By Chinwendu Enyinna
When you’re building the backend of an application, you’ve got to figure out how all the different components are going to talk to each other.
It’s like setting up a communication network for your app’s brain, and the way you do it can seriously impact how well your app performs.
But here’s the fun part: there’s no one-size-fits-all answer. The communication pattern you choose depends on what your application needs to do.
So, in this tutorial, we’re going to take a look at five different ways backend systems like to chat it up. We’ll explore what they’re good at and when you should invite them to the conversation. Let’s dive right in!
What is a Design Pattern?
Before we get into all the cool patterns, let’s talk about what a design pattern is, shall we?
Design patterns are nifty, tried-and-true reusable solutions to common problems encountered during software design and development. You can call them the cheat codes of software design and development.
They can help provide a structured approach to solving recurring challenges, offering a set of guidelines and best practices that can be adapted for various scenarios.
Now that we’ve got that down, let’s explore five of these emerging design patterns used for backend communication.
Request-Response Pattern
The request-response pattern is a fundamental building block for how the front-end and back-end of web applications chat with each other. This pattern is like a conversation between the client (say your browser) and the server, where they take turns speaking. Imagine it as a “ping-pong” of data.
Here's a diagram illustrating what that looks like:
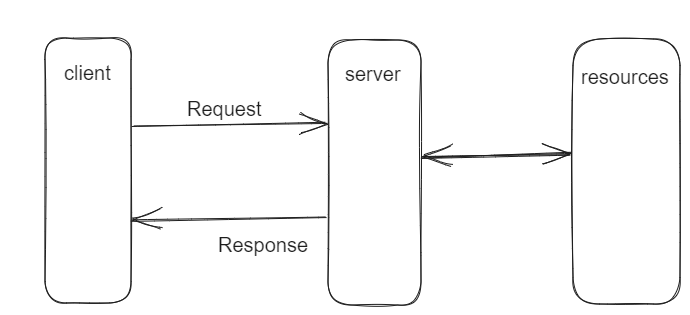 request/response communication model
request/response communication model
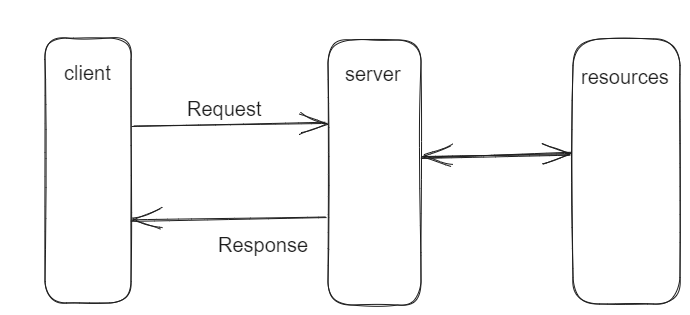
How does the Request-Response pattern work?
This pattern is all about synchronization. The client sends a request to the server, kind of like raising your hand to ask a question in class. Then it patiently waits for the server to respond before it can move on.
It’s like a polite conversation — one speaks, the other listens, and then they swap roles.
You’ve probably heard of RESTful APIs, right? Well, they’re a prime example of the request-response model in action.
When your app needs some data or wants to do something on the server, it crafts an HTTP request — say GET, POST, PUT, or DELETE (like asking nicely for a page), and sends it to specific endpoints (URLs) on the server. The server then processes your request and replies with the data you need or performs the requested action.
It’s like ordering your favorite dish from a menu — you ask, and the kitchen (server) cooks it up for you.
Interestingly, there’s more than one way to have this conversation. Besides REST, there’s GraphQL, an alternative that lets you ask for exactly the data you want. It’s like customizing your order at a restaurant — you get to pick and choose your ingredients.
It’s important to note that this pattern isn’t just limited to web applications. You’ll spot it in Remote Procedure Calls (RPCs), database queries (with the server being the client and the database, the server), and network protocols (HTTP, SMTP, FTP) to name a few. It’s like the language of communication for the web.
Benefits of the Request-Response pattern
Ease of Implementation and Simplicity: The way communication flows in this model is pretty straightforward, making it a go-to choice for many developers, especially when they’re building apps with basic interaction needs.
Flexibility and Adaptability (One Size Fits Many): The request-response pattern seamlessly fits into a wide range of contexts. You can use it for making API calls, rendering web pages on the server, fetching data from databases, and more.
Scalability: Each request from the client is handled individually, so the server can easily manage multiple requests at once. This is highly beneficial for high-traffic websites, APIs that get tons of calls, or cloud-based services.
Reliability: Since the server always sends back a response, the client can be sure its request is received and processed. This helps maintain data consistency and ensures that actions have been executed as intended even during high-traffic scenarios.
Ease of Debugging: If something goes wrong, the server kindly sends an error message with a status code stating what happened. This makes error handling easy.
Limitations of the Request-Response Pattern
Latency Problem: Because it’s a back-and-forth conversation, there’s often a waiting period. This amounts to idle periods and amplifies latency, especially when the request requires the server to perform time-consuming computing tasks.
Data Inconsistency in Case of Failures: If a failure occurs after the server has processed the request but before the response is delivered to the client, data inconsistency may result.
Complexity in Real-Time Communication: For applications that need lightning-fast real-time communication (like live streaming, gaming, or chat apps), this pattern can introduce delays and is therefore unsuitable for these use-cases.
Inefficiency in Broadcasting: In scenarios where you need to send the same data to multiple clients at once (broadcast), this pattern can be a bit inefficient. It’s like mailing individual letters instead of sending one group message.
Here’s a code example that shows the request-response pattern using Nodejs.
First, we have the server.js file. Here we’ve set up the server to listen for incoming requests from the client.
const http = require("http");
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader("Content-Type", "text/plain");
//check request method and receive data from client
if (req.method === "POST") {
let incomingMessage = "";
req.on("data", (chunk) => {
incomingMessage += chunk;
});
//write back message received from the client on the console
req.on("end", () => {
console.log(`Message from client: ${incomingMessage}`);
res.end(`Hello client, message received!`);
});
} else {
res.end("Hey there, Client!\n");
}
});
const PORT = 3030;
server.listen(PORT, () => {
console.log(
`Server is listening for incoming request from client on port:${PORT}`
);
});
And here's the client.js file:
const http = require("http");
const options = {
method: "POST",
hostname: "localhost",
port: 3030,
path: "/",
};
//message to server
let messageToServer = "Hey there, server!";
//send a http request to the server
const req = http.request(options, (res) => {
let incomingData = "";
res.on("data", (chunk) => {
incomingData += chunk;
});
res.on("end", () => {
console.log(`Response from the server: ${incomingData}`);
});
});
req.on("error", (error) => {
console.log(`Error message: ${error.message}`);
});
//send message to the server
req.write(messageToServer);
//end your request
req.end();
Here's the output:
 code output on the terminal
code output on the terminal
The Publish/Subscribe Pattern
Publish/Subscribe is another communication design pattern you may see on the backend. It is used in distributed systems for asynchronous communication between several (usually decoupled) components. It’s perfect for when you’ve got a bunch of components that need to work together but want to keep their distance.
Here's a diagram showing how it works:
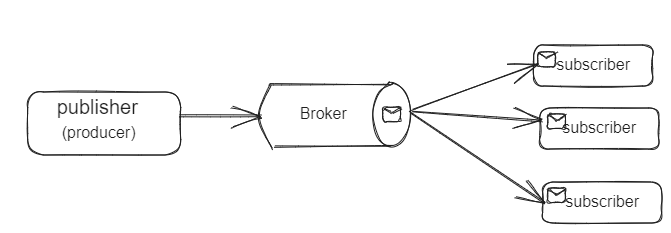 Pub/Sub communication model
Pub/Sub communication model
How does the Publish/Subscribe pattern work?
This pattern involves the use of message queues (often called message brokers) which serve as intermediaries between the publishers and subscribers. These message brokers group messages into something called channels (or topics).
Publishers are the components that create and send messages while subscribers are the components that receive and consume the messages.
The publishers simply toss messages (or events) into specific channels/topics within the message broker. These channels act as the distribution point for the messages. The subscribers then indicate interest by subscribing to those channels within the message broker and whenever a message or event is published to that channel, they receive a copy.
Message queuing tools like Apache Kafka and MQTT use the publish/subscribe communication pattern under the hood.
Benefits of the Publish/Subscribe pattern
Asynchronous Communication: Unlike the request-response model, pub/sub is designed to be asynchronous by nature. This makes it ideal for building real-time applications with reduced latency bottlenecks.
Loose Coupling of Components: The components in a publish/subscribe model are loosely coupled. This means that they are not tied together and can freely interact by triggering and responding to events.
Highly Scalable: There is no limit to the number of subscribers a publisher can publish events to. Also, there’s no limit to the number of publishers subscribers can subscribe to.
Independent of Language and Protocol: The Pub/Sub model can be easily integrated into any tech stack because it is language-agnostic. Also, it often supports a wide range of environments and platforms making it cross-platform compatible.
Load Balancing: In cases where multiple subscribers subscribe to a particular event, the pub/sub model can distribute the events evenly among the subscribers, providing load-balancing capabilities out of the box.
Limitations of the Publish/Subscribe pattern
Complexity in Implementation: Setting up a Pub/Sub system can be more complex than simpler communication models like the request-response pattern. You need to configure and manage message brokers, channels, and subscriptions, which can add overhead to your system.
Message Duplication: Depending on the configuration and network issues, messages can be duplicated. Subscribers might receive the same message more than once, which can lead to redundancy and extra processing.
Scalability Challenges: While Pub/Sub is highly scalable, managing extremely high volumes of messages and subscribers can become complex. You might need to consider how to distribute messages efficiently and handle massive numbers of subscribers.
Complex Error Handling: Dealing with errors in a Pub/Sub system can be challenging. Handling situations like message delivery failures or subscriber errors requires careful consideration and design.
When should you use it?
- In building features that require real-time and low latency responsiveness for the end-users, for example live chat or gaming applications for multiple players.
- In event notification systems
- In building distributed systems that rely on logging and caching
Here’s a code snippet showing a simple pub/sub implementation using the npm package pubsub-js.
Here are the contents of the pubsub.js file:
const PubSub = require("pubsub-js");
/*
create a topic of choice.
Any subscriber that subscribes to this topic
receives the published messages
*/
const TOPIC = "chat";
//a function to publish a messgae to subscribers
function publishMessageToSubscribers(message) {
PubSub.publish(TOPIC, message);
console.log(`Message Published: ${message}`);
}
let subscriber1 = function (msg, data) {
console.log(msg, data);
console.log("subscriber1 received: ", data);
};
let subscriber2 = function (msg, data) {
console.log(msg, data);
console.log("subscriber2 received: ", data);
};
// Subscriber1 subscribes to the topic
PubSub.subscribe(TOPIC, subscriber1);
//subscriber2 subscribes to topic
PubSub.subscribe(TOPIC, subscriber2);
publishMessageToSubscribers("Hello subscriber!");
console.log("Subscriber 1 is listening....");
console.log("Subscriber 2 is listening....");
Here's the output:
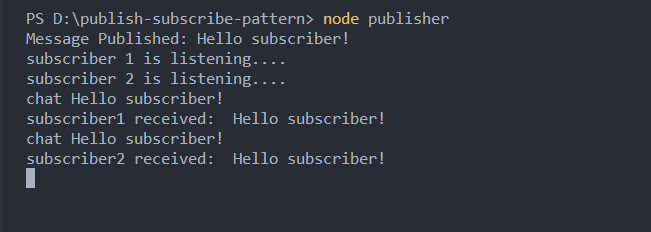
The Short Polling Pattern
Short polling is another communication pattern that facilitates data exchange between client and server. It uses the pull-based communication mechanism (which is basically the client pulling data from the backend) to continuously poll the server for new updates.
How does Short Polling work?
Imagine you’re waiting for a message from a friend, and you don’t want to miss it. What do you do? You keep asking, “Got a message for me yet?”
So, the client makes a request to the server at regular (fixed) intervals (say every x unit of time) to check for new data or updates. The server sends back a response and if there’s new available data or an update, the server includes the data in the response.
Here’s what the client-server communication would look like:
- Client: “Hey, server, any new messages?”
- Server: “Nah, nothing yet.”
- Client: “Alright, I’ll check back later.”
- [Some time passes…]
- Client: “Hey, server, any new messages?”
- Server: “Bingo! Here they are!”
Although polling has some similarities with the request-response model we discussed earlier, a key difference between them is timing.
While polling occurs at regular, predefined intervals regardless of whether updates are available, the request-response model allows clients to request data or actions on-demand when needed, reducing unnecessary communication.
Benefits of Polling
Simplicity: Polling is easy to understand and implement and it’s completely stateless between the client and server. This makes it perfect for scenarios where the complexities need to be minimized.
Compatibility: It can be used with a wide range of technologies and protocols which makes it highly compatible with a number of platforms and environments.
Some example use cases of polling pattern includes simple dashboards, weather apps that require periodic updates, resource monitoring, or in cases where you’re considering cross-platform compatibility.
Limitations of Polling
Latency: Polling introduces latency, as clients must wait for predefined intervals before receiving updates. This can lead to delays in accessing real-time data or receiving notifications.
Inefficiency: Constantly polling the server for updates can be inefficient and can result in unnecessary network and server overhead.
Scaling: Handling a large number of simultaneous clients using polling can be resource-intensive for the server. It may require significant server resources to manage numerous concurrent polling requests.
Here's a code snippet to illustrate short polling. Here, the client sends a periodic request(polls ) to the server to check for upload progress.
The app.js file:
const express = require("express");
const app = express();
//create a dictionary to store the upload progress
const uploadStatus = {};
//simulate upload of file
app.post("/upload", (req, res) => {
//create a unique request id for incoming request
const requestId = Math.floor(Math.random() * 1000000);
uploadStatus[requestId] = 0;
simulateUploadProgress(requestId);
res.json({ requestId });
});
//endpoint to check upload progress
app.get("/status/:requestId", (req, res) => {
const requestId = parseInt(req.params.requestId);
if (!isNaN(requestId) && uploadStatus[requestId] !== undefined) {
if (uploadStatus[requestId] === 100) {
//upload completed
res.json({ progress: 100, message: "UPLOAD COMPLETED!" });
} else {
// upload still in progress
res.json({ progress: uploadStatus[requestId] });
}
} else {
res.status(404).json({ error: "Request ID not found" });
}
});
//update upload progress by 10% every 5 secs
function simulateUploadProgress(requestId) {
if (uploadStatus[requestId] < 100) {
setTimeout(() => {
uploadStatus[requestId] += 10;
simulateUploadProgress(requestId);
}, 5000);
}
}
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
Here's the output in the terminal

The Long Polling Pattern
Long polling is like polling but uses a push-based communication mechanism. In long polling, instead of the client asking the server, “Any updates?” all the time, it says, “Let me know when something’s up.”
Here’s how Long Polling works:
The client pings the server, just like in regular polling, but this time, the server doesn’t immediately answer. It holds the connection open, like keeping a phone line on hold. When there’s something to share, it responds. It’s like the server’s saying, “Hey, I’ll call you when I have news.”
It is used in web applications to achieve real-time or near-real-time updates between a client and a server.
Benefits of the Long Polling Pattern
Low Latency: Long polling provides low latency when compared to traditional polling as data is immediately sent back to clients as soon as they are available.
Real-Time Updates: With the long polling technique, applications can achieve real-time updates without the need for constantly polling the server.
Limitations of the Long Polling Pattern
Resource Intensive: Long polling requires keeping many connections open. As a result, it can be resource-consuming on both the server and client side.
Increased Latency: Although long polling helps cut down on frequent polling, it can still introduce latency when compared to other real-time communication protocols like Web Socket. Clients may experience delays between updates since they have to wait for the server to respond.
Difficult to Scale: When dealing with a large number of concurrent clients, long polling can strain server resources. As more clients establish long-polling connections, the server may struggle to manage and respond to all these connections efficiently.
Typical use cases of long polling include real-time updates, event-driven applications, and event notification systems.
Here's a code snippet to illustrate the concept of long polling where the client waits for updates from the server.
const express = require("express");
const app = express();
const uploadStatus = {};
app.post("/upload", (req, res) => {
const requestId = Math.floor(Math.random() * 1000000);
uploadStatus[requestId] = 0;
updateUploadProgress(requestId, uploadStatus[requestId]);
res.json({ requestId });
});
app.get("/status/:requestId", async (req, res) => {
const requestId = parseInt(req.params.requestId);
//simulate long polling (the server will not respond until done)
while ((await checkUploadComplete(requestId)) === false);
res.end("\n\n Upload status: completed " + uploadStatus[requestId]);
});
//update progress by 20% after every 5 seconds
function updateUploadProgress(requestId, progress) {
uploadStatus[requestId] = progress;
console.log(`Updated progress to ${progress}`);
if (progress === 100) return;
this.setTimeout(() => updateUploadProgress(requestId, progress + 20), 5000);
}
//check upload status
function checkUploadComplete(requestId) {
return new Promise((resolve, reject) => {
if (uploadStatus[requestId] < 100) {
this.setTimeout(() => resolve(false), 1000);
} else {
resolve(true);
}
});
}
const PORT = 4000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
And here's the output in the terminal.
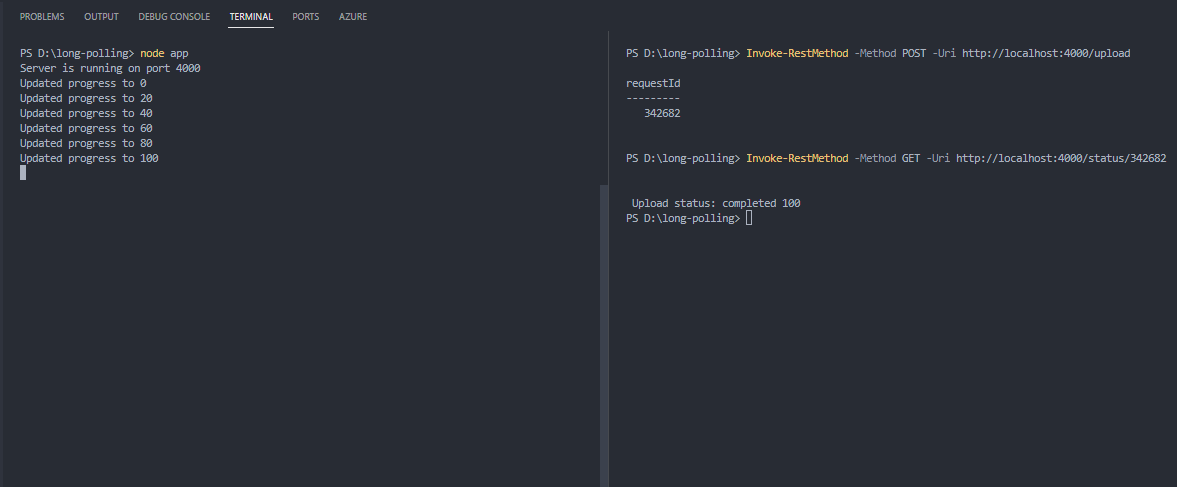 code output
code output
The Push Pattern
Push is a communication model that is used to deliver real-time updates to connected clients.
In this model, the client opens a connection to the server and awaits messages or updates from the server. Whenever there is a new update or message, the server immediately pushes that update to the client without the client explicitly requesting it — as long it is connected.
This model allows for bidirectional communication between the client and server. Web sockets, a popular protocol, uses the push model as its underlying data exchange method.
The Push model provides the most real-time or near real-time end-user experience when compared to other closely related paradigms such as polling and long polling.
To explain how the push pattern works, imagine a chat room with multiple connected users as an example. The client and server conversation will look like this:
- user1 (client): “Hello…”
- Server: “Oh, user1 has a message!” Instantly sends it to everyone else in the room.
- User2 (client): Gets the message from user1 without doing anything.
- User3 (client): Also receives the message from user1 — no need to refresh or ask for it.
In the example above, the push pattern enables real-time communication such that whenever there’s a message from a client in the chat room, it pushes the message to all other connected clients in that room without them having to continuously poll or request updates.
Popular technologies that uses the push pattern are RabbitMQ and WebSocket.
Benefits of Push Pattern
Real-Time Updates: The push model allows clients to receive updates from the server as soon as they are available. This is key, especially in applications where real-time updates are crucial.
Reduced Latency: Since the server pushes updates to the client as soon as they are available, it potentially reduces the latency.
Efficiency: Because there is no need for continuous polling or frequent client requests, there is efficient use of network resources and reduced server load.
While the push model is widely adopted as the best fit for providing real-time updates, it does have its own disadvantages.
Limitations of Push Pattern
Scalability: It can become difficult to scale as the number of connected clients increases. At this point, it becomes resource-intensive, especially on the server side since the server needs to maintain open connections with multiple clients.
Client support: Some clients might not be able to handle pushed messages as not all client platforms support push technologies. This may lead to compatibility issues and may need some sort of fallback mechanism for unsupported clients.
Some example use cases of the push pattern include chat and messaging apps, notification systems, IoT data streaming, and online gaming, to name a few.
Here’s a simple Node.js code example to illustrate the push pattern using Web Sockets. To run the code, you have to install the ws library using npm.
//create a server - this server will push updates to the clients at intervals
const WebSocket = require("ws");
const server = new WebSocket.Server({ port: 8080 });
server.on("connection", (client) => {
console.log("Client connected to server");
//Simulate client to receive real-time updates from the server every 2 seconds
const interval = setInterval(() => {
const message = `Message received at: ${new Date().toLocaleTimeString()}`;
client.send(message);
}, 2000);
// Handle client disconnection
client.on("close", () => {
clearInterval(interval);
console.log("Client disconnected");
});
});
// Client (listens for updates from server)
const clientSocket = new WebSocket("ws://localhost:8080");
clientSocket.onmessage = (event) => {
console.log(`Message from server: "${event.data}"`);
};
Wrapping Up
In this tutorial, we explored five key communication design patterns: Request-Response, Publish/Subscribe, Short Polling, Long Polling, and Push.
Each pattern has its unique strengths and limitations which makes them suitable for various use cases.
Depending on your application’s goal, understanding these patterns will help you design efficient backend systems.