
By Dan Ruta
The original motivation for this side-project was finding a better way to save and load weights trained by a browser based neural network, while developing jsNet. To save weights, as JSON, I would have to log the content out, in the console, or on the page, and as you can imagine, it got pretty bad when the networks got big and there was a lot of data.
The solution I came up with was to encode the data as images, which are handled much better than plain JSON text. Inadvertently, the algorithm I used to do that seems to not only have worked pretty well, but the eventual file size was just as small as gzip compression, even actually beating it in most cases.
So I thought I’d polish and release it as a standalone library, for general use. This article serves as an overview of the compression algorithm, for those who are into that sort of thing.
The Algorithm
Without further ado, a brief, high level overview of the array to image conversion is as follows:
- The numbers are converted to base15, with the first few characters being metadata
- The results are concatenated
- Every pair of hex characters is then converted to a Uint8Clamped value
- Finally, this is drawn to a canvas, then either returned (browser), or saved to a file (nodejs)
As for the conversion from an image back into array data:
- The image is read either from a file, a Uint8ClampedArray, or from an img HTML element
- Each value in the Uint8ClampedArray is converted to base 16
- Once concatenated into a string, the output is split along the metadata “f” character
- Each hex string is then parsed back into a number
Extra, optional normalization steps can be taken before and after conversions, to potentially further reduce the amount of meta data, and therefore file size.
The meta data
If the numbers were converted to base 16 (0 to f), which is what images use, there’d be no way to differentiate separate values, once concatenated. Therefore, they are converted to base 15 (0 to e), and the f character is used as a delimiter, to separate values.
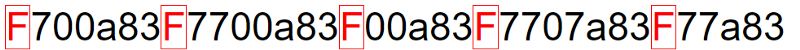
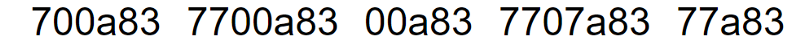
From here, a bit more meta data may be needed for other things. But from now on, this can be represented as base 15, as it’s at the start, meaning we don’t need any more meta-only characters.
Positive or negative
The first extra bit of meta data needed is whether the number is positive or negative. It would be a waste, however, to use up an entire character just for a binary value, so this is merged into the meta data for how many base 15 characters store the left side of the number (left of the decimal place).
See the Configurations section below for more, but by default, a single character is used to encode both, like so:
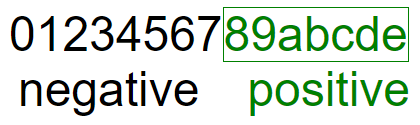
Values at 7 or below represent negative a number, whereas the rest represent a positive number.
Number of base 15 chars for left side
Moreover, each of the values represents how many of the base 15 characters are used for representing the left side of the decimal place.
So for example, 3 represents a negative number, with 4 digits on the left, like -1234.xyz. And a represents a positive number, with 3 digits on the left, like 123.xyz.
The number of leading decimal zeroes
Finally, by default, the number of leading zeroes in a decimal value is stored. Again, see the Configurations section below, but by default, 1 character is used, allowing for 15 leading decimal zeroes, like 0.0000000000000001.
So, with default configurations, the value 1430.01623 would get converted into the following:

‘F’ is the delimiter, ‘a’ represents a positive value with 3 characters (655) representing the left part of the decimal place, the ‘1’ represents 1 leading zero, in 1430.01623, and the rest represents the actual value. The first 3 characters, ‘655’ are converted from base 15 into 1430, and the rest, ‘733', is converted to 1623. The result is concatenated, with the leading zero added in.
Configurations
By default, only 1 meta character is used for encoding how many hex characters are used for representing the left hand side of the decimal place (655 => 1430, in the above example). This places the limit at a maximum hex value of eeeeeee, which is 170859374 in decimal. Though it should be enough for most cases, it is still possible to represent more, by simply using 2 characters.

In this scenario, positive numbers are stored as anything above 112, and negative numbers being anything below. This means there’s a theoretical maximum of 113 hex characters that can represent the left side of the number, aka 7912473587054163204202262246064660222224606482062446620828868288862844044480028440444220620006824802826420808608284080640028606608644. Though, in practice, parseInt rounding gets funny after 15 characters, so 999999999999999 should be a stopping point.
But, to save even more space, this configuration can instead be set to 0, to completely disregard this metadata, if you know for sure that the numbers are positive, and within the 0–1 range (you can always normalize/un-normalize it using the included helper functions). So, 0.123 would get converted into:

Where ‘83’ is the hex conversion of 123. There is no character stored for the left hand side of the decimal place, as the number is assumed to be 0.
Finally, the metadata character for leading zeroes can also be toggled, for when your data consists of integers, or at most, decimals without leading zeroes. Turning it off for the above example would yield:

This is the minimal configuration, and with some data pre-processing, it can help to greatly reduce the file size.
Benchmarks
The two most interesting formats were PNG and WebP. Both can be saved from a canvas, and both can use the alpha channel, meaning they are quite easily interchangeable (at least in the browser version).
As the initial problem I was solving was neural network weights, the first set of benchmarks was of weights from 3 neural networks, each one quadrupling in size, to test scalability, as well, which seemed unaffected. The configurations were left as default, not optimised.
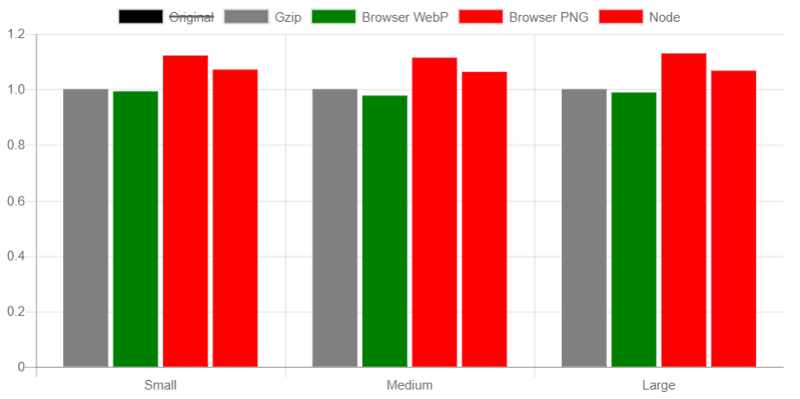
The PNG format does the job, but WebP actually beats gzip! Just about… at 98.5% of the size, from these 3 tests. Using the alpha channel did not help reduce the file size, but it did reduce the size of the image, in pixels, so it was left as a toggle-able configuration.
The next set of benchmarks is for the capacity config. For this, and the following set of tests, I created a random array of numbers in the 0 to 1 range, with 1 decimal place, eg: 0.1, 0.4, 0.7, 0.2, and so on, to make sure the data was valid for any configuration, and tested the PNG and WebP variants, from the browser output. 80000 numbers were used for this benchmark.
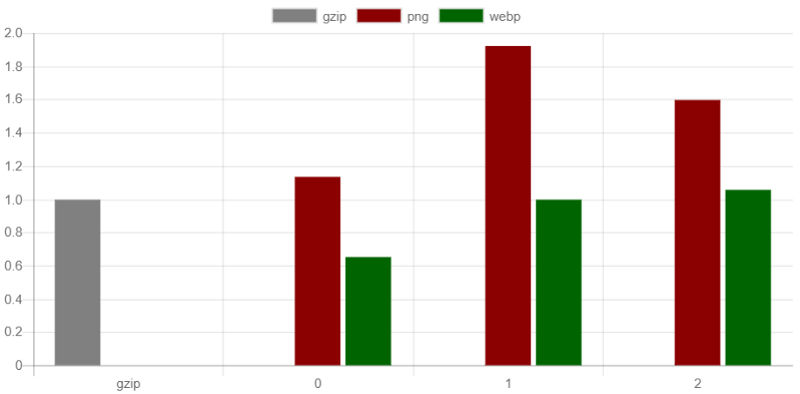
WebP quite easily beat the PNG format, and even gzip, when the capacity was set at 0, equalling it when set to 1, and slightly larger when set to 2.
Finally, the sizes were compared for the leading decimal zeroes configuration, for each capacity configuration, for the WebP format. This time, a set of 500'000 numbers was used, of the same type as above.
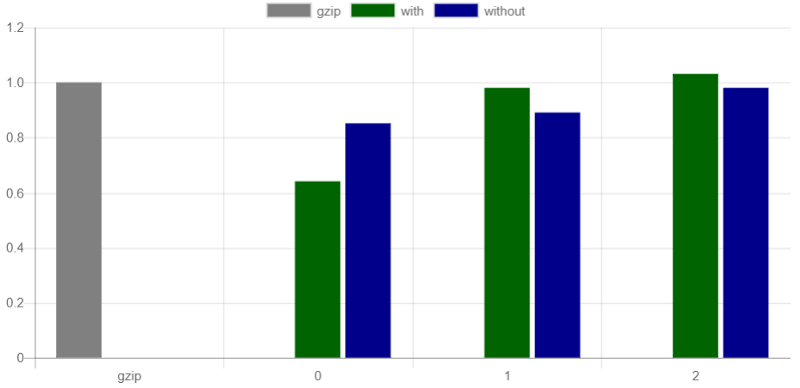
This particular config seems to actually do worse on the smallest capacity configuration, but slightly better on the rest.
My takeaway from these tests is that if the data is normalized as a pre-processing step, and you can use the WebP format, there is potential for much better compression. You also get some pretty cool images:



The benchmarks files can be found in the repo, on GitHub.
So what’s next?
Contributions are always welcome, as I’d love to improve this, and get the file size even smaller. In the future, when I or someone else gets time, this may get ported to WebAssembly, for the potential conversion speed gains.
Other things that might be worth adding could be an ‘auto’ config, to determine all the configurations automatically, by looping through the data first, to see what’s actually needed.
And finally, to avoid having to keep track of the configurations, for use when parsing back the image, all configs could be stored in the encoded output, as ‘header’ pixels, behind an FF delimiter.
But for now, to conclude, here is an image of the weights for a neural network trained to recognize hand written digits (MNIST). Assuming Medium doesn’t apply any compression of their own, you should be able to load it using jsNet, in a 784–100–10 structure, and have a trained model, all from a PNG image!

The GitHub page for this is here and my Twitter is @Dan_Ruta.