By Melody Yang
From constructing a Convolutional Neural Network to deploying an OCR to iOS
The Motivation for the Project ✍️ ??
While I was learning how to create deep learning models for the MNIST dataset a few months ago, I ended up making an iOS app that recognized handwritten characters.
My friend Kaichi Momose was developing a Japanese language learning app, Nukon. He coincidentally wanted to have a similar feature in it. We then collaborated to build something more sophisticated than a digit recognizer: an OCR (Optical Character Recognition/Reader) for Japanese characters (Hiragana and Katakana).
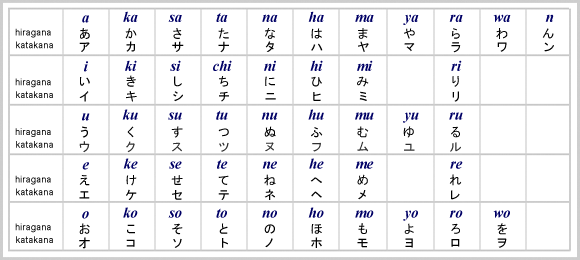 _[Basic Hiragana & Katakana](http://www.kanjipower.com/jws/hiragana.php" rel="noopener" target="blank" title=")
_[Basic Hiragana & Katakana](http://www.kanjipower.com/jws/hiragana.php" rel="noopener" target="blank" title=")
During the development of Nukon, there was no API available for handwriting recognition in Japanese. We had no choice but to build our own OCR. The biggest benefit we got from building one from scratch was that ours works offline. Users can be deep in the mountains without the internet and still open up Nukon to maintain their daily routine of learning Japanese. We learned a lot throughout the process, but more importantly, we were thrilled to ship a better product for our users.
This article will break down the process of how we built a Japanese OCR for iOS apps. For those who would like to build one for other languages/symbols, feel free to customize it by changing the dataset.
Without further ado, let’s take a look at what will be covered:
Part 1️⃣: Obtain the dataset and preprocess images
Part 2️⃣: Build & train the CNN (Convolutional Neural Network)
Part 3️⃣: Integrate the trained model into iOS
 _What the final app could look like (demo comes from [Recogmize](http://bit.ly/recogmize" rel="noopener" target="blank" title="))
_What the final app could look like (demo comes from [Recogmize](http://bit.ly/recogmize" rel="noopener" target="blank" title="))
Obtain the dataset & Preprocess Images ?
The dataset comes from the ETL Character Database, which contains nine sets of images of handwritten characters and symbols. Since we are going to build an OCR for Hiragana, ETL8 is the dataset we will use.
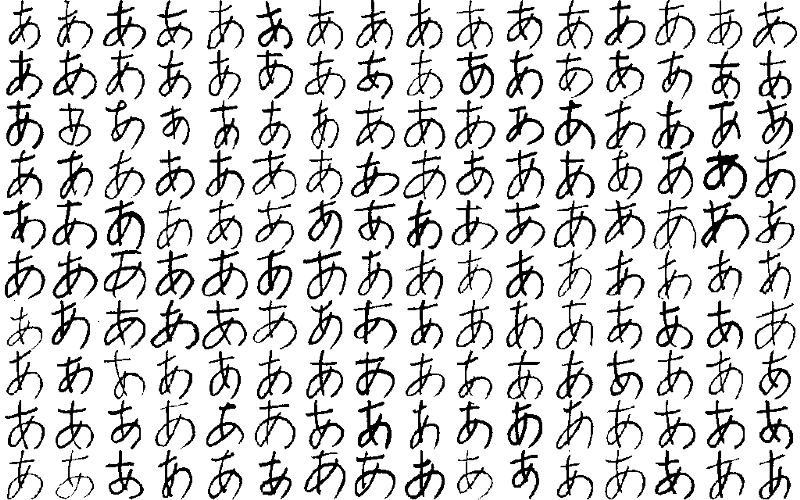 Images of handwritten “あ” produced by 160 writers (from ETL8)
Images of handwritten “あ” produced by 160 writers (from ETL8)
To get the images from the database, we need some helper functions that read and store images in .npz format.
import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
Once we have hiragana.npz saved, let’s start processing images by loading the file and reshaping the image dimensions to 32x32 pixels. We will also add data augmentation to generate extra images that are rotated and zoomed. When our model is trained on character images from a variety of angles, our model can better adapt to people’s handwriting.
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)
Build and Train the CNN ?️
Now comes in the fun part! We will use Keras to construct a CNN (Convolutional Neural Network) for our model. When I first built the model, I experimented with hyper-parameters and tuned them multiple times. The combination below gave me the highest accuracy — 98.77%. Feel free to play around with different parameters yourself.
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))
Here are some tips if you find the performance of the model unsatisfactory in the training step:
Model is overfitting
This means that the model is not well generalized. Check out this article for intuitive explanations.
How to detect overfitting: acc (accuracy) continues to go up, but the val_acc (validation accuracy) does the opposite in the training process.
Some solutions to overfitting: regularization (ex. dropouts), data augmentation, improvement on quality of the dataset
How to know whether the model is “learning”
The model is not learning if val_loss (validation loss) goes up or does not decrease as the training goes on.
Use TensorBoard — it provides visualizations for model performance over time. It gets rid of the tiresome task of looking at every single epoch and comparing values constantly.
As we are satisfied with our accuracy, we remove dropout layers before saving the weights and model configuration as a file.
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
The only task left before moving on to the iOS part is converting hiraganaModel.h5 to a CoreML model.
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
The output_labels are all possible outputs we will see in iOS later.
Fun fact: if you understand Japanese, you may know that the order of the output characters does not match with the “alphabetical order” of Hiragana. It took us some time to realize that images in ETL8 weren’t in “alphabetical order” (thanks to Kaichi for realizing this). The dataset was compiled by a Japanese university, though…?
Integrate the Trained Model Into iOS ?
We are finally putting everything together! Drag and drop hiraganaModel.mlmodel into an Xcode project. Then you will see something like this:
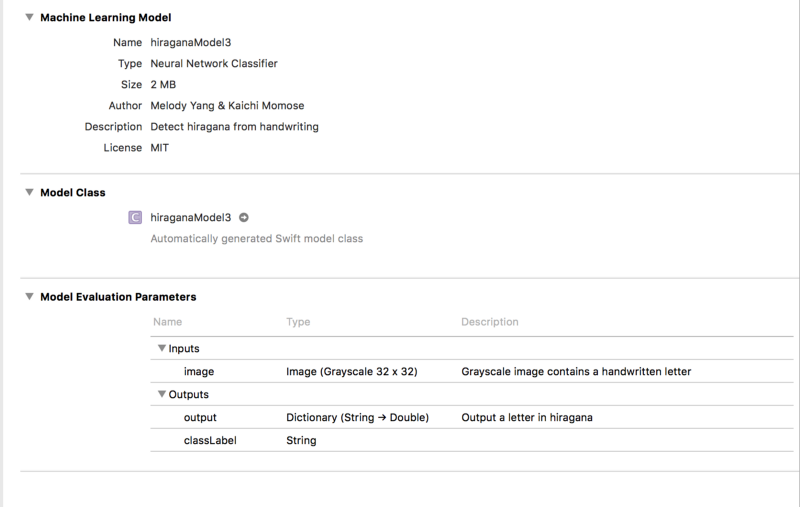 Details of mlmodel in Xcode workspace
Details of mlmodel in Xcode workspace
Note: Xcode will create a workspace upon copying the model. We need to switch our coding environment to the workspace otherwise the ML model won’t work!
The end goal is having our Hiragana model predict a character by passing in an image. To achieve this, we will create a simple UI so the user can write, and we will store the user’s writing in an image format. Lastly, we retrieve the pixel values of the image and feed them to our model.
Let’s do it step by step:
- “Draw” characters on
UIViewwithUIBezierPath
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
The strokeLayer.strokeColor can be any color. However, the background color of canvas must be black. Although our training images have a white background and black strokes, the ML model does not react well to an input image with this style.
- Turn
UIViewintoUIImageand retrieve pixel values with CVPixelBuffer
In the extension, there are two helper functions. Together, they translate images into a pixel buffer, which is equivalent to pixel values. The input width and height should both be 32 since the input dimensions of our model are 32 by 32 pixels.
As soon as we have the pixelBuffer, we can call model.prediction() and pass in pixelBuffer. And there we go! We can have an output of classLabel!
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
- Show the output with
UIAlertController
This step is totally optional. As shown in the GIF at the beginning , I added an alert controller to inform the result.
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}
Voila! We just built an OCR that is demo-ready (and App-Store-ready)! ??
Conclusion ?
Building an OCR is not all that hard. As you saw, this article consists of steps and problems and I ran into while building this project. I enjoyed the process of making a bunch of Python code demonstrable by connecting it with iOS, and I intend to continue doing so.
I hope this article provides some useful information to those who want to build an OCR but have no clue where to start.
You can find the source code here.
Bonus: if you are interested in experimenting with shallow algorithms, then keep on reading!
[Optional] Train With Shallow Algorithms ?
Before implementing CNN, Kaichi and I tested out other machine learning algorithms to figure out if they could get the job done (and save us some computing costs!). We picked KNN and Random Forest.
To evaluate their performances, we defined our baseline accuracy to be 1/71 = 0.014.
We assumed a person without any knowledge of the Japanese language could have a 1.4% chance of guessing a character right.
Thus, the model would be doing well if its accuracy could surpass 1.4%. Let’s see if it was the case. ?
KNN
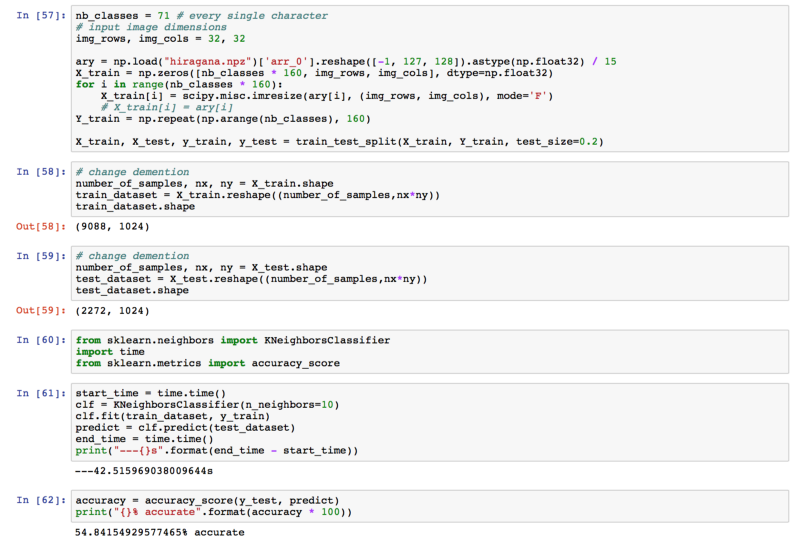 Trained with KNN
Trained with KNN
The final accuracy we got was 54.84%. Much higher than 1.4% already!
Random Forest
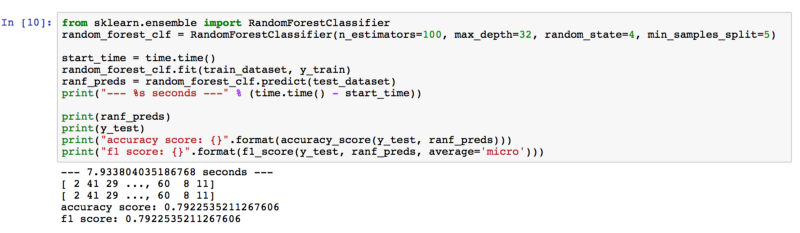 Trained with Random Forest
Trained with Random Forest
An accuracy of 79.23%, so Random Forest exceeded our expectations. While tuning hyper-parameters, we got better results by increasing the number of estimators and depth of trees. We thought that having more trees (estimators) in the forest meant more features in the image were learned. Also, the deeper the tree, the more details it learned from features.
If you are interested in learning more, I found this paper that discusses image classification with Random Forest.
Thank you for reading. Any thoughts and feedback are welcomed!