
By Shane Duggan
I've got a fun tutorial for you today. If you've read my previous article on building custom-knowledge chatbots using LangChain, then you must be bursting with ideas of great projects you can create.
Well, I want to encourage your creativity and give a concrete example of what you can build using LangChain along with a Large Language Model (LLM). And while it might sound intimidating, it's actually pretty simple to implement.
Today, we're going to be creating an AI Tweet Generator using LangChain and OpenAI's LLMs. It's a simple project that takes in a Tweet topic and outputs a Tweet about it.
But what's so special about that? Well, the fun part is that we are going to use LangChain to be able to reference up-to-date information through Wikipedia. This lets us overcome ChatGPT's training data limitation, as it was only trained on data up to 2021.
This is what we'll be making:
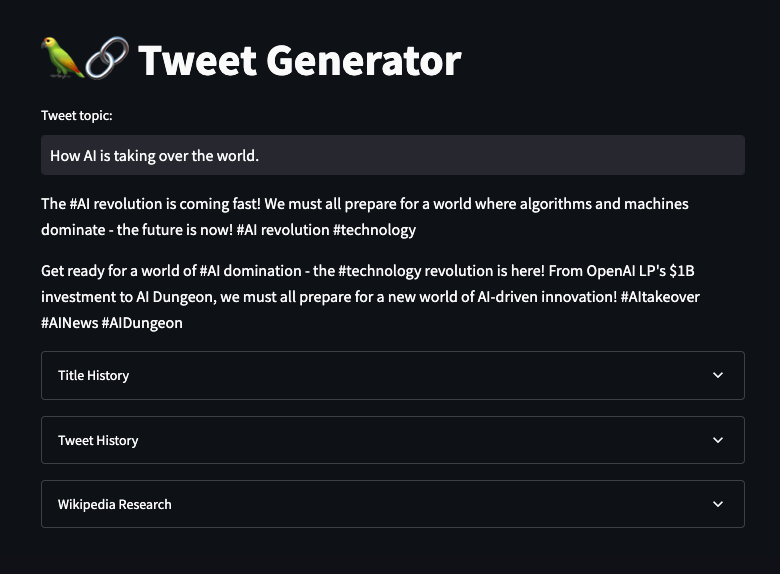
Take a look at the information referenced by our Tweet below. It uses Wikipedia information regarding Microsoft's investment into OpenAI in 2023. So now, you won't need to worry about the data your AI is referencing being outdated.

If that sounds good to you, then let's jump in.
How to Set Up the Project
While this project is going to require several components, everything actually sits nicely in single app.py file that simply brings together several APIs.
Structurally, we'll just create the app.py file and an apikey.py file to store our API keys (mainly for OpenAI).
Along with that, let's get our services installed. Here's the list of the libraries we are going to be using for this project:
- Streamlit – Used to build the app
- LangChain – Used to build LLM workflow.
- OpenAI – For using OpenAI GPT
- Wikipedia – Used to connect GPT to WIKIPEDIA
- ChromaDB – Vector storage
- Tiktoken – Backend tokenizer for OpenAI
To install these, run the below comment in your terminal:
pip install streamlit langchain openai wikipedia chromadb tiktoken
If your system already contains some of these services then you can install them one by one. Additionally, we'll map the API Key variable for this environment. Let's import these into our app.py file and we should be ready to get started.
import os
from apikey import apikey
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = apikey
How to Implement the UI
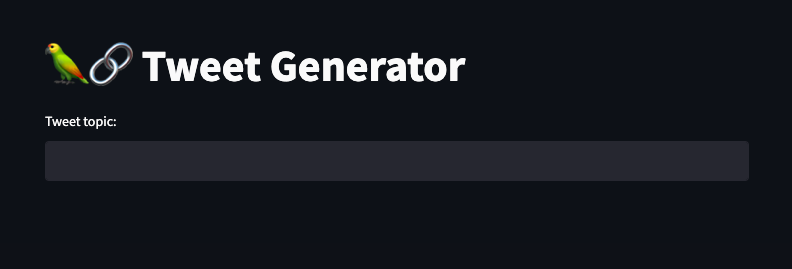
Now, the app we are creating is fairly simple. So I've decided to keep things as minimalistic as possible with the UI, with a single title and text input field. For this Tweet generator, it serves its purpose.
# Creating the title and input field
st.title('🦜🔗 Tweet Generator')
prompt = st.text_input('Tweet topic: ')
Later on, we'll be adding in functionality to display our topic history, tweet history, and most importantly, the Wikipedia data we referenced. For now, this is the UI we'll be working with:
How to Include the Prompt Templates
Now we're moving into LangChain territory. At this point, if you are unfamiliar with LangChain and haven't read my previous article on LangChain, I'd highly recommend doing so the get a better idea of the coming steps.
The first thing we're going to do is introduce our PromptTemplates. Just to recap, PromptTemplates act as wrappers for your prompts to be able to chain them with multiple operations, which is the foundation of LangChain.
In addition, we'll include a wrapper for the Wikipedia API to allow us to include the data in the chain execution.
# template for the title
title_template = PromptTemplate(
input_variables = ['topic'],
template='write me a tweet about {topic}'
)
# template for the tweet
tweet_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template='write me a tweet on this title TITLE: {title} while leveraging this wikipedia reserch:{wikipedia_research} '
)
# wrapper for Wikipedia data
wiki = WikipediaAPIWrapper()
In this example, I created a title prompt as well, just to give us an overarching title of our Tweet topic. For the actual prompting, if you have been using ChatGPT, it's basically the same concept – it's just that now we are introducing variables (tweet topics).
This allows us to avoid typing "write me a tweet about..." for every single input. Instead, we just need to insert the topic. With that out of the way, let's move into introducing the actual OpenAI LLM.
Introducing OpenAI's LLMs
There are several ways to do this, and you can choose whichever model you deem fit. In my previous article, I used the GPT-3.5-turbo chat model with the following code:
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="You are an expert data scientist"),
HumanMessage(content="Write a Python script that trains a neural network on simulated data ")
]
But you can decide which module you'd like to use with your API key and just follow along the LangChain documentation to get that set up.
Today, we'll be using the model "text-davinci-003", which is essentially the same GPT-3 model as in the early days of ChatGPT.
 OpenAI's various models (Found on their website)
OpenAI's various models (Found on their website)
Feel free to experiment with the models to see which tweets yield the best results. You could even try the significantly more powerful (and expensive) GPT-4, but with such a simple prompt-completion case like a tweet generator it might not be necessary.
llm = OpenAI(model_name="text-davinci-003", temperature=0.9)
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key='title', memory=title_memory)
script_chain = LLMChain(llm=llm, prompt=script_template, verbose=True, output_key='script', memory=script_memory)
I've also decided to specify the temperature as 0.9 to allow the model to come up with more creative tweets. Temperature acts as a measure of how random and creative the model's responses will be, ranging from 0 for straightforward, and 1 for wildly random. If you'd like yours to be more factual and deterministic, just dial that down.
Temperature will be the only variable we need to get this going. If you'd like to learn about other fields, take some time to read through the documentation and learn what they are.
For example, we can specify token limits to ensure we don't get a long response, but with our current tweet PromptTemplates that should not be an issue.
How to Keep Track of Your Tweet Generation History
This is an optional part but provides an additional feature for the app. If you want to keep track of the history of the app activity with information such as previous titles or tweets, then just include the following step:
# Memory
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
script_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')
In the code above, we created two different memory variables, title_memory and script_memory. The title_memory keeps the history of tweet topics and the script_memory keeps the history of tweets.
ConversationBufferMemory is a feature from LangChain that allows you to keep track of the inputs and outputs given so far (in this case, that's just the topics and tweets we've previously generated).
How to Chain the Components
Now that we have all of the components of our app sorted (the UI, the prompt templates, and our Wikipedia wrapper), we can put it all together to be executed. And this is where LangChain's value lies.
A good analogy for this would be composite functions in a standard program. Except, our functions in this case are the PromptTemplates, LLMs, and Wikipedia data. Using our wrappers from before, we simply decide the order of execution (like a chain) to get our desired output.
In this case, that would be obtaining the title from our topic, followed by creating the Tweet by using relevant Wikipedia research on the topic, and then displaying those using Streamlit.
if prompt:
title = title_chain.run(prompt) # Running the title prompt
wiki_research = wiki.run(prompt) # Performing wikipedia research
script = script_chain.run(title=title, wikipedia_research=wiki_research) # Creating the tweet
st.write(title) # Show the topic/title of the tweet
st.write(script) # Show the generated tweet
with st.expander('Title History'):
st.info(title_memory.buffer) # Storing the topic of the tweet to the history
with st.expander('Tweet History'):
st.info(script_memory.buffer) # Storing the tweet to the history
with st.expander('Wikipedia Research'):
st.info(wiki_research) # Storing the Wikipedia Research on the topic to the history
When we run those chains, essentially we are taking in the topic from the UI and inserting it into the PromptTemplates that are chained with the LLM. The tweet PromptTemplate also takes in data from Wikipedia to feed to the LLM.
Finally, it's time to check our app. Run it with the following command:
streamlit run app.py
Final Code and Where to Go from Here
The result is being able to overcome the outdated information limitations of ChatGPT and create relevant tweets. If you found it hard to follow along, here's what we have so far:
# Importing necessary packages, files and services
import os
from apikey import apikey
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = apikey
# App UI framework
st.title('🦜🔗 Tweet Generator')
prompt = st.text_input('Tweet topic: ')
# Prompt templates
title_template = PromptTemplate(
input_variables = ['topic'],
template='write me a tweet about {topic}'
)
tweet_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template='write me a tweet on this title TITLE: {title} while leveraging this wikipedia reserch:{wikipedia_research} '
)
# Wikipedia data
wiki = WikipediaAPIWrapper()
# Memory
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
tweet_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')
# Llms
llm = OpenAI(model_name="text-davinci-003", temperature=0.9)
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key='title', memory=title_memory)
tweet_chain = LLMChain(llm=llm, prompt=tweet_template, verbose=True, output_key='script', memory=tweet_memory)
# Chaining the components and displaying outputs
if prompt:
title = title_chain.run(prompt)
wiki_research = wiki.run(prompt)
tweet = tweet_chain.run(title=title, wikipedia_research=wiki_research)
st.write(title)
st.write(tweet)
with st.expander('Title History'):
st.info(title_memory.buffer)
with st.expander('Tweet History'):
st.info(tweet_memory.buffer)
with st.expander('Wikipedia Research'):
st.info(wiki_research)
Now of course, a Tweet Generator is a simple example of what you can do with LangChain and LLMs. You can apply this same process for creating a YouTube script generator or social media content calendar assistant, for example. The possibilities are endless.
Conclusion
I hope you enjoyed this fun tutorial! LangChain has been getting extremely popular lately and for good reason – it's incredibly versatile. I'd highly recommend getting checking it out.
If you enjoyed this article and you would like to find out more about the cool new tools AI creators are building, you can stay up-to-date with my Byte-Sized AI Newsletter. There are tons of exciting stories of what people are building in the AI space, and I'd love for you to join our community.
I also post regularly on Linkedin and I'd be happy to connect! Other than that, happy building and I'm excited to see what projects you come up with.