

Infrastructure as Code (IaC) is a revolutionary approach to managing and provisioning computing infrastructure. With IaC, you can automate the process of provisioning, configuring, and managing infrastructure using code and software development techniques. This approach provides a more efficient, consistent, and reliable way of managing infrastructure compared to traditional manual methods.
While IaC offers numerous benefits, it can sometimes be challenging to navigate the complexity of configuration properties and the variety of functions and commands needed to deploy infrastructure. This is where artificial intelligence (AI) comes into play. AI has the potential to significantly simplify the process of deploying infrastructure by automating many of the complex and tedious tasks involved in IaC.
We just published a course on the freeCodeCamp.org YouTube channel that will teach you how to use AI to create and deploy IaC. In this course, you will learn how to utilize AI tools developed by Pulumi, a company that has provided a grant to make this course possible.
Through a series of demonstrations and hands-on examples, we will guide you through the process of creating a simple web project to give you a grasp of the power of AI tools. We then delve deeper into the concept of infrastructure as code (IaC) and teach you the basics of using Pulumi.
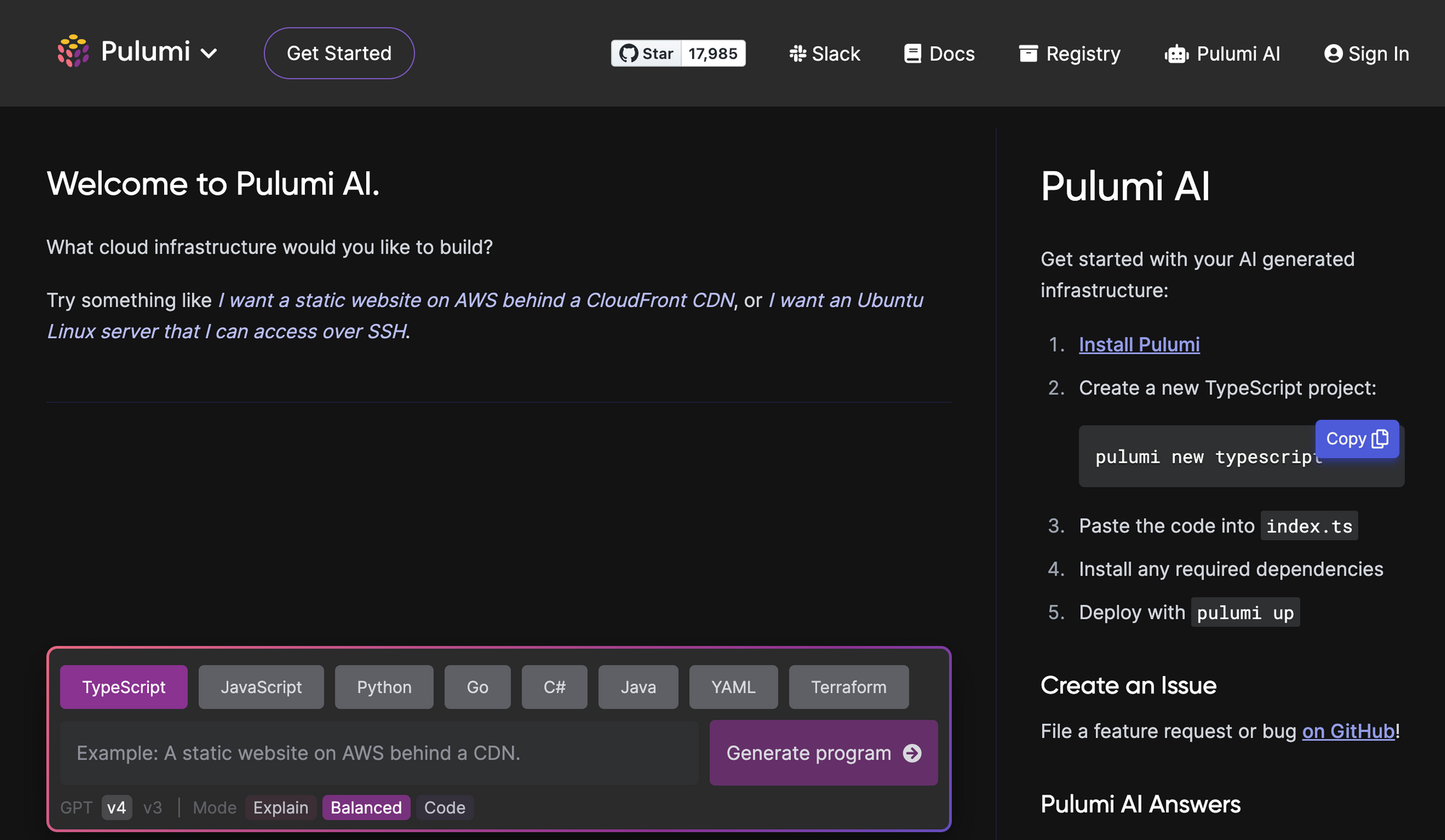 Pulumi AI web interface.
Pulumi AI web interface.
You will learn how to use Pulumi AI to develop infrastructure, even if you lack the technical knowledge of the exact steps involved. Additionally, we will demonstrate how AI can assist you in searching through all your infrastructure resources, simplifying the process of making updates.
Pulumi AI's adaptability to natural language inputs can dramatically increase productivity. For example, you can input a basic query like "Show me how to run nginx as an ECS Fargate task in the default VPC," and Pulumi AI will process the request and provide a solution that references the necessary AWS resources and providers. This adaptability showcases the power and convenience of using AI in the field of web development and infrastructure deployment.
Within the Pulumi ecosystem, there are over 130 providers. Some of these providers, like AWS, offer more than a thousand resources. On average, each of these resources might have around 30 configuration properties. Given the vast number of potential configurations, it can sometimes be challenging to set everything up perfectly. This is where Pulumi AI proves useful.
Watch the full course on the freeCodeCamp.org YouTube channel (1-hour watch).
Transcript
(autogenerated)
I'm Beau Carnes from FreeCodeCamp.org, and in this course, I'm going to show you how you can use AI to make it simpler to deploy infrastructure and websites.
When creating and deploying using infrastructure as code, it can sometimes be hard to keep track of all the configuration properties and what functions and commands you need to use.
Well, now artificial intelligence can help you with all of those things.
I'll be showing you how to use AI tools created by Pulumi.
Pulumi provided a grant to make this course possible.
First, I'll demonstrate how to create a simple web project so you can quickly grasp the power
of these AI tools.
Then I'll explain more about infrastructure as code and show you the basics of using Pulumi.
After that, I'll demonstrate how it's possible to use Pulumi AI to develop infrastructure,
even if you don't know the exact steps yourself.
And finally, I'll demonstrate how you can use AI to help you search through all of your
infrastructure resources to make it simpler for you to make updates.
Okay, let's get started.
I'm going to show you how to use the Pulumi AI to quickly spin up an S3 bucket and create
a website.
I'm just going to be showing a quick example right now.
But later in this course, I'll show you some a lot more complicated examples on how to
use Pulumi AI for infrastructure as code.
But right now I'll just do MPX, Pulumi AI.
Now I previously already set up Pulumi on my computer and also attached AWS to Pulumi.
I'll have a link to the instructions for how to do that in the description.
So now what what do I want to build?
Well, I want to build an S3 bucket.
And I can just use normal English.
It's also connecting to chat GPT or the open AI API to be able to handle plain English.
But then it also is able to connect with Pulumi.
And I just created a bucket.
If I go over to my AWS console, and we see the bucket, it's right in the console now.
Okay, now that we have the bucket, let's add something to the bucket.
So add an index that HTML file with a simple number guessing game.
Okay, now I'm just going to ask what is the URL.
Okay, now I can just copy this URL and access denied.
It's actually easy enough to fix I can go into my bucket here is just because of the
permissions they get set by default to block all public access.
So I'll just unblock public access.
And then I'll go to index that HTML set the permission of this.
And then we'll also go down here and do ACL enabled.
Then we can edit this.
So we'll have read and list and I figured objects we can make public using
ACL.
Now you may not have to do all that if you already had it set up beforehand.
So depending on how you have AWS set up, Pulumi can just make it public by default.
But if you don't have it set up correctly, like I didn't have it set up, you may have
to manually make everything public.
Okay, let me just go to the website again.
Now and this one, it just made it so I don't actually get to have to enter the number I
just have to keep cooking try it until we get the right number.
Actually I don't think that code is working at all.
So let's see if we can update the code, redo the complete number guessing game from scratch.
Now you're usually you're not going to be having it code something from this, you'll
be having it create infrastructure.
But I just wanted to kind of show this example of how we can actually create a code as well.
You're just going to experiment with it.
If you can actually create a website like this, then you could also have it say, Oh,
add styling, and then it can add extra styling to the website.
But now let's just move on to something else.
In this section, I'll give a brief overview of infrastructure as code.
After that, I'll review the basics of Pulumi.
And finally, I'll demonstrate how to use AI to simplify and streamline your infrastructure
as code.
Feel free to skip ahead if you already know the basics of infrastructure as code.
So infrastructure as code is the practice of managing and provisioning infrastructure
through machine readable definition files, rather than using physical hardware configuration
or interactive configuration tools.
In the era of cloud computing, infrastructure as code plays a pivotal role in ensuring that
infrastructure is consistent, repeatable, and scalable.
Traditionally, infrastructure was managed manually with system administrators configuring
each server individually.
As the scale of operations grew, this approach became inefficient and error prone.
The need for automation led to the birth of configuration management tools, and the concept
of infrastructure as code.
Here's some of the key concepts and principles behind infrastructure as code.
The first is idempotence.
This means the ability to run the same code multiple times without changing the result
after the first run.
The next concept is immutability.
Infrastructure components are never modified after they're deployed.
If changes are needed, new infrastructure is provisioned and old ones are discarded.
The final key principle is declarative versus the imperative approach.
While a declarative approach specifies the desired end state, like I want a server, an
imperative approach specifies the steps to achieve the end state, like create a server,
then install software x with infrastructure as code infrastructure changes are made in
a systematic, repeatable manner, reducing manual errors.
It also allows for version control, ensuring that all team members are working with the
same configurations.
Some of the popular infrastructure as code tools are terraform, which is a tool that
allows users to define infrastructure as code using a declarative configuration language
that is a proprietary domain specific language.
Ansible is an open source automation tool for configuration management, application
deployment and task automation.
Graph and puppet are configuration management tools that allow infrastructure to be defined
as code and automated.
Pulumi is an open source tool that offers the flexibility to use any programming language
for managing infrastructure.
This makes Pulumi widely accessible to developers and DevOps engineers from any background.
And we'll be talking more about Pulumi later.
Some of the best practices for infrastructure as code are to modularize configurations to
ensure they're reusable, regularly test and validate infrastructure as code scripts to
ensure they work as expected, and document configurations for clarity and future reference.
Let's just quickly look at a code example for infrastructure as code, we'll be going
through code more in detail later, I just wanted you to see that this is how you would
use Pulumi to set up EC2 instances in AWS using Python, the line for structures code
offers numerous benefits, it's essential to manage secrets securely, ensure infrastructure
security and handle potential infrastructure drift, where the actual state diverges from
the desired state, infrastructure as code is revolutionizing the way we think about
and manage infrastructure.
As the tech landscape continues to evolve, adopting infrastructure as code and staying
updated with its best practices will be crucial for organizations aiming for efficiency and
scalability.
Now let's take a deep dive into Pulumi.
So what is Pulumi?
Pulumi is an infrastructure as code platform designed for developers and cloud engineers
who want to use general purpose programming languages to define and manage cloud resources.
Unlike traditional infrastructure as code tools that use domain specific languages,
Pulumi allows users to leverage popular programming languages, such as go JavaScript or TypeScript,
Python, and dotnet platforms.
Pulumi works with traditional infrastructure like VMs, networks, and databases, in addition
to modern architectures, including containers, Kubernetes clusters, and serverless functions.
Pulumi supports dozens of cloud service providers, will be using Python and deploying on AWS,
though it can be done with other programming languages and cloud providers.
Let's look at the key components of Pulumi.
One is provider SDKs.
These are installable packages that your program consumes.
Pulumi supports over 75 providers with new ones being added regularly.
The command line interface is a tool that users can use to run previews and updates
on their infrastructure programs.
The service back end is the default state storage service for all Pulumi projects.
This stores a snapshot of the state of your resources, known as the checkpoint every time
you update your cloud resources using Pulumi.
So let's look at how Pulumi works.
It works by processing the code written in one of the supported languages and generating
a graph of the resources that need to be created, updated, or deleted.
This graph is then used to calculate the set of CRUD operations required to achieve the
desired state of the infrastructure.
Here are some of the key features, the component resources.
These are resources that encapsulate multiple child resources, allowing users to represent
several related resources as a single unit stack references.
This feature allows users to create multiple stacks and consume the outputs exported by
other upstream stacks.
Dynamic providers.
This feature serves as an escape hatch for when there's no official provider for a resource.
Automation API.
This API allows users to programmatically invoke CLI operations, enabling advanced deployment
scenarios.
Pulumi insights brings intelligence to cloud infrastructure using Pulumi.
It includes features like Pulumi AI, which is a generative AI assistant built to create
cloud infrastructure using the natural language, and Pulumi resource search, which offers multi
cloud search and analytics across every cloud resource and environment and organization.
Soon I'll be showing how to use both of these tools.
With the introduction of new CLI commands, Pulumi insights is now more accessible to
users, allowing them to leverage AI and resource search directly from the terminal.
Pulumi's program model starts with the Pulumi project at the outermost layer.
However, users don't often interact directly with these projects.
They're typically created when initializing a Pulumi program and tend to disappear when
the last stack within the project is destroyed.
Inside the project, there is a program, which is the main entry point for the program.
If you're using TypeScript, this is index.ts.
So that would be the program, the main program.
This is where we define our infrastructure.
The infrastructure is characterized by Pulumi resources.
An example of a Pulumi resource is an AWS s3 bucket.
Such resources have been have both inputs and outputs.
For instance, specifying a bucket's name would be an input, while the buckets Amazon resource
name or ARN would be an output.
A reoccurring pattern you'll notice in a Pulumi program is how the output of one resource
becomes the input for another.
If you have an s3 bucket and wish to define a policy for it, the ARN output of the bucket
will serve as an input to the bucket policy.
Behind the scenes, Pulumi manages the dependencies between these resources, ensuring they are
set up or taken down efficiently.
It also keeps track of the sequence in which operations need to be executed.
In addition to the program, there's also the concept of stacks.
A stack is essentially an instance of your Pulumi program, with the added flexibility
of supplying different configuration values for different instances.
This is useful when you want to have separate setups for development, QA and production
environments.
For instance, in a development environment, you might opt for fewer or less powerful EC2
instances compared to a production environment.
This differentiation is achieved using stack configuration.
Discussing Pulumi's physical architecture at the foundational level, we have our Pulumi
programs.
These programs can be written in various languages, such as Python, TypeScript, JavaScript, Go,
C sharp, F sharp, and Java.
Pulumi also offers support for GAML, mainly for larger organizations transitioning to
Pulumi at scale.
These options caters to those with traditional operations, with traditional operations experience
who might find it more comfortable working with YAML than with standard programming languages.
The Pulumi engine interprets your Pulumi program.
The Pulumi engine works by comparing your Pulumi programs desired state with the existing
state as recorded in your state file, it identifies the discrepancies between the two and determines
which resources need to be created, updated or deleted.
This process is facilitated through Pulumi providers.
For instance, in our example, we mentioned the Pulumi AWS provider and the Kubernetes
provider.
These providers offer support for a multitude of public clouds, software as a service providers,
and other platforms.
This vast array of providers ensures that users can leverage Pulumi's declarative approach
to manage resources across a broad spectrum of services.
Now we'll give a brief example on how to use Pulumi.
And then we'll see how to use the AI features.
We'll start with a blank directory, and we'll initialize a Pulumi program using the Pulumi
new command.
Upon executing this command, there's a lot of templates are displayed.
There's a bunch, there's 221.
And I'm going to just go to the static website, AWS TypeScript.
So this is just a TypeScript program to deploy a stack website on AWS.
So I'm going to put TypeScript AWS for the project name, default project description
default stack name, I'll just use this region, which is actually pretty close to me us West
two.
And the rest of this will just keep as default.
So these prompts are specific to this template, because it set up sets up a static site.
Post initialization, the system runs an NPM install, which will be familiar to anyone
experience with node.js.
Now after installation, our project directly directory reveals several files and folders,
we have a node modules folder, where node.js stores dependency, www folder created by the
project to house our website files, the git ignore file.
But first, let's discuss the Pulumi dot yaml file.
This file contains project configuration details.
Remember, when we use the Pulumi new command and provide certain inputs, well, those responses
are saved in this file.
Additionally, we have a Pulumi dot dev dot yaml, which is the stack configuration.
We're deploying our static site to different regions, we can create separate stacks with
their respective configuration files.
So let's move on to the index.ts file, let me move that down here.
This is the core of our Pulumi program.
It begins with importing libraries, like the the Pulumi SDK, and which allows us to access
our values from our configuration file, and also the AWS provider, which it's going to
create AWS resources, and a Pulumi component called sync folder to synchronize a folder
with our object store.
This file also demonstrates the pattern of using the output of one resource as the input
of another resource.
So I'm not going to go through this file in complete detail, but you can see how it's
creating a three bucket.
It's configuring the ownership controls, configuring the ACL block, and it's using the sync folder
that we talked about, creating a Cloudflip CDN to distribute the the CAS on the website.
So this is just the template, and we can basically modify this template, how we want.
And then it's just going to export the URL and host name to the bucket and distribution.
In this example, and s3 buckets details like its ownership controls might reference another
resource.
The file this file proceeds to define various resources related to the bucket and set the
sync folder to mirror the content of our www folder with the s3 bucket and establishes a
cloud front distribution.
And then, like we already talked about here, this is when it ends with defining the stack
outputs using a standard TypeScript export statement, allowing external access to certain
values from our Pulumi program.
So to see the see the impact of the configurations, we will use the Pulumi up command.
So let me go back to the console here.
And we'll do Pulumi up.
This stands for update, the command previews the changes before our actual execution, ensuring
that we're aware of the actions Pulumi plans to take.
So this is where it will confirm whether we want to perform the update.
And I'll go to Yes, that is what we want to do.
So after we get this all done, we can check the website.
So here's the URL.
And I'm just going to follow the link.
And it works.
Hello, Pulumi or Hello World deployed by Pulumi.
Let me show you one more thing really quick.
Let's see what happens if I make a change.
So like for instance, I can go here and I'm going to change the default TTL to 300.
And then I'll just save that.
And then I'll just do Pulumi up again.
And you'll see that it will not recreate every resource.
It only makes the update.
This is what it means that Pulumi is declarative.
I'll say do you want to perform the update?
You just say your desired state and Pulumi will figure out what needs to be updated.
And then finally, we can use the Pulumi
destroy if I can spell it right, destroy command to tear down the resources.
That way we won't incur any more charges.
So yes, I do want to destroy this.
And that will just bleed everything off of AWS.
So if I just go back to the page and refresh, there's nothing there, we get the 403 forbidden.
So now I'm going to go to a different page, Pulumi.com slash AI.
We're going to talk about Pulumi AI.
Pulumi AI is accessible at Pulumi.com slash AI.
It's free for everyone to use.
Within the Pulumi ecosystem, there are over 130 providers.
Some of these providers like AWS offer more than 1000 resources.
On average, each of these resources might have around 30 configuration properties.
Given the vast number of potential configurations, it can sometimes be challenging to set everything
up perfectly.
This is where Pulumi AI proves useful.
So to demonstrate, I'll just put a basic prompt here, I'm going to say show me how to run
nginx as an ECS for gate task in the default VPC.
So this is a natural language prompt.
And you see, I just I chose TypeScript as the preferred language, but I could have chosen
a different language.
And you can see it's just generating the program.
It took a minute to process.
You can see often begins the response by echoing the initial prompt or question that creates
an internal feedback loop, which enhances the quality of the solution provided.
And we can see everything that it suggests, like using the ECS cluster, it creates an
ECS task definition.
And that creates a Fargate service.
And it basically goes through and does what we asked it to do.
And then it basically summarizes what it's going to do.
And then it just gives you some some different things that you can change, you can place
nginx latest with any Docker image of your choice, it's been in your own AWS account,
and then just kind of explains it even more.
So we can just copy this.
And then I can put it right into here.
And then you can see there are some some squiggly lines here.
So this is an iterative process.
Basically it's not uncommon to encounter some errors.
And these tools while powerful might not always yield perfect results.
So users should expect some degree of iteration and refinement.
So I can look right here says property quick.
So I can actually just copy this.
And I will bring in here, I'll say error, and I'll just paste in the error.
And now it's going to fix it for me, it's going to update it.
And it realize it realizes that in more recent versions of plume, the test definition should
be created differently.
Okay, so now let's copy this updated code upside did not copy it right.
Let's try it again.
Click that copy button.
Okay, so now we don't have the red squiggle lines there.
And you can see we can just go through that with all of it and just telling it what's
wrong and having it fix having it fix the error.
So basically, we can go back and forth it like I said, it's an iterative process.
And while it may not produce flawless results on the first try, they can provide an excellent
starting point, often around 80% accurate, which significantly reduces the time and effort
required.
These tools are especially beneficial when tasked with recalling specific configurations
or procedures that aren't routinely used.
For example, if one needs to draft an IAM policy to access a secret, but doesn't remember
the exact steps, tools like plume AI can provide a quick and accurate solution.
Plume AI is a powerful tool that can significantly expedite the learning and applications of
coding tasks.
So now let's try a more complex example.
And then we'll follow through to creating the actual resources here, here, we're not
going to actually run this program, but this next one, we will.
So let me go over here, and I'm just going to create a new conversation by just going
to plume.com slash AI again.
So now I want to create a serverless function chain.
Basically, I want to deploy a series of serverless functions that trigger each other in a specific
order.
Basically, AWS lambda functions that trigger another lambda function and so on.
So the kind of architecture I'm looking to create is ideal for sequential tasks, where
one processes outcome determines the subsequent processes input.
Now we're just going to do a very simple function change, it wouldn't be like it's not going
to be like a real world situation.
But I can give you an example of what you can do with plume AI function chains are what's
sometimes called function pipelines or sequences, can streamline multi step processes by allowing
the output of one function to serve as input to the next, some some like real applications
that if they're used for would be an e comms order processing, where stages like order
validation payment and inventory updates occur sequentially, and data data analytics, where
raw data undergo stages of cleansing transformation and analysis.
Also maybe like user registration workflows, document approval systems, financial transaction
monitoring.
So when you have a modular workflow, it can offer flexibility, scalability and ease of
troubleshooting as each function can be just individually managed and optimized.
So like I said, artists, this could be a simple function chain, the first function will check
the character count.
If the character comes correct, the second function will be triggered, which in the second
function will turn all the characters to capital letters and trigger the third function, which
will save the text submission.
So the truth is, I don't even even though it's simple, I don't personally fully know
how to do this.
So we're going to use plume AI to help us.
Okay, so let's see if let's just try this and see if we can figure this out.
So I'll say, help me create a lamp and AWS lambda function chain that processes text.
The first function will check character count, if the character count is more than 50 and
less than 1000, then the second function is triggered.
The second function will turn the characters to capital letters and trigger the third function.
The final function will save the text on AWS.
Okay, let's just see what it can figure out from this instruction.
Okay, it's creating a chain of AWS lambda functions that can describe text processing
operations, checking the length of the string, transforming the text and saving the result
to an S3 bucket.
So it's going to even develop the program structure create three AWS lambda functions.
Each function is written in JW and embed directly in the plume program.
So we don't have to store them elsewhere, create an API gateway to serve as a trigger
to start the lambda function chaining upon request the API gateway, the first lambda
execute to check the length of input text, things advocate, the link circuit invokes
a capitalizer function that converts the characters to uppercase and the capitalizer function,
invokes the saver function that saves a modified text on S3 bucket, then the final URL to trigger
the workflow is exported.
Okay, so that's exactly what we wanted.
So let's see what it came up with.
So we have the link checker lambda, and it's going to create that.
You can see it's checking for the length of the use of the 50 and the 1000, just like
we said, and then it's going to invoke the capitalized it's going to invoke the capitalizer
function.
So let's see the capitalizer the capitalizer lambda function.
It's going to do the two uppercase, there's gonna invoke the saver function.
The saver function is going to save to an S3 bucket, it may not work exactly right at
the first try.
But let's just check that and copy the code.
I'm just going to paste it right in here.
And then just try to figure out what the errors are.
So I can actually just copy this error here.
And it says the argument of type runtime is not assignable to a parameter of type function
args.
Okay, so let's just copy this error.
And then we're going to go back over here.
And I'll paste it in.
So let's see what it figures out.
It knows that we need the role properties specify the IM role.
And the AWS lambda assumes when it executes your function, let's add a new IM role for
each of your lambda functions.
And that sets up the IM permissions.
Okay, we may have to do some more permissions, change the permissions within AWS as well.
But let's try this.
Okay, so now it's not, we don't have as many red squiggly lines.
So oh, okay.
We Okay, I see there's something wrong here, because it's assuming it says the rest of
your lambda configuration here.
So I'm going to go back here.
Then you output the full code that I need.
And then I'll say
do not just say
actually put the config the config.
Now we could probably I think I just need to combine these two codes together, which
I could do manually.
But I'm going to see if it can do that.
I'm going to skip a little of the back and forth.
So you can see the result.
This is an iterative process to get to the correct code.
And I came into this knowing very little about how to implement this project.
It was so much quicker using Pulumi AI.
Okay, so we have the URL here 123.
My name is Bo.
My name is Bo.
And let's see if it works.
Okay, we got the link here.
But let's see if the capitalized words are now stored in our s3 bucket.
Okay, here's our bucket and file at txt.
Let's download it.
And it worked.
See I just added that 123 and all the letters are in capital letters.
We did it.
We made a function chain from one to the other to the other.
And again, I had never done anything like this before.
But I was able to use Pulumi AI to figure it out.
This is awesome.
And now I feel so much more empowered to be able to create basically any sort of infrastructure
as code.
Now that I have Pulumi AI to help out.
Now let's see how we can search through our infrastructure resources and how AI can make
the process easier.
So after you've created tons of stacks and resources, it can become it can become challenging
to manage and keep track of them all.
So let me show you how that can become easier.
Well, here's the Pulumi cloud dashboard.
And you can see it's going to show me members are in the organization, you usually have
more than one number of stacks, and then the number of resources for big organizations,
the number of resources can be 1000s or even hundreds of 1000s of resources, which can
lead users to question the relevance of these resources or what the origin is, or whether
you need to clean some of them up.
So we can use the resource, the resource search feature.
When you're managing a large organization with many individuals working on various stacks,
the research, the resource search feature is invaluable.
When you're on this, this main dashboard, you can see the overview I was talking about,
you can even see like when the last stack was updated.
But if I click on resources, then we can search through all the resources.
So you can see it just has a list of all the resources on every stack.
And there's just a bunch of them.
And I can just search for things, like I can search for API, and then it will show everything
that has the has API in it, or I could search for
Kubernetes just brings up one thing that's related to Kubernetes here.
And you can search for things by name, kept tall wiser.
And we can see all the functions that have all the resources that have the word capitalizer.
We also have the advanced filtering.
This provides aggregate information about resources, we can search by various criteria,
like I can do everything that has to do with AWS, or this will make it look a little better.
I can do everything that has flu providers AWS.
So that's the type.
And then I can say all that type in this project.
And so I can further narrow down based on the type, the packages, projects, or the stacks,
and you may have a lot more depending on how many resources you have.
So the search function is very, is very versatile.
I'll just look for all the lambda functions.
So the powerful search syntax allows you users to make very complex queries.
But there's also an integrated AI assistance.
If I click here, I can switch using Pulumi AI.
And this can help users craft queries, which makes the search process even more user friendly.
So I can say something like all my s three buckets.
And then you can just tell things using just a conversational English.
Or I can say something like, which are part of my lamb, the function chain.
And it seems to get quite a lot, frankly, I don't even know how it knows that these
are part of the Lambda function chain, but it seems like it got a lot of them.
On the user interface, there's also a robust API for those who wish to build automation
and tools around the Stata.
The system also understands user permissions.
So as an organization admin, I can view all the resources.
But for larger organizations with specific permission requirements, users will only see
resources they have access to.
This ensures security and privacy while still providing valuable insights.
So all these tools help provide users a comprehensive and manual view of their Pulumi resources.
Also if you have your own data warehouse and business intelligence tools, you can integrate
data with Pulumi tools with your existing data solutions.
Okay, we've reached the end of the course, you should now be able to start using AI to
create infrastructure more easily.
Thanks for watching.