
By Shane Duggan
You may have read about the large number of AI apps that have been released over the last couple of months. You may have even started using some of them.
AI tools such as ChatPDF and CustomGPT AI have become very useful to people – and for good reason. Gone are the days where you need to scroll through a 50-page document just to find a simple answer. Instead, you can rely on AI to do the heavy lifting.
But how exactly are all these developers creating and using these tools? Well, many of them are using an open source framework called LangChain.
In this article, I'm going to introduce you to LangChain and show you how it's being used in combination with OpenAI's API to create these game-changing tools. Hopefully, I'll inspire one of you to come up with one of your own. So let's jump in!
What Is LangChain?

LangChain is an open source framework that allows AI developers to combine Large Language Models (LLMs) like GPT-4 with external data. It's offered in Python or JavaScript (TypeScript) packages.
As you may know, GPT models have been trained on data up until 2021, which can be a significant limitation. And while these models' general knowledge is great, being able to connect them to custom data and computations opens up many doors. That's exactly what LangChain does.
Essentially, it allows your LLM to reference entire databases when coming up with its answers. So you can now have your GPT models access up-to-date data in the form of reports, documents, and website info.
Recently, LangChain has experienced a significant surge in popularity, especially after the launch of GPT-4 in March. This was thanks to its versatility and the many possibilities it opens up when paired with a powerful LLM.
How Does LangChain Work?
While you may be thinking that LangChain sounds pretty complicated, it's actually quite approachable.
In short, LangChain just composes large amounts of data that can easily be referenced by a LLM with as little computation power as possible. It works by taking a big source of data, take for example a 50-page PDF, and breaking it down into "chunks" which are then embedded into a Vector Store.
 Simple Diagram of creating a Vector Store
Simple Diagram of creating a Vector Store
Now that we have vectorized representations of the large document, we can use this in conjunction with the LLM to retrieve only the information we need to be referenced when creating a prompt-completion pair.
When we insert a prompt into our new chatbot, LangChain will query the Vector Store for relevant information. Think of it as a mini-Google for your document. Once the relevant information is retrieved, we use that in conjunction with the prompt to feed to the LLM to generate our answer.
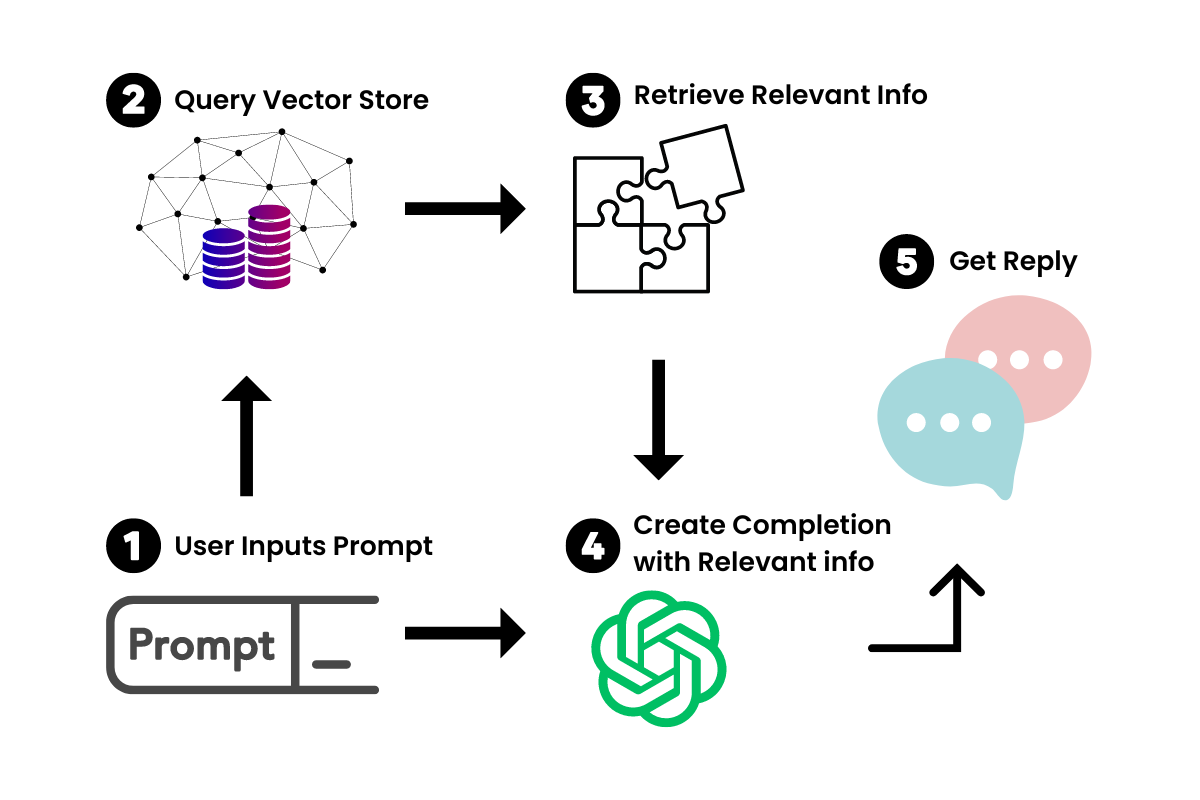 How LangChain Works With OpenAI's LLMs
How LangChain Works With OpenAI's LLMs
LangChain also allows you to create apps that can take actions – such as surf the web, send emails, and complete other API-related tasks. Check out AgentGPT, a great example of this.
There are many possible use-cases for this – here are just a few off the top of my head:
- Personal AI Email Assistant
- AI Study Buddy
- AI Data Analytics
- Custom Company Customer Service Chatbots
- Social Media Content Creation Assistant
And the list goes on. I will cover proper build tutorials in future articles, so stay tuned for that.
How to Get Started with LangChain
A LangChain application consists of 5 main components:
- Models (LLM Wrappers)
- Prompts
- Chains
- Embeddings and Vector Stores
- Agents
I am going to give you an overview of each, so that you can get a high-level understanding of how LangChain works. Moving forward, you should be able to apply the concepts to start to craft your own use-cases and create your own apps.
I'll be explaining everything with short code snippets from Rabbitmetrics (Github). He provides great tutorials on this topic. These snippets should allow you to get all set up and ready to use LangChain.
First, let's get our environment set up. You can pip install 3 libraries that you'll need for this:
pip install -r requirements.txt
python-dotenv==1.0.0
langchain==0.0.137
pinecone-client==2.2.1
Pinecone is the Vector Store that we will be using in conjunction with LangChain. With these, make sure to store your API keys for OpenAI, Pinecone Environment, and Pinecone API into your environment file. You will be able to find this info at their respective websites. Then we just load that environment file with the following:
# Load environment variables
from dotenv import load_dotenv,find_dotenv
load_dotenv(find_dotenv())
Now, we're ready to get started!
Models (LLM Wrappers)
To interact with our LLMs, we are going to instantiate a wrapper for OpenAI's GPT models. In this case, we are going to use OpenAI's GPT-3.5-turbo, as it's the most cost-efficient. But if you have access, feel free to use the more powerful GPT4.
To import these, we can use the following code:
# import schema for chat messages and ChatOpenAI in order to query chatmodels GPT-3.5-turbo or GPT-4
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="You are an expert data scientist"),
HumanMessage(content="Write a Python script that trains a neural network on simulated data ")
]
response=chat(messages)
print(response.content,end='\n')
In essence, the SystemMessage provides context to the GPT-3.5-turbo module that it will reference for each prompt-completion pair. The HumanMessage refers to what you would type into the ChatGPT interface – your prompt.
But with a custom-knowledge chatbot, we often abstract away the repetitive components of a prompt. For example, if I was creating a Tweet generator app, I wouldn't want to keep typing "Write me a Tweet about...". In fact, that's how simple AI writing tools are developed!
So let's look at how we can abstract that away with prompt templates.
Prompts
LangChain provides PromptTemplates that allow you to dynamically change the prompts with user input, similar to how regex are used.
# Import prompt and define PromptTemplate
from langchain import PromptTemplate
template = """
You are an expert data scientist with an expertise in building deep learning models.
Explain the concept of {concept} in a couple of lines
"""
prompt = PromptTemplate(
input_variables=["concept"],
template=template,
)
# Run LLM with PromptTemplate
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))
You can vary these in different ways to fit your use-case. If you are familiar with using ChatGPT, this should be comfortable for you.
Chains
Chains allow you to take simple PromptTemplates and build functionality on top of them. Essentially, chains are like composite functions that allow you to integrate your PromptTemplates and LLMs together.
Using the wrappers and PromptTemplates from earlier, we can run the same prompts with a single chain that takes a PromptTemplate and composes it with an LLM:
# Import LLMChain and define chain with language model and prompt as arguments.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("autoencoder"))
On top of that, as the name suggests, we can chain these together to create even bigger compositions.
For example, I can take the result from one chain and pass it into another chain. In this snippet, Rabbitmetrics takes the completion from the first chain and passes it into the second chain to explain it to a 5 year old.
You can then combine those chains into a larger chain and run that.
# Define a second prompt
second_prompt = PromptTemplate(
input_variables=["ml_concept"],
template="Turn the concept description of {ml_concept} and explain it to me like I'm five in 500 words",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Define a sequential chain using the two chains above: the second chain takes the output of the first chain as input
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
explanation = overall_chain.run("autoencoder")
print(explanation)
With chains, you can create a huge array of functionality, which is what makes LangChain so versatile. But where it really shines is using it in conjunction with a Vector Store as discussed earlier. Let's introduce that component.
Embeddings and Vector Stores
This is where we incorporate the custom data aspect of LangChain. As mentioned earlier, the idea behind embeddings and Vector Stores is to break large data into chunks and store those to be queried when relevant.
LangChain has a text splitter function to do this:
# Import utility for splitting up texts and split up the explanation given above into document chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
texts = text_splitter.create_documents([explanation])
Splitting up text requires two parameters: How big a chunk is (chunk_size) and how much each chunk overlaps (chunk_overlap). Having an overlap between each chunk is important to help identify relevant adjoining chunks.
Each of those chunks can be retrieved as such:
texts[0].page_content
After we have those chunks, we need to turn them into embeddings. This allows the Vector Store to find and return each chunk when queried. We'll use OpenAI's embedding model to do this.
# Import and instantiate OpenAI embeddings
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model_name="ada")
# Turn the first text chunk into a vector with the embedding
query_result = embeddings.embed_query(texts[0].page_content)
print(query_result)
And finally, we need to have a place to store these vectorized embeddings. As mentioned earlier, we will be using Pinecone for this. Using the API keys from the environment file earlier, we can initialize Pinecone to store our embeddings.
# Import and initialize Pinecone client
import os
import pinecone
from langchain.vectorstores import Pinecone
pinecone.init(
api_key=os.getenv('PINECONE_API_KEY'),
environment=os.getenv('PINECONE_ENV')
)
# Upload vectors to Pinecone
index_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name)
# Do a simple vector similarity search
query = "What is magical about an autoencoder?"
result = search.similarity_search(query)
print(result)
And now we are able to query relevant information from our Pinecone Vector Store! All that's left to do is to combine what we have learned to create our specific use case – giving us our specialized AI "Agent".
Agents
An agent is essentially an autonomous AI that takes in inputs and completes those as tasks sequentially until the end goal is reached. This involves our AI using other APIs that allows it to complete tasks such as sending emails or doing math problems. Used in conjunction with our LLM + prompt chains, we can string together a proper AI app.
Now, explaining this part will be extensive, so here's a simple example of how a Python agent can be used in LangChain to solve a simple mathematical problem. This agent in this case solves the problem by connecting our LLM to run Python code, and finding the roots with NumPy:
# Import Python REPL tool and instantiate Python agent
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=1000),
tool=PythonREPLTool(),
verbose=True
)
# Execute the Python agent
agent_executor.run("Find the roots (zeros) if the quadratic function 3 * x**2 + 2*x -1")
A custom-knowledge chatbot is essentially an agent that chains together prompts and actions that query the Vectorized Storage, take the results, and chain that with the original question!
If you would like to read more about AI agents, this is a great resource.
Other Variations
Even with your newfound basic understanding of the functionality of LangChain, I'm sure you are bubbling with ideas at this point.
But we've only looked at one OpenAI model so far, and that's the text-based GPT-3.5-turbo. OpenAI has an array of models that you could use with LangChain – including image generation with Dall-E. Applying the same concepts we've discussed, we can create AI Art Generator agents, Website Builder agents, and much more.
Take some time to explore the AI landscape and I'm confident that you'll start getting more and more ideas.
Conclusion
I hope you've learnt a bit more on what's going on behind the scenes of all of these new AI tools. Understanding how LangChain works is a valuable skill to have as a programmer these days and can open up the possibilities for your AI development.
If you enjoyed this article and you would like to find out more about the cool new tools AI creators are building, you can stay up-to-date with my Byte-Sized AI Newsletter. There are tons of exciting stories of what people are building in the AI space, and I'd love for you to join our community.
You can also drop me a follow on Twitter, where we can also get in touch.
Other than that, start experimenting with LangChain and create some nifty AI projects.