
By shota jolbordi
Docker has been a buzzword for tech people for the last several years, and the more times goes by, the more often you hear about it. We’re seeing it more in job requirements, and more companies are starting to incorporate it. Nowadays it feels like it’s something so basic and common in the development world that if you don’t know about it, you are behind everybody else.
No, but seriously, what is this “Docker” thing? Why is everybody so excited about it? What is it even? Can you define it? is this a desktop app? CLI tool? a website? service? is this thing for production or is it a dev tool? Both? I’ve heard it has these things like “images” and “containers” and it’s like a virtual machine but not really a virtual machine. Why do I even need it, and what does all of this have to do with this blue whale after all?
In this article I’ll try to explain:
- what exactly is “docker”
- why you might need it
- which problems is it trying to solve
- how is it different from a virtual machine
- when to use it over a virtual machine and vice versa
- what are images and containers in general
- and how they are implemented in docker.
I’m going to go through all the concepts in a specific order so that every other topic I explain will require an understanding of the previous concepts. However, while reading this, if you don’t get something, or something feels vague, just keep reading, it will all make sense in the end. My advice about this article would be to read it 2 times to have your “aha moments”.
Okay enough with that, let’s get started!

What is Docker?
There are many “docker” names you might hear throughout the internet, and for a newbie it might be overwhelming. Let’s take a moment and define some of those names to at least know which one is which.
- Docker, Inc
- docker engine (community / enterprise )
- docker for Mac
- docker for windows
- docker client
- docker host
- docker server
- docker hub
- docker registry
- docker compose
- docker swarm
- docker machine
- docker daemon
Quite a lot of dockers here, huh? I’m going to give you a short definition for each of the terms here so you know what they are.
Docker (company)
Docker, Inc was co-founded in 2010 by Solomon Hykes (CTO) in San Francisco, and at that time it was called dotCloud, Inc. They’ve been running a PaaS (platform as a service) type of business, similar to Heroku. To implement this they’ve been using Linux containers.
In March of 2013 at PyCon, Solomon revealed a new product by dotCloud, Inc called “docker”. The motivation as he describes it in his talk (the first ever talk where docker was mentioned) was that people have been very interested in Linux containers and how they could build something with them, but the problem was that Linux containers were very complicated. At dotCloud, Inc they decided to simplify usage of Linux containers and make them accessible for everybody, so the software “docker” was born.
Later in 2013, dotCloud, Inc announced that they were changing their name to Docker, inc and their primary product from now on would be “docker” (software). They spun off their PaaS business to another company and the rest is history.
For us, we are primarily interested in docker software, not in the company itself, but I think it’s good to know a little bit of history behind it.
Docker (software)
Docker is available in 2 editions: Docker community edition (CE) and Docker enterprise edition (EE). For development environment and small teams, CE is the way to go, so in this article we won’t cover EE. CE is free and EE is how Docker, Inc actually makes money.
Docker software consists of 2 separate programs, that is docker engine, also known as docker daemon (because it is, in fact, a daemon, running in the background ) and docker client.
Engine / Daemon
Docker engine is what actually enables Linux containers to work — it’s the “brain of docker” so to speak.
Docker engine is responsible for running processes in isolated environments. For each process, it generates a new Linux container, allocates a new filesystem for it, allocates a network interface, sets an IP for it, sets NAT for it and then runs processes inside of it.
It also manages such things as creating, removing images, fetching images from the registry of choice, creating, restarting, removing containers and many other things. Docker engine exposes the rest API which can be used to control the daemon.
Client
Docker client provides the CLI to control docker daemon. It’s just an HTTP API wrapper. Basically, docker client sends API requests to docker engine which in itself actually does all the magic. Docker client and daemon don’t have to be on the same machine. You can access the CLI with the docker command from the terminal.
Host
Docker host is a computer that has docker daemon running on it. Sometimes it’s also called docker server.
Hub
Docker hub is a docker image registry provided by Docker, Inc itself. It enables users to push images to their repository, make them public or private, and pull different images, all using the docker client CLI.
There are images for pretty much everything made by other people or companies, every language, every database, every version of it. It’s like GitHub for docker images. There are Docker image registries available by other companies, such as Quay, Google container registry, and Amazon Elastic Container Registry. Alternatively, you can host your own docker registry.
Registry
Docker registry is a server-side application that allows you to host your own docker repository. It is provided in the form of an image hosted on docker hub. To make it work you need to pull an image called “registry” from docker hub and spin up the container from it. A Docker host running a “registry” container is now a registry server.
For Mac
Docker for Mac is a separate software from docker, provided by Docker, Inc, that simplifies development with docker on Mac OS. The package includes docker client, the full-blown virtual machine running on Mac OS’s native HyperKit hypervisor, docker daemon installed inside this machine, docker-compose and docker-machine orchestration tools. The container’s exposed ports are forwarded from the VM to localhost automatically.
For Windows
Docker for Windows is same configured specifically for Windows. It uses Hyper-v (Windows 10’s native virtualization solution) for its virtualization software and also gives you the ability to run windows containers alongside Linux containers.
Machine
Docker machine is an orchestration tool that allows you to manage multiple docker hosts. It lets you provision multiple virtual docker hosts locally, or on the cloud, and manage them with docker-machine commands. You can start, restart, and inspect managed hosts. You can point docker client to one of the hosts and then manage daemon on that host directly. There are many ways you can manage docker hosts with this tool, just have a look at the CLI reference.
Compose
Docker compose is also an orchestration tool for docker. It allows you to easily manage multiple containers dependent on each other within one docker host via docker-compose CLI. You use a YAML file to configure all the containers. With one command you can start all containers in the correct order and set up networking between them. Here is the reference.
Swarm
Docker swarm is another orchestration tool aimed to manage a cluster of docker hosts. While docker-compose managers multiple Docker containers within one docker host, docker swarm manages multiple docker hosts managing multiple Docker containers.
Unlike docker-compose and docker-machine, docker swarm is not a standalone orchestration software. Swarm mode is built in docker engine and is managed through Docker client.
In order to create a swarm you need to ssh into a machine you intend to make into a swarm and docker swarm init --advertise-addr <ip to publish>. This command will make a machine accessible on <ip to publish>. Other docker hosts can now join the swarm on this IP.
Summary
Okay, so what did we learn so far?
Docker is not a standalone software, it’s a platform for managing Linux containers. Whenever someone mentions docker in the context of software, they are talking about docker CE or docker EE.
Docker is developed by Docker, Inc to simplify the usage of Linux containers. The platform consists of multiple tools for running and managing Linux containers, which include:
- Docker daemon/engine that is responsible for generation and running of Linux containers.
- Docker client that is a separate application which controls docker daemon through the REST API.
- Docker-compose, docker-machine, and docker swarm are orchestration tools, they are not necessary for running processes inside Linux containers, but they make container management very simple. To be frank, in real life scenarios they are pretty much a necessity, because managing all those containers, hosts and clusters of hosts manually is…well, let’s say it’s a bad business strategy.
- Docker hub is a service that provides a registry of docker images. We can store our images on the docker hub and pull images made by others for us to use.
- Docker registry allows us to host our own private registry in case we don’t want to use an existing one.
- Docker for Mac and Docker for Windows are separate tools that simplify developing with docker on Mac or Windows.
If you are a beginner, it’s ok if you don’t understand everything mentioned above 100%. Some things might be vague, you might have some questions, and that’s normal. I did mention images and containers multiple times but did not explain what they are.
This section is intended to help you navigate between all those names, remove uncertainty, and understand what is what so you don’t get overwhelmed when hearing all those different “docker ” type of titles.
With this sad, I think based on what we’ve learned so far, you should be able to more or less understand the following picture:
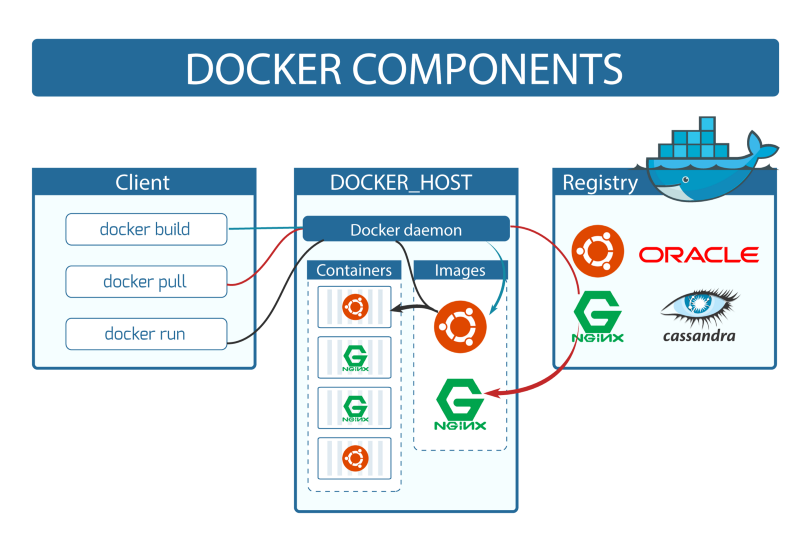
As you can see, docker client and docker daemon are on different machines here, so this might answer some of your questions like…
Why did they split docker into client and engine? Why did not they make it so that CLI would control the engine directly instead of the rest API
Well because it allows having the client and engine on different machines, so multiple different hosts can be managed from one computer.
With all those things clarified, we can dive deeper.
Virtual Machines
Hey, hey, wait a minute — are we talking about docker here or what?
Yes, we are, however at some point in learning docker a natural question will emerge:
What is the difference between VMs and Containers, and why would I use one over another?
Everybody who learns docker goes through this, and I think we might as well go through it now and get it out of the way.
There is a lot out there about how virtual machines work under the hood. We can’t go over all the details in this article, but I will explain just enough so that you understand the difference between VM’s and Containers.
Every computer, ever, be it the gigantic web server running Linux or your overpriced iPhone X, has 4 essential physical components:
- Processor (CPU),
- Memory (RAM),
- Storage (HDD / SSD),
- The network card (NIC).
The main task of any operating system is to basically manage those 4 resources. The part of the operating system that does this is called the Kernel, also referred to as the Core.
The kernel, simply put, is a part of the OS that controls the hardware. The kernel controls drivers for different IO devices such as a mouse, keyboard, headphones, microphone…etc. The kernel is the first program loaded when the computer is turned on, right after the bootloader, and then it handles the rest of the startup process. An absolute majority of the time that it takes to turn on the computer, is because of the Kernel.
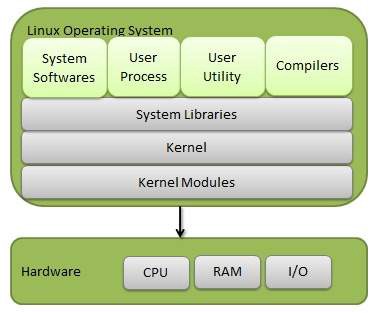
Each operating systems has its own implementation of the kernel, but in fact they do all the same thing: they control the hardware.
So how is it possible to run one OS inside another? Essentially what we need is a program that enables the Guest OS (the operating system that is running inside another operating system) to control the hardware of the Host OS (an operating system that has a guest OS running inside of it).
Hypervisor
The hypervisor, also referred to as Virtual Machine Manager (VMM), is what enables virtualization (running several operating systems on one physical computer). It allows the host computer to share its resources between VMs.
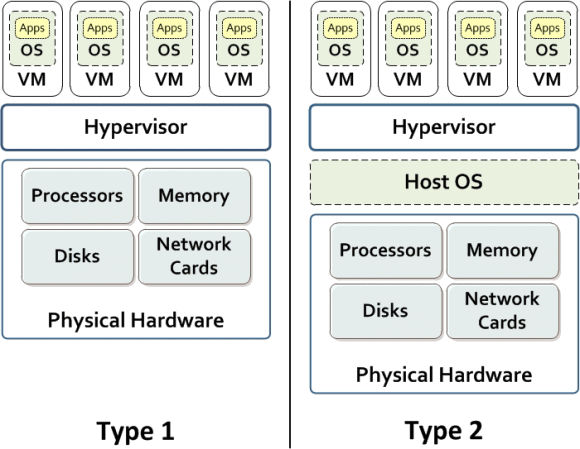
There are 2 types of Hypervisors:
Type 1, also called “Bare Metal Hypervisor”
This software is installed right on top of the underlying machine’s hardware (so, in this case, there is no Host OS, there are only Guest OS’s). You would do this on a machine on which the whole purpose was to run many virtual machines.
Type 1 hypervisors have their own device drivers and interact with hardware directly unlike type 2 hypervisors. That’s what makes them faster, simpler and hence more stable.
Type 2, also called “Hosted Hypervisor”
This is a program that is installed on top of the operating system. You are probably more familiar with it, like VirtualBox or VMware Workstation. This type of hypervisor is something like a “translator” that translates the guest operating system’s system calls into the host operating system’s system calls.
The system calls (syscalls) are a way in which a program requests a service from a Kernel, and the Kernel does — remember what? It manages underlying hardware.
For example, in your program, say you want to copy the content of one file into another. Pretty straightforward right? For this, you need to take some bytes from one part of your Hard Disk and put them into another part. So basically, you are doing stuff with a physical resource, the Hard Disk in this example, and you would need to initiate a system call to do this. Of course in all programming languages, this is abstracted away from you, but you get the point.
Since all OS Kernels, despite being implemented in different ways, do the same job (control hardware), we just need a program that will “translate” a guest OS’s system calls to control the hardware.
An upside of a Type 2 hypervisor is that in this case we don’t have to worry about underlying hardware and it’s drivers. We really just need to delegate the job to the host OS, which will manage this stuff for us. The downside is that it creates a resource overhead, and multiple layers sitting on top of each other make things complicated and lowers the performance.
Containers
Virtual machines are not the only virtualization technique. In the case of a virtual machine, we have a full-blown virtual computer, in its entirety, with its own dedicated Kernel. We allocate RAM for it, we allocate memory for it, and we interact with it as if it was a standalone computer.
There are several problems with this. First and most obvious is inefficient resource management. Once you allocate some resources for a VM, it’s going to hold onto them as long as it’s running.
For example: if you allocate 4 GB of RAM and 40GB of disk memory for a VM, once you run it, those resources will be unavailable as long as this VM is running. It might only need 1 GB of RAM at some moment, and you might be lacking RAM for some other process in another VM or host machine. But since it has this amount of RAM allocated, it’s just going to sit there unused.
Another problem is boot up time. Since the VM has its own Kernel, in case you need to restart your machine, it will need to boot up an entire Kernel. While the machine is rebooting, your service that was running in VM will be unavailable.
Containers to the rescue
To put it simply, a container is a virtual machine without a Kernel. Instead, it is using the Kernel of a host operating system. To make this possible, we need a set of software and libraries that will allow containers to use the underlying OS Kernel, and sort of “link” them if you wish. Such libraries are, for example, “liblxc” and “libcontainer” (this last one is developed by Docker, Inc and is used inside docker engine).
Containers have their own allocated filesystem and IP. Libraries, binaries, services are installed inside a container, however, all the system calls and Kernel functionality comes from the underlying host OS.
Containers are very lightweight. Boot up and restart happens very fast because they don’t need to start up the Kernel every time. They don’t waste physical resources since they don’t need them to be allocated for their Kernel, as they don’t have a separate Kernel.
One drawback is that it’s only possible to run containers of the same type as the underlying OS. You can’t run Linux containers on Windows or Mac, because they need Linux Kennel to operate. The solution for Mac and Windows users would be to install a type 2 hypervisor such as VirtualBox or WMware Workstation, boot up the Linux machine, and then run Linux containers inside of it (in fact that’s what Docker for Mac and Docker for Windows do, but they use native hypervisors that come with the respective OS).
Setting up and running Linux containers is not that straightforward. It’s troublesome and requires a decent knowledge of Linux. Managing them is even more tedious.
As I’ve mentioned above, what Docker, Inc does is it makes Linux containers easy to use and available to everybody, and you do not have to be a Linux geek to use Linux containers nowadays thanks to docker.
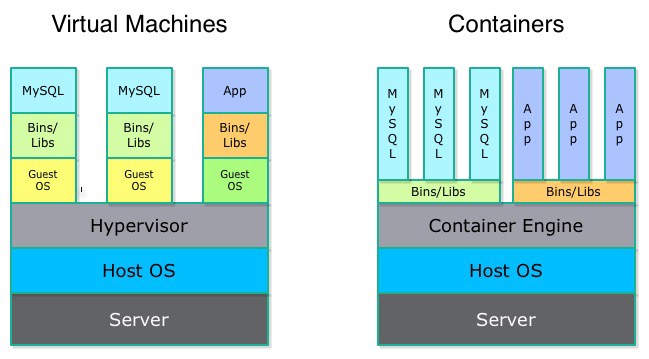
Containers VS Virtual Machines
From the previous section about containers, you might think that containers are just better virtualization solutions than VM’s, but that’s not how it is.
A container’s purpose is running processes in an isolated environment, for docker each container for every single process. VM’s are for emulating an entire machine. Nowadays only Linux and windows containers exist, but there are all kinds of hypervisors to emulate any kind of operating system. You can run windows 10 inside an iPad if you wish. Those 2 are different technologies and they don’t compete with each other.
VM’s are more secure, since containers make system calls directly to the Kernel. This opens up a whole verity of vulnerabilities.
Some low-level software that messes with a Kernel directly should be sandboxed inside a virtual machine.
Often you can see docker containers running inside virtual machines in the production environment, so VM’s and containers actually stick together very well.
Docker images and containers
Docker introduces several concepts that simplify…or I would rather say revolutionize the usage of Linux Containers
Linux containers in docker are made from templates called “images”. An image is a basically a binary file that holds the state of a Linux machine (without the Kernel of course). You can draw a parallel to VM’s disk images such as .vdi, .vmdk or .vhd files.
Docker’s approach to images is different from a VM’s. In a VM you would just mount a disk image, run the VM, and you would have a running instance of a machine. Whenever you modify filesystem in VM, install or remove anything, all of this is reflected on an image you’ve mounted. The image is basically the Hard Disk of the machine.
In docker, images are read-only — you don’t run images directly, instead, you make a copy of an image and run it. This running instance of an image is called a container. By doing this you can have several instances of the same Linux container running at the same time, made from the same template, that are images. Whatever happens with a container does not affect the image it was made from. You can make as many instances of a container from an image as your hardware allows you to run.
Merge images via Union Mount
For creating and storing images, docker uses Union Filesystem. It’s a service in Linux, FreeBSD, and NetBSD. Union Filesystems allow us to create one filesystem out of multiple different ones by merging them all together. The
content’s of directories that have the same path will be seen together in a single merged directory. The process of merging is called “union mounting”.
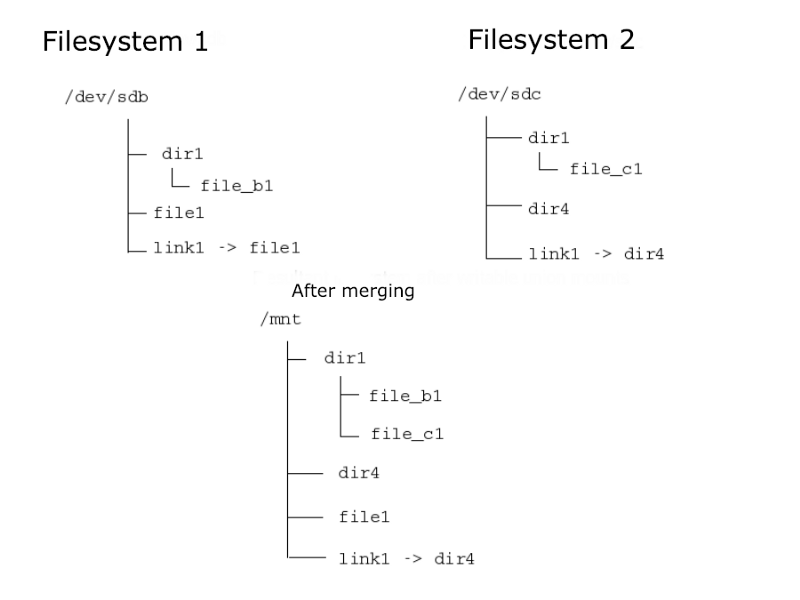
This is roughly how it works:
There are 3 layers that come into play: base layer, overlay, and diff layer.
When merging 2 filesystems, the process looks something like this (keep in mind I’m oversimplifying here):
So we have a base filesystem, and we want to introduce some changes, add files/folders, remove files/folders.
First we will create an overlay filesystem (empty at this point ) and diff filesystem (also empty at this point ). Then we will union mount those filesystems using the union filesystem service built into Linux. When looking into the overlay filesystem it will give us the view of the base filesystem. We can add stuff to it, remove stuff from it, as the actual base filesystem will be unaffected. Instead all changes made to the overlay filesystem will be stored in the diff filesystem. The diff filesystem shows the difference between the base and overlay filesystems.
After we’re done editing the overlay filesystem, we will unmount it. In the end, we have the merged filesystem of overlay and base layers, and the actual base filesystem is unaffected.
This is exactly how docker images are “stacked” on top of each other. Docker uses this exact technology to merge image filesystems.
In order to create your image on top of the already existing image, you need to touch Dockerfile. This is a text file with a set of instructions on how to build an image. Take a look at this simple example.
Inside the terminal run:
docker build <path of the folder with Dockerfile in it>.
This command will build an image based on the instructions given in Dockerfile.
First line: FROM nodesource/trusty5.1
This line indicates that the base layer of this image is another image called nodesource/trusty5.1. By default docker will first try to look for this image locally. If it’s not there it will pull this image from docker hub, or from another docker image registry on this matter. So you just need to configure docker client to look for images in another image registry.
Second line: WORKDIR /app
This line tells docker that all the subsequent commands executed via RUN in Dockerfile will be executed from /app.
Third line: ADD . /app
This line tells docker which filesystems to merge on build. In this example, we see that the overlay layer is the current directory, relative to Dockerfile, and the base layer is /app inside nodesource/trusty5.1 (an image).
The base filesystem’s sub filesystem /app will be merged with an overlay filesystem. If /app filesystem does not exist in the base layer, it will be created as an empty folder.
RUN command will execute a command inside an image while building it via default shell /bin/shRUN <command>; === /bin/sh <;command>
EXPOSE command will serve as documentation for a user to see which port the application is using. It’s not necessary.
CMD will run a command in a container that will be built from this image on startup.
In this example, nodesource/thrusty5.1 is an Ubuntu image with nodeJs 5.1 installed inside of it. Inside ./app directory relative to Dockerfile we have a nodeJs application. When merging them we’ll get an image of Ubuntu with nodeJs 5.1 installed in it and my application inside of it in the /app directory.
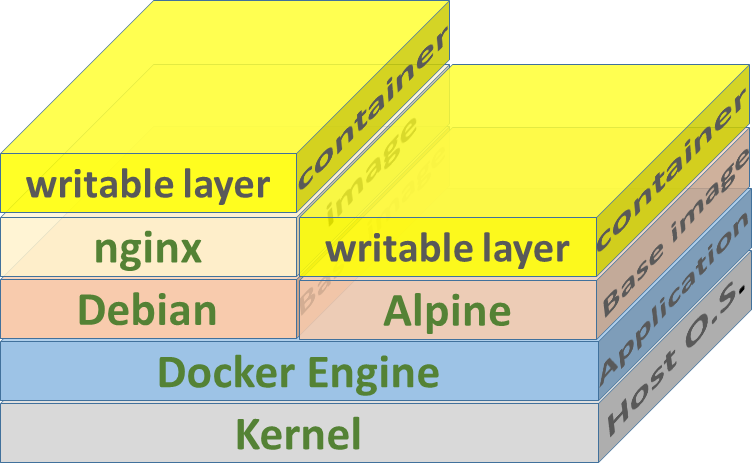
We can then spin up as many containers as we want from this template. Every container will execute npm start inside /app directory of a container on startup.
docker containers
Docker containers, as you already know, are running copies of an image. One additional thing that docker does when creating a container from an image is that it adds a read-write filesystem over the image’s filesystem because the image’s filesystem is read-only.
Docker containers are a bit different than usual Linux containers. Docker containers are made specifically to run a single process in an isolated environment of a Linux container. That’s why we have CMD in Dockerfile, which indicates which process is this going to be. The Docker container will be automatically terminated once there is no process running inside of it.
Docker containers are not supposed to maintain any state, so you can’t ssh into your docker container (well technically you can, but don’t). You should not have it running several processes at once, like, for example, the database and the app that use it. In this case, you would use 2 separate containers and make them communicate with each other. Docker containers are a specific use case of Linux containers to build loosely coupled stateless applications as services.
Inter-Container communication
As I’ve mentioned above, every container should only be running one process. So perhaps now a natural question will emerge: if for example, my app is running in one container and the database is running in another, how do I connect from my app to a database that is running in another container? You can’t connect to localhost in this case.
Docker introduced networking for standalone containers. A very high-level overview of network usage looks like this: you create a new network, which creates a subnet for this network alone. You start a container and attach it to this network, and all containers attached to the same network will be able to ping each other, as if they were on a LAN. Then you can connect from one service running in one container to a service running in another one, as long as they are on the same network.
Okay now, how does it look like?
Run docker network create <some name>:
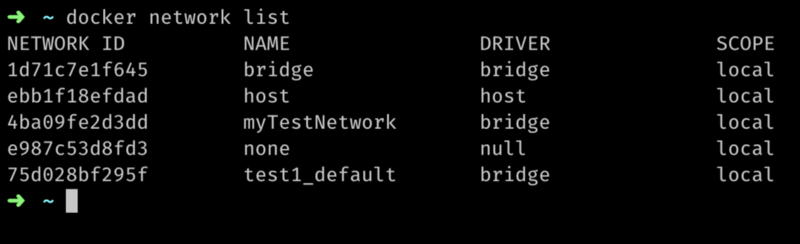
You can list all available networks by running docker network list:
Run docker network inspect <network id or name> to see the network subnet and which containers are currently attached to it:
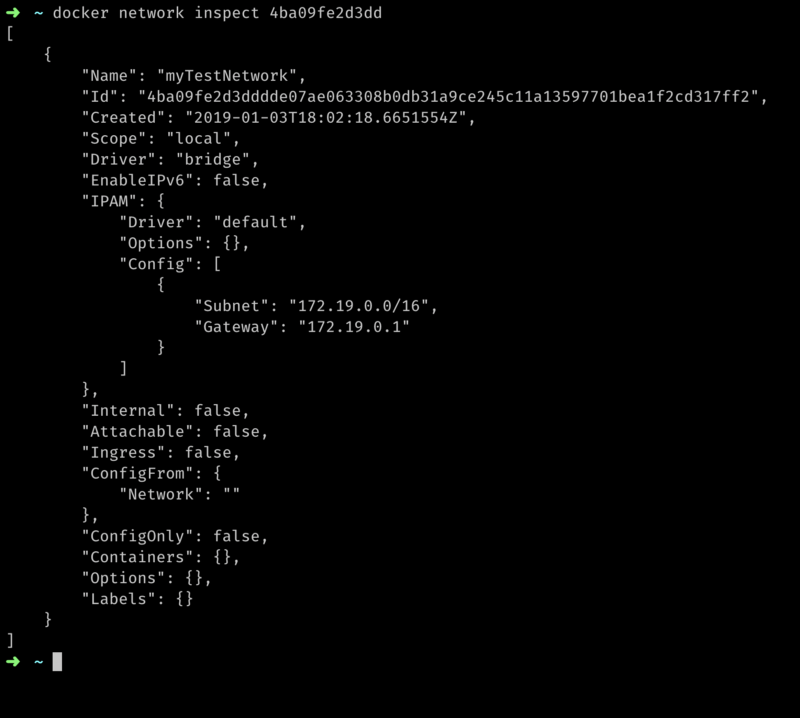
As you can see, it shows the network’s subnet, default getaway, and we also see there are no containers attached to it.
Now I’m going to create 2 containers, from 2 different images, nodejsapi, mongo and run them. --net options indicate which network to use:
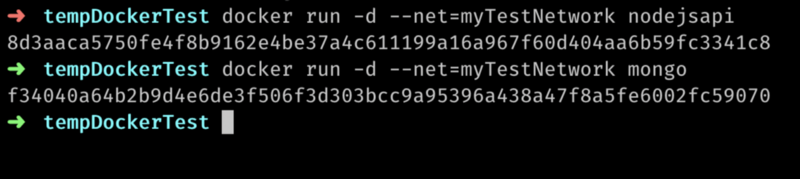
docker run <image name> creates a container from an image and starts it. Now I’ll inspect the network again:
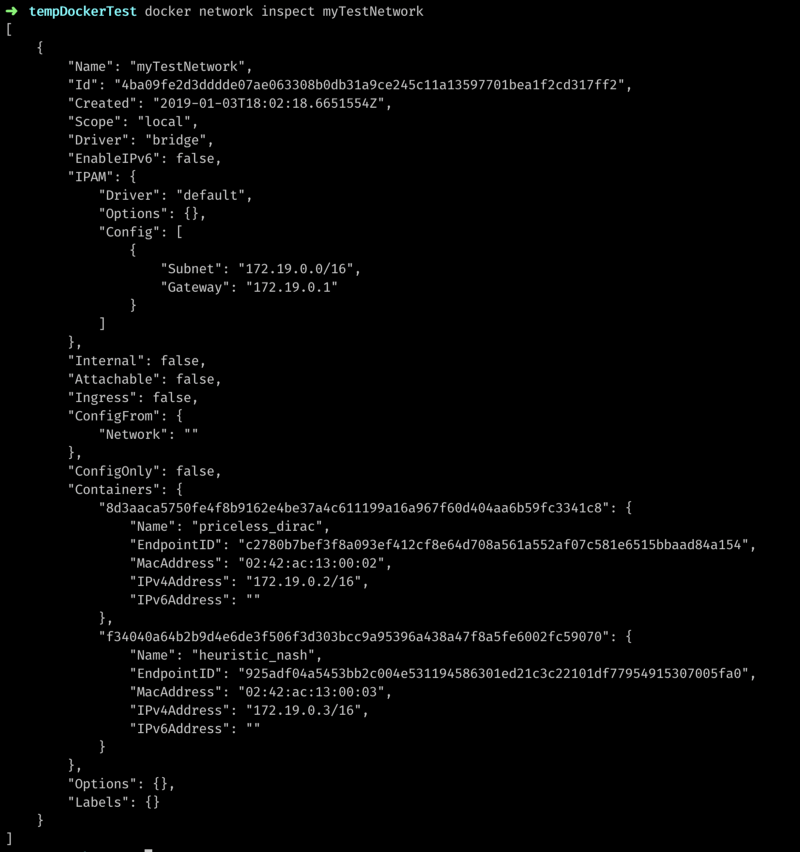
As you now can see 2 containers are running attached to this network. We can also see the IP’s they are using and that they are running on the same subnet. I should be able to ping one container from another now.
Let’s get an IP of one of the running containers:
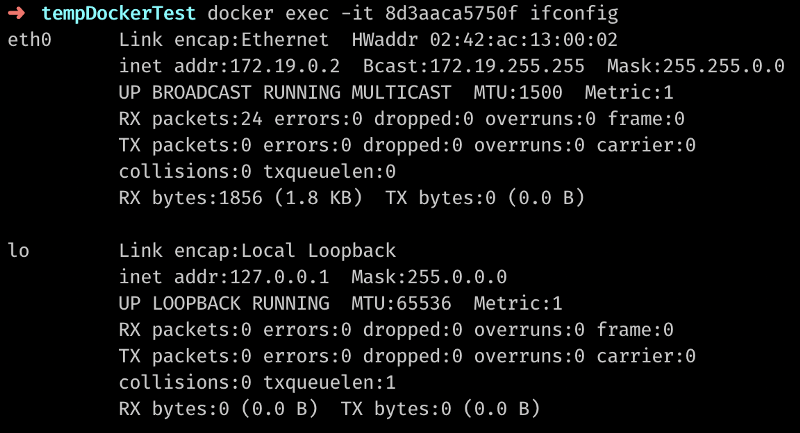
Here I’ve executed the ifconfig command inside a container with id 8d3aaca5750f and redirected output to my terminal.
The IP happens to be 172.19.0.2.
Fo from this container, I should be able to ping another one with an IP of 172.19.0.3:
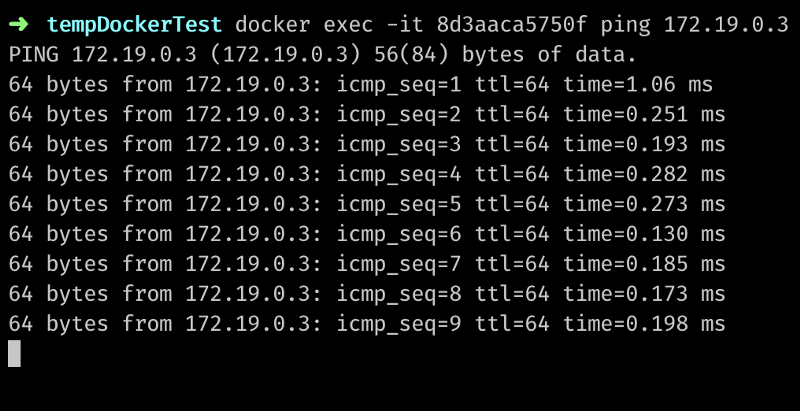
This was just a simple example of docker networks. There is much more to it, so check out the official documentation.
Volumes
As I’ve said before, Docker containers are not supposed to maintain any state. But what if we need state? In fact, some processes are inherently stateful, like a database. For example, a database needs to maintain all the files with data, as that’s a purpose of the database. If we store this data inside a container, when it’s is gone, so is the data. Additionally, we can’t share this data between multiple instances of the container.
To solve this problem, docker introduced volumes. Volumes allow us to store data on the host machine, or on any other machine for that matter, even on the cloud and link the container (or several containers) to this storage.
For example, previously you could see how I created a container from a MongoDB image and ran it using this command:
docker run -d — net=myTestNetwork mongo
When running a container like this, Mongo DB will run inside this Linux container, and save database files under the /data/db directory inside the container.
Now consider this:
docker run -d -v /folder-on-host-machine/data/db:/data/db — net=myTestNetwork mongo.
The -v flag mounts a volume to a container, so now data between host folder’s /folder-on-host-machine/data/db and the container’s /data/db will be synchronized. Now we can potentially run several instances of a MongoDB container and link them all to this volume on a host machine. If one of the instances shuts down, another one is still available and data is not lost because data is stored on a host machine, not inside a container. The container itself is stateless, as it should be.
There is much more to learn about volumes, like details and use cases, but we won’t cover them in this article. Here I just explained what are they and why we need them.
Final words
So this is Docker, in a nutshell! It’s an amazing technology that revolutionizes how we develop, deploy and scale our applications. Here we have just scratched the surface, more is on you to discover.
Any constructive feedback is appreciated.
If you made it this far, please give me some “claps” :)
