By Milecia McGregor
There are a lot of different kinds of neural networks that you can use in machine learning projects. There are recurrent neural networks, feed-forward neural networks, modular neural networks, and more.
Convolutional neural networks are another type of commonly used neural network. Before we get to the details around convolutional neural networks, let's start by talking about a regular neural network.
What is a Neural Network?
When you hear people referring to an area of machine learning called deep learning, they're likely talking about neural networks.
Neural networks are modeled after our brains. There are individual nodes that form the layers in the network, just like the neurons in our brains connect different areas.
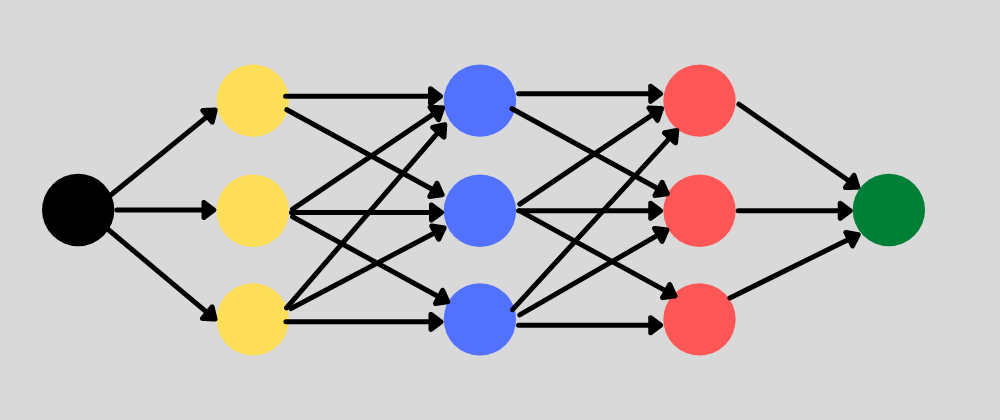 Neural network with multiple hidden layers. Each layer has multiple nodes.
Neural network with multiple hidden layers. Each layer has multiple nodes.
The inputs to nodes in a single layer will have a weight assigned to them that changes the effect that parameter has on the overall prediction result. Since the weights are assigned on the links between nodes, each node maybe influenced by multiple weights.
The neural network takes all of the training data in the input layer. Then it passes the data through the hidden layers, transforming the values based on the weights at each node. Finally it returns a value in the output layer.
It can take some time to properly tune a neural network to get consistent, reliable results. Testing and training your neural network is a balancing process between deciding what features are the most important to your model.
What a convolutional neural network (CNN) does differently
A convolutional neural network is a specific kind of neural network with multiple layers. It processes data that has a grid-like arrangement then extracts important features. One huge advantage of using CNNs is that you don't need to do a lot of pre-processing on images.
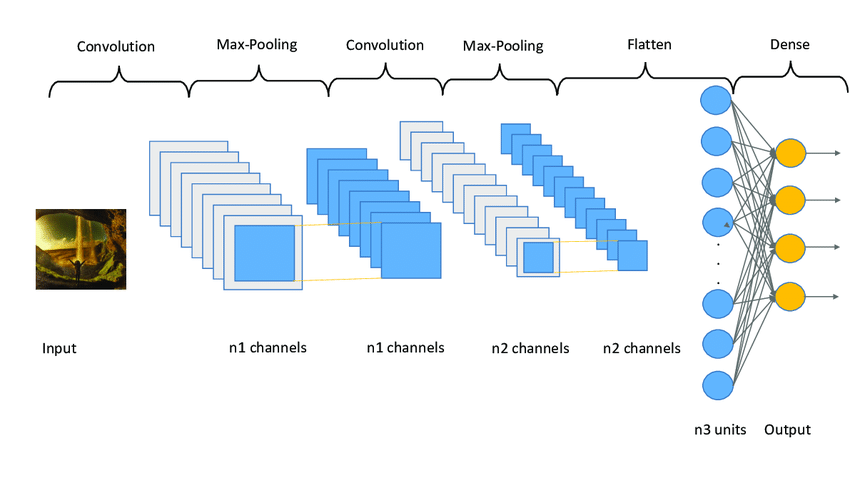 _
_With most algorithms that handle image processing, the filters are typically created by an engineer based on heuristics. CNNs can learn what characteristics in the filters are the most important. That saves a lot of time and trial and error work since we don't need as many parameters.
It doesn't seem like a huge savings until you are working with high resolution images that have thousands of pixels. The convolutional neural network algorithm's main purpose is to get data into forms that are easier to process without losing the features that are important for figuring out what the data represents. This also makes them great candidates for handling huge datasets.
A big difference between a CNN and a regular neural network is that CNNs use convolutions to handle the math behind the scenes. A convolution is used instead of matrix multiplication in at least one layer of the CNN. Convolutions take to two functions and return a function.
CNNs work by applying filters to your input data. What makes them so special is that CNNs are able to tune the filters as training happens. That way the results are fine-tuned in real time, even when you have huge data sets, like with images.
Since the filters can be updated to train the CNN better, this removes the need for hand-created filters. That gives us more flexibility in the number of filters we can apply to a data set and the relevance of those filters. Using this algorithm, we can work on more sophisticated problems like face recognition.
One of things that prevents a lot of problems from using CNNs is a lack of data. While networks can be trained with relatively few data points (~10,000 >), the more data there is available, the better tuned the CNN will be.
Just keep in mind that these data points have to be clean and labeled in order for the CNN in to be able to use them. That's what makes them so expensive to work with.
How Convolutional Neural Networks Work
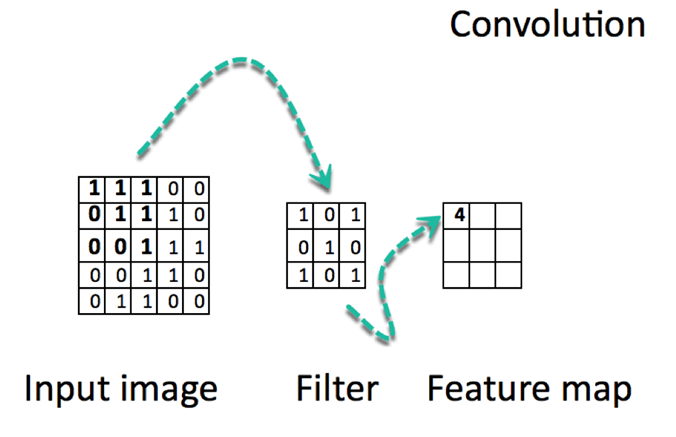
Convolutional neural networks are based on neuroscience findings. They are made of layers of artificial neurons called nodes. These nodes are functions that calculate the weighted sum of the inputs and return an activation map. This is the convolution part of the neural network.
Each node in a layer is defined by its weight values. When you give a layer some data, like an image, it takes the pixel values and picks out some of the visual features.
When you're working with data in a CNN, each layer returns activation maps. These maps point out important features in the data set. If you gave the CNN an image, it'll point out features based on pixel values, like colors, and give you an activation function.
Usually with images, a CNN will initially find the edges of the picture. Then this slight definition of the image will get passed to the next layer. Then that layer will start detecting things like corners and color groups. Then that image definition will get passed to the next layer and the cycle continues until a prediction is made.
As the layers get more defined, this is called max pooling. It only returns the most relevant features from the layer in the activation map. This is what gets passed to each successive layer until you get the final layer.
 https://www.guru99.com/convnet-tensorflow-image-classification.html
https://www.guru99.com/convnet-tensorflow-image-classification.html
The last layer of a CNN is the classification layer which determines the predicted value based on the activation map. If you pass a handwriting sample to a CNN, the classification layer will tell you what letter is in the image. This is what autonomous vehicles use to determine whether an object is another car, a person, or some other obstacle.
Training a CNN is similar to training many other machine learning algorithms. You'll start with some training data that is separate from your test data and you'll tune your weights based on the accuracy of the predicted values. Just be careful that you don't overfit your model.
Use cases for a Convolutional Neural Network
There are multiple kinds of CNNs you can use depending on your problem.
Different types of CNNs
1D CNN: With these, the CNN kernel moves in one direction. 1D CNNs are usually used on time-series data.
2D CNN: These kinds of CNN kernels move in two directions. You'll see these used with image labelling and processing.
3D CNN: This kind of CNN has a kernel that moves in three directions. With this type of CNN, researchers use them on 3D images like CT scans and MRIs.
In most cases, you'll see 2D CNNs because those are commonly associated with image data. Here are some of the applications that you might see CNNs used for.
- Recognize images with little preprocessing
- Recognize different hand-writing
- Computer vision applications
- Used in banking to read digits on checks
- Used in postal services to read zip codes on an envelope
An Example of a CNN in Python
As an example of using a CNN on a real problem, we’re going to identify some handwritten numbers using the MNIST data set.
The first thing we do is define the CNN model. Next we separate our training and test data. Lastly, we use the training data to train the model and test that model using the test data.
from keras import layers
from keras import models
from keras.datasets import mnist
from keras.utils import to_categorical
# Define the CNN model
model = models.Sequential()
model.add(layers.Conv2D(32, (5,5), activation='relu', input_shape=(28, 28,1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (5, 5), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='softmax'))
model.summary()
# Split the data into training and test sets
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Use the training data to train the model
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.fit(train_images, train_labels,
batch_size=100,
epochs=5,
verbose=1)
# Test the model's accuracy with the test data
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
Conclusion
Convolutional neural networks are multi-layer neural networks that are really good at getting the features out of data. They work well with images and they don't need a lot of pre-processing.
Using convolutions and pooling to reduce an image to its basic features, you can identify images correctly.
It's easier to train CNN models with fewer initial parameters than with other kinds of neural networks. You won't need a huge number of hidden layers because the convolutions will be able to handle a lot of the hidden layer discovery for you.
One of the cool things about CNNs is the number of complex problems they can be applied to. From self-driving cars to detecting diabetes, CNNs can process this kind of data and provide accurate predictions.