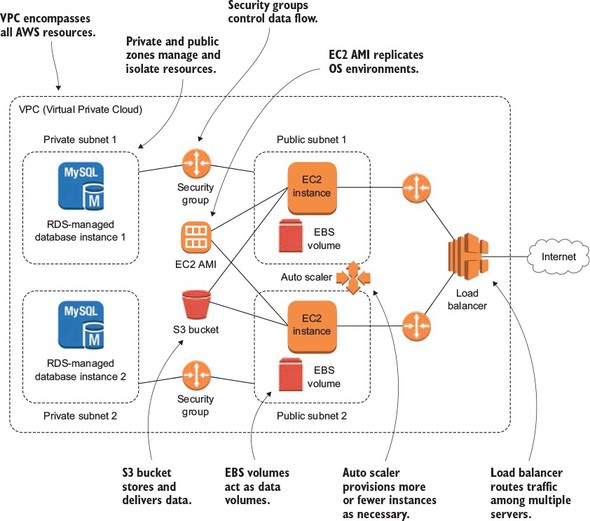
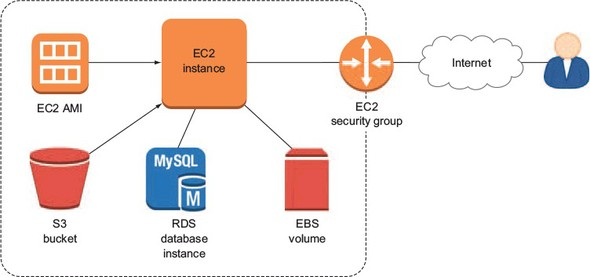 Figure 1. This is the kind of application infrastructure that you should be able to build using the core AWS services.
Figure 1. This is the kind of application infrastructure that you should be able to build using the core AWS services.
Now I’m going to shift the focus just a bit and explore some best-practices for application optimization. Figure 2 can help you visualize how all that infrastructure can be made highly available through the magic of network segmenting, auto scaling, and load balancing.
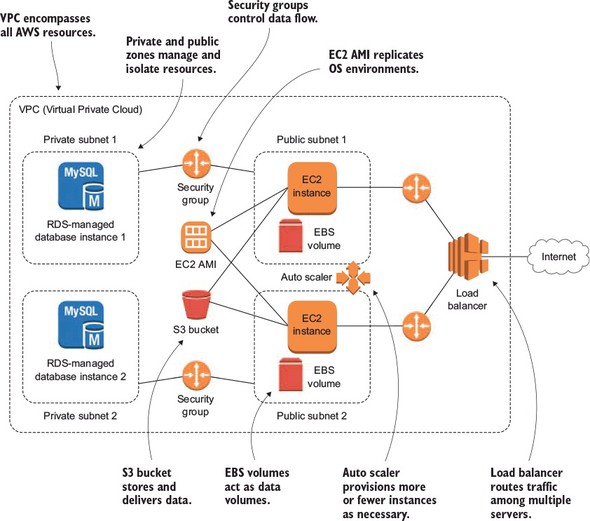 Figure 2. An illustration of how AWS data and security services work together to enable an EC2 instance, so it can deliver its application to customers.
Figure 2. An illustration of how AWS data and security services work together to enable an EC2 instance, so it can deliver its application to customers.
While you probably won’t yet be familiar with many of the tools and relationships represented in the diagram, you should spend a minute making a mental note of at least a few key points, including:
• The Virtual Private Cloud (VPC) that encompasses all the AWS resources in our application deployment
• The two kinds of availability zones: private and public — used to manage and, where needed, isolate resources
• The security groups whose rules control the movement of data between resources
• The EC2 AMI (Amazon Machine Image) that acts as a template for replicating precise operating system environments
• The S3 (Simple Storage Service) bucket that can store and deliver data — both for backup and delivery to users
• The EBS volumes that act as data volumes (like hard drives) for an instance
• The auto scaler that permits automatic provisioning of greater (or fewer) instances to meet changing demands on an application, and
• The load balancer that routes traffic among multiple servers to ensure the smoothest and most efficient user experience
I’m pretty sure you’ve picked up on this already: the “e” in many AWS service names (EC2, ECS, EFS, EMR…) doesn’t stand for “electronic” the way it does in the names of some older technologies like email, but “elastic.” You can, nevertheless, be excused for wondering just what it is about the AWS vision of cloud computing that’s so elastic.
But before I get to answering that question, it might be useful to talk a bit about cloud computing in general. Understanding what makes the cloud unique is probably essential to taking full advantage of all that it has to offer.
Cloud Computing
The US National Institute of Standards and Technology (NIST) defines cloud computing as services that offer their users all of these five qualities:
• On-demand self-service: Customers are able to access public cloud resources whenever needed and without having to order them through a human representative.
• Broad network access: Cloud resources are accessible from any network-connected (i.e., Internet) location.
• Resource pooling: Cloud providers offer a multi-tenant model, whereby individual customers can safely share resources with each other, and dynamic resource assignment, through which resources can be allocated and deallocated according to customer demand.
• Rapid elasticity: Resource availability and performance can be automatically increased or decreased to meet changing customer demand.
• Measured service: Customers are able to consume services at varying levels through a single billing period and be charged only for those resources that they actually use.
These five qualities describe a deeply flexible and highly automated system whose elements can be freely mixed and matched to provide the most efficient and cost-effective service possible. But, a great deal of what makes this possible is the existence of integrated systems that can dynamically adjust themselves based on what’s going on around them. These adjustments are examples of elastic behavior.
Elasticity vs Scalability
So elasticity, as we have established, is a system’s ability to monitor user demand and automatically increase and decrease deployed resources accordingly. Scalability, by contrast, is a system’s ability to monitor user demand and automatically increase and decrease…wait: didn’t I just say that about elasticity?
It’s a bit complicated. In fact, the two terms are sometimes used interchangeably. However I think it’s worthwhile distinguishing between them. Now bear in mind that the way I explain the relationship between these two ideas is by no means the last word on the subject -– look around a bit and you will find some other approaches. But, I think, within the context of understanding how AWS works, my spin should be useful.
What makes an elastic band elastic, is partly its ability to stretch under pressure, but also the way it quickly returns to its original size when the pressure is released. In AWS terms, that would mean the way, for instance, EC2 makes instances available to you when needed, but lets you drop them when they’re not; charging you only for up time. See figure 3.
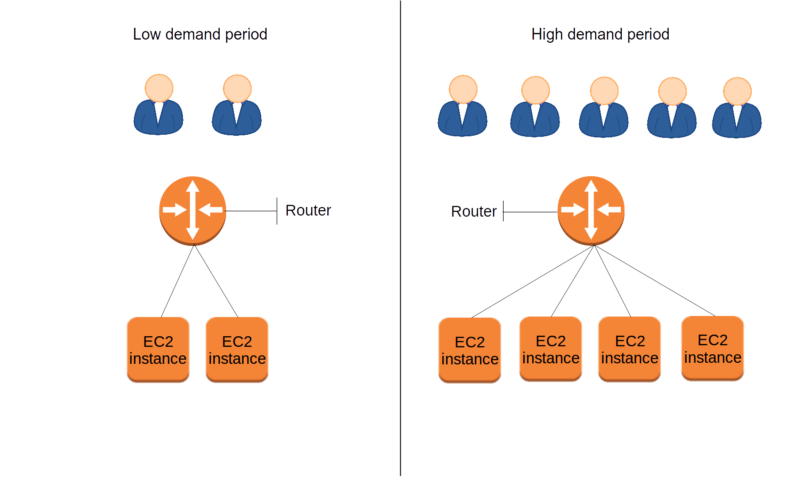 Figure 3. Elasticity allows for systems to dynamically add or remove resources to meet changing demand.
Figure 3. Elasticity allows for systems to dynamically add or remove resources to meet changing demand.
Scalability describes the way a system is designed to meet changing demand. That might include the fact that you’ve got 24-hour access to any resources you might need (which, of course, is an elastic feature), but it also means that the underlying design itself supports rapid and unpredictable changes.
As an example, software that’s scalable can be easily picked up and dropped onto a new server -– possibly within a new network environment -– and just run without any manual configuration. Similarly, as is illustrated in figure 4, the composition of a scalable infrastructure can be quickly changed in a way that all the old bits and pieces immediately know how to work together with the new ones.
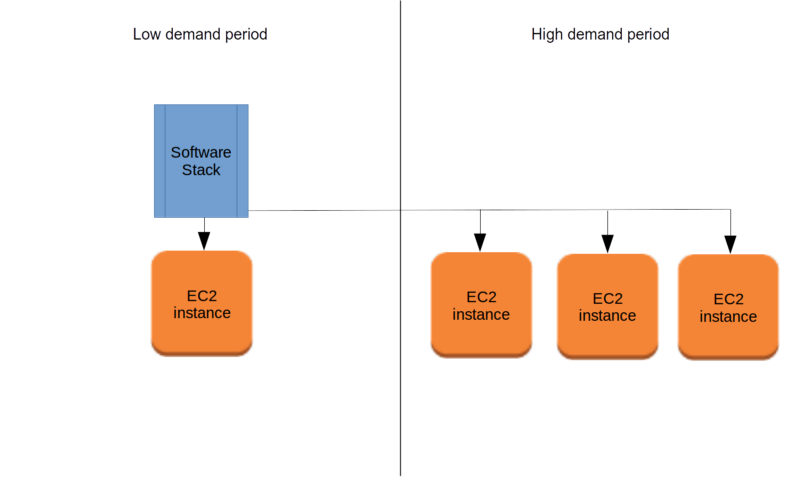 Figure 4. Scalable software can be easily copied for use in multiple servers deployed in multiple network environments.
Figure 4. Scalable software can be easily copied for use in multiple servers deployed in multiple network environments.
With that in mind, we can say that Amazon’s EC2 is not only elastic but, since its elements (instances, storage volumes, security groups, etc.) can be smoothly dropped into and out of running infrastructures, it’s also very scalable. Ah, but what kind of scalable? There are two, you know:
• Horizontal scaling is “scaling out” — where you add more lightweight server nodes (or “instances”) to meet growing demand.
• Vertical scaling is “scaling up” — where you move your application from a single lightweight server to one with greater compute capacity.
It is certainly possible to transfer AWS-based applications from lighter to heavier servers, and for some payloads — like many high-load transaction databases, it’s preferred. But in an AWS context, if you hear some conjugation of the word “scale”, the odds are that it’s referring to horizontal scaling.
Practical applications
Ok. But who cares? Well, as the customer demand on our WordPress site continues to grow, we will, and in a big way. You see, for some reason -– perhaps related to the fact that we discount the price of our product by 75% for just a half an hour each evening -– customers arrive in their greatest numbers in the early evening, local time. So while the single server we’ve been running stands largely unused throughout most of the day, it simply melts under the pressure of thousands of visits squeezed into such a short stretch of time.
And then there’s that question one of the guys in the office asked the other day: “Our entire business is running on a single web server; what happens if it goes down?” What indeed.
We could provision four or five extra servers and run them full time. That way, we’d be covered for the high-volume periods and for the failure of any one server. But it would still involve colossal waste, since for most of each day we’d be paying for most of the instances to sit idle. Nor would it necessarily be much help in the event of a network failure, which would likely cut connectivity to all the servers at the same time.
We could always address at least the customer demand issue by arranging for someone to be at the office every evening to manually fire up as many extra servers as we’ll need. But we asked around, and no one volunteered. And besides, the best way to ensure a daily job won’t get done is to assume that an admin will remember to do it.
Automating High Availability
Alternatively, we could spend some time incorporating high availability capability into our setup and let the whole thing be quietly and efficiently managed by software. This will be the subject of the next few chapters of my book, where we will learn to leverage AWS’s geographically remote availability zones to make total application failure much less likely, use load balancing to coordinate between parallel servers and monitor their health, and auto scaling to let AWS automatically respond to the peaks and valleys of changing demand by launching and shutting down instances according to need.
For more info on Amazon Web Services, download the free first chapter of Learn Amazon Web Service in a Month of Lunches and see this Slideshare presentation. Don’t forget to use code ssclinton to save 42% off your purchase.