
By Aditya
Neural Networks are like the workhorses of Deep learning. With enough data and computational power, they can be used to solve most of the problems in deep learning. It is very easy to use a Python or R library to create a neural network and train it on any dataset and get a great accuracy.
We can treat neural networks as just some black box and use them without any difficulty. But even though it seems very easy to go that way, it's much more exciting to learn what lies behind these algorithms and how they work.
In this article we will get into some of the details of building a neural network. I am going to use Python to write code for the network. I will also use Python's numpy library to perform numerical computations. I will try to avoid some complicated mathematical details, but I will refer to some brilliant resources in the end if you want to know more about that.
So let's get started.
Idea
Before we start writing code for our Neural Network, let's just wait and understand what exactly is a Neural Network.
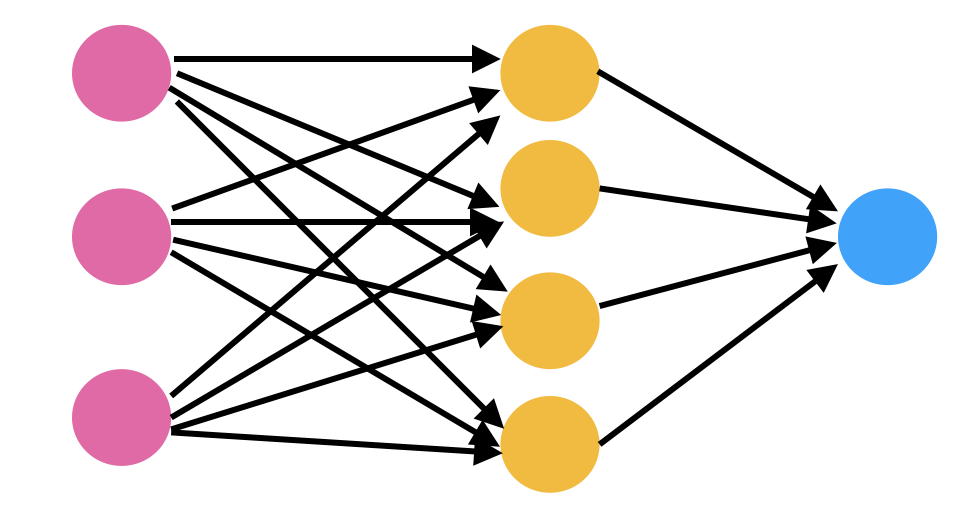 _Source_
_Source_
In the image above you can see a very casual diagram of a neural network. It has some colored circles connected to each other with arrows pointing to a particular direction. These colored circles are sometimes referred to as neurons.
These neurons are nothing but mathematical functions which, when given some input, generate an output. The output of neurons depends on the input and the parameters of the neurons. We can update these parameters to get a desired value out of the network.
Each of these neurons are defined using sigmoid function. A sigmoid function gives an output between zero to one for every input it gets. These sigmoid units are connected to each other to form a neural network.
By connection here we mean that the output of one layer of sigmoid units is given as input to each sigmoid unit of the next layer. In this way our neural network produces an output for any given input. The process continues until we have reached the final layer. The final layer generates its output.
This process of a neural network generating an output for a given input is Forward Propagation. Output of final layer is also called the prediction of the neural network. Later in this article we will discuss how we evaluate the predictions. These evaluations can be used to tell whether our neural network needs improvement or not.
Right after the final layer generates its output, we calculate the cost function. The cost function computes how far our neural network is from making its desired predictions. The value of the cost function shows the difference between the predicted value and the truth value.
Our objective here is to minimize the value of the cost function. The process of minimization of the cost function requires an algorithm which can update the values of the parameters in the network in such a way that the cost function achieves its minimum value.
Algorithms such as gradient descent and stochastic gradient descent are used to update the parameters of the neural network. These algorithms update the values of weights and biases of each layer in the network depending on how it will affect the minimization of cost function. The effect on the minimization of the cost function with respect to each of the weights and biases of each of the input neurons in the network is computed by backpropagation.
Code
So, we now know the main ideas behind the neural networks. Let us start implementing these ideas into code. We will start by importing all the required libraries.
import numpy as np
import matplotlib.pyplot as plt
As I mentioned we are not going to use any of the deep learning libraries. So, we will mostly use numpy for performing mathematical computations efficiently.
The first step in building our neural network will be to initialize the parameters. We need to initialize two parameters for each of the neurons in each layer: 1) Weight and 2) Bias.
These weights and biases are declared in vectorized form. That means that instead of initializing weights and biases for each individual neuron in every single layer, we will create a vector (or a matrix) for weights and another one for biases, for each layer.
These weights and bias vectors will be combined with the input to the layer. Then we will apply the sigmoid function over that combination and send that as the input to the next layer.
layer_dims holds the dimensions of each layer. We will pass these dimensions of layers to the init_parms function which will use them to initialize parameters. These parameters will be stored in a dictionary called params. So in the params dictionary params['W1'] will represent the weight matrix for layer 1.
def init_params(layer_dims):
np.random.seed(3)
params = {}
L = len(layer_dims)
for l in range(1, L):
params['W'+str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1])*0.01
params['b'+str(l)] = np.zeros((layer_dims[l], 1))
return params
Great! We have initialized the weights and biases and now we will define the sigmoid function. It will compute the value of the sigmoid function for any given value of Z and will also store this value as a cache. We will store cache values because we need them for implementing backpropagation. The Z here is the linear hypothesis.
Note that the sigmoid function falls under the class of activation functions in the neural network terminology. The job of an activation function is to shape the output of a neuron.
For example, the sigmoid function takes input with discrete values and gives a value which lies between zero and one. Its purpose is to convert the linear outputs to non-linear outputs. There are different types of activation functions that can be used for better performance but we will stick to sigmoid for the sake of simplicity.
# Z (linear hypothesis) - Z = W*X + b ,
# W - weight matrix, b- bias vector, X- Input
def sigmoid(Z):
A = 1/(1+np.exp(np.dot(-1, Z)))
cache = (Z)
return A, cache
Now, let's start writing code for forward propagation. We have discussed earlier that forward propagation will take the values from the previous layer and give it as input to the next layer. The function below will take the training data and parameters as inputs and will generate output for one layer and then it will feed that output to the next layer and so on.
def forward_prop(X, params):
A = X # input to first layer i.e. training data
caches = []
L = len(params)//2
for l in range(1, L+1):
A_prev = A
# Linear Hypothesis
Z = np.dot(params['W'+str(l)], A_prev) + params['b'+str(l)]
# Storing the linear cache
linear_cache = (A_prev, params['W'+str(l)], params['b'+str(l)])
# Applying sigmoid on linear hypothesis
A, activation_cache = sigmoid(Z)
# storing the both linear and activation cache
cache = (linear_cache, activation_cache)
caches.append(cache)
return A, caches
A_prev _i_s input to the first layer. We will loop through all the layers of the network and will compute the linear hypothesis. After that it will take the value of Z (linear hypothesis) and will give it to the sigmoid activation function. Cache values are stored along the way and are accumulated in caches. Finally, the function will return the value generated and the stored cache.
Let's now define our cost function.
def cost_function(A, Y):
m = Y.shape[1]
cost = (-1/m)*(np.dot(np.log(A), Y.T) + np.dot(log(1-A), 1-Y.T))
return cost
As the value of the cost function decreases, the performance of our model becomes better. The value of the cost function can be minimized by updating the values of the parameters of each of the layers in the neural network. Algorithms such as Gradient Descent are used to update these values in such a way that the cost function is minimized.
Gradient Descent updates the values with the help of some updating terms. These updating terms called gradients are calculated using the backpropagation. Gradient values are calculated for each neuron in the network and it represents the change in the final output with respect to the change in the parameters of that particular neuron.
def one_layer_backward(dA, cache):
linear_cache, activation_cache = cache
Z = activation_cache
dZ = dA*sigmoid(Z)*(1-sigmoid(Z)) # The derivative of the sigmoid function
A_prev, W, b = linear_cache
m = A_prev.shape[1]
dW = (1/m)*np.dot(dZ, A_prev.T)
db = (1/m)*np.sum(dZ, axis=1, keepdims=True)
dA_prev = np.dot(W.T, dZ)
return dA_prev, dW, db
The code above runs the backpropagation step for one single layer. It calculates the gradient values for sigmoid units of one layer using the cache values we stored previously. In the activation cache we have stored the value of Z for that layer. Using this value we will calculate the dZ, which is the derivative of the cost function with respect to the linear output of the given neuron.
Once we have calculated all of that, we can calculate dW, db and dA_prev, which are the derivatives of cost function with respect the weights, biases and previous activation respectively. I have directly used the formulae in the code. If you are not familiar with calculus then it might seem too complicated at first. But for now think about it as any other math formula.
After that we will use this code to implement backpropagation for the entire neural network. The function backprop implements the code for that. Here, we have created a dictionary for mapping gradients to each layer. We will loop through the model in a backwards direction and compute the gradient.
def backprop(AL, Y, caches):
grads = {}
L = len(caches)
m = AL.shape[1]
Y = Y.reshape(AL.shape)
dAL = -(np.divide(Y, AL) - np.divide(1-Y, 1-AL))
current_cache = caches[L-1]
grads['dA'+str(L-1)], grads['dW'+str(L-1)], grads['db'+str(L-1)] = one_layer_backward(dAL, current_cache)
for l in reversed(range(L-1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = one_layer_backward(grads["dA" + str(l+1)], current_cache)
grads["dA" + str(l)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
Once, we have looped through all the layers and computed the gradients, we will store those values in the grads dictionary and return it.
Finally, using these gradient values we will update the parameters for each layer. The function update_parameters goes through all the layers and updates the parameters and returns them.
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2
for l in range(L):
parameters['W'+str(l+1)] = parameters['W'+str(l+1)] -learning_rate*grads['W'+str(l+1)]
parameters['b'+str(l+1)] = parameters['b'+str(l+1)] - learning_rate*grads['b'+str(l+1)]
return parameters
Finally, it's time to put it all together. We will create a function called train for training our neural network.
def train(X, Y, layer_dims, epochs, lr):
params = init_params(layer_dims)
cost_history = []
for i in range(epochs):
Y_hat, caches = forward_prop(X, params)
cost = cost_function(Y_hat, Y)
cost_history.append(cost)
grads = backprop(Y_hat, Y, caches)
params = update_parameters(params, grads, lr)
return params, cost_history
This function will go through all the functions step by step for a given number of epochs. After finishing that, it will return the final updated parameters and the cost history. Cost history can be used to evaluate the performance of your network architecture.
Conclusion
If you are still reading this, Thanks! This article was a little complicated, so what I suggest you to do is to try playing around with the code. You might get some more insights out of it and maybe you might find some errors in the code too. If that is the case or if you have some questions or both, feel free to hit me up on twitter. I will do my best to help you.
Resources
- Neural Networks Playlist - by 3Blue1Brown
- Neural Networks and Deep Learning - by Michael A. Nielsen
- Gradient Descent and Stochastic Gradient Descent