
By Alberto Gonzalez Rosales
I've been a competitive programmer for many years. And during that time, I have faced the process of debugging on numerous occasions.
In this article, I will try to describe how debugging works in such environments, instead of depicting it in the regular software development activities we do every day.
But why? You might ask.
The reason is that, because of the short time limit set in these competitions, the participants have to come up with creative ideas to solve all the issues they face. There is no tomorrow for them. It is either "crack or go home".
And sometimes, these ideas can be extrapolated onto the so-called "real world" software development.
Without further ado, let's see what I'm talking about.
Some Context
Competitive Programming contests are a type of competition in which every contestant gets a set of problems. The idea is for them to solve the maximum number of problems they can within the time limit set for the contest, which is usually around two to five hours.
Every problem specifies the format of the input, and it expects some output in response. For example, we could have a problem stating that you need to find the sum of the numbers in a list. In this case, the input would be a list of numbers, and the output would be a single number.
Usually, these competitions take place on automated platforms that can receive solutions for every problem and evaluate those solutions against an entire dataset hidden from the competitors. If a solution returns the expected value for every dataset, it is said to be "Accepted", otherwise it is "Rejected".
As you can imagine, crafting and submitting accurate solutions is an important skill for every participant, but so is being fast. Finding the right balance between correctness and speed is what makes a competitor rise to the top of the standings with more problems solved than their rivals.
Not so far from "real life", isn't it?
It is common to see software companies fighting each other to see which one is the fastest to achieve certain goals or which one gives better results when looking at some particular topic. The balance between doing something right and doing it fast is always critical when working in software development.
And here is where debugging shows up as a key factor, because:
- It ensures correctness once the "bugs" have been dealt with.
- It can affect speed if the process of finding errors takes too long.
Let's see what actually happens during competitive programming contests, then!
The "Bug" Strikes Back
When participating in programming contests, bugs often appear when performance is a defining factor in the solution to a problem. That is, not only is the correct output taken into account, but also how much time your solution takes to return that output for the entire dataset.
The following case is the most common one:
We read a problem, and we know a solution that solves that problem correctly. But unfortunately, it won't be fast enough. No worries, we think about the problem some more and we came up with a solution that is also correct, but this time it will fit in the time limit set for the problem.
We rush into coding our solution, test it a little with some manual test cases, submit it, and... end up receiving a "Rejected" verdict. Which means our solution returned the wrong output for some input.
What do you do in this case?
The approach that most competitors take is to keep testing their solutions against some hand-crafted test cases they come up with. They try to look for edge cases where the solution might return the wrong output, but this is not always easy to do.
The frustration of seeing your program return the correct output for every input you give but knowing there is some hidden test case in which your solution fails can lead you to stop trying a problem that you are almost certain you know the solution to.
This will, of course, impact your performance in the competition because you invested time in a problem you will not end up solving.
So, when the debugging process is taking too long, it is a good alternative to go for the "have the computer find the bugs for you" approach.
Let's see how this works!
Debug Smarter, Not More
First of all, of course, the computer won't find the bugs for you. The bugs are your own and you will be responsible for finding them. But, what the computer can do is help you generate enough data in a short time to help you find where your solution fails.
Remember that solution we talked about that would give the correct output but wasn't fast enough? Now it's time to make use of it.
Usually, this solution will be easier to code, and less prone to having bugs in it. Let's say we can rely on it because we know we are skilled enough to solve any problem using a no-brainer approach.
Do you recall the previous debugging process?
- Generate hand-crafted input.
- Run your solution with that input.
- Manually check if the output returned is correct.
- If it is not correct, you have a test case to debug thoroughly. Otherwise, repeat step 1.
This is highly inefficient for a person to do. Especially steps 1 and 3.
What we can do to speed up this process is to change the checks that we do in step 3 to be automatic instead of manual. And the easiest way to do it is by comparing the outputs returned by both of our solutions (the no-brainer and the buggy) given the same input.
If we coded our no-brainer solution right (which we are skilled enough to do, of course) then we can ensure that the moment the outputs differ, we have found a test case that is worth having a deeper look into.
Ok. But what about step 1?
The process of generating test cases can be difficult, especially if what we are trying to do is to find one that makes our solution return the wrong output. I mean, if we were able to do that easily then we would have fixed our solution already 😅.
Fortunately, the solution for this issue is to rely on randomness. Yes, you heard me correctly. Randomness provides a spectacular way of generating non-biased input and it works surprisingly well and fast in most cases.
We can replace our hand-crafted process of creating test cases with an automated, easy-to-code, random process that will do the work for us.
Now, the debugging process will be:
- Generate random input.
- Run both solutions with that input.
- Check if the outputs differ.
- If they do, you have a test case to debug thoroughly. Otherwise, repeat step 1.
The difference between both approaches is that the second one can be fully automated, and we will see how to do it next.
Automated Debug Mode
Let's automate our debugging process, then!
We will start with this template code in Python, which we will be filling up with the proper code to help us achieve our goals.
def no_brainer():
pass
def solution():
pass
def generate_input():
pass
def debug():
pass
if __name__ == "__main__":
debug()
The purpose of this implementation is to have the debug function generate a new test case by using the generate_input function, and supply it to our solution and our no_brainer solution while the results are the same. The moment the results differ, we can stop generating new test cases and analyze the one that makes our solution fail.
A real example
Let's make it more interesting by solving a classic algorithmic problem:
"Given a sorted array of integers, and an integer x, find the first index of the array containing the number x, or return -1 in case the number doesn't appear in the array".
Now, because we are smart, we know how to solve this problem by using a linear search over the array. The implementation in Python could be something like this:
def no_brainer(a, x):
for i in range(len(a)):
if a[i] == x:
return i
return -1
This is our no-brainer solution. Just a plain for-loop until we find the element we are looking for. The moment we find it, we return the index in which the element can be found. And, in case we don't find it, we return -1, as requested in the problem statement.
Let's assume this solution is not fast enough. Maybe it is because the size of the array is too big and, in the worst case, our solution will end up iterating through all the elements just to find out that the number we were looking for is not present in the array at all.
But, since the array is sorted maybe we can use the Binary Search algorithm, which will indeed speed up the search process. That sounds like a good idea, right? Let's try it!
def solution(a, x):
l = 0
r = len(a) - 1
while l <= r:
m = (l + r) // 2
if a[m] == x:
return m
elif a[m] < x:
l = m + 1
else:
r = m - 1
return -1
The code above tries to find the number x in the array, and it also returns -1 in case it doesn't find it. Now, it doesn't perform a linear search so we are not expecting it to time out but for some reason, when we submit it for review, we receive a "Rejected" verdict.
As we said before, we will not rush into manual debugging. Instead, let's start by creating a random generator to supply input to both our solutions, hoping we will find the bug soon. Our generating function could be something like this:
import random
def generate_input():
n = random.randint(1, 10)
a = [random.randint(1, 10) for _ in range(n)]
a.sort()
x = a[random.randint(0, n - 1)]
return a, x
We are generating arrays with sizes at most 10, which is a manageable number of elements. We are also making sure the elements are sorted, and we are taking the number x as one of the numbers present in the array.
What we are missing now is just putting all the pieces together, like this:
def debug():
test_cases = 10000
for _ in range(test_cases):
a, x = generate_input()
no_brainer_output = no_brainer(a, x)
solution_output = solution(a, x)
if no_brainer_output != solution_output:
print("Test Case:")
print(a, x)
print("Solution Output:", solution_output)
print("No-Brainer Output:", no_brainer_output)
exit()
print("All test cases passed succesfully")
By having a glance at the code we can see the benefits of having this as part of our debugging process.
Notice that we have set a limit of 10000 test cases. That amount is not realistic for a single person to generate, and it sure seems like a sufficiently large number that might ensure we will find a test case where our solutions differ.
On the other hand, once we have fixed our solution, we can run these 10000 cases again looking for new bugs. The moment all the outputs are the same we would have a stronger belief about the correctness of our algorithm after passing that many tests.
This is the complete version of the implementation, in case you want to see the whole picture:
import random
def no_brainer(a, x):
for i in range(len(a)):
if a[i] == x:
return i
return -1
def solution(a, x):
l = 0
r = len(a) - 1
while l <= r:
m = (l + r) // 2
if a[m] == x:
return m
elif a[m] < x:
l = m + 1
else:
r = m - 1
return -1
def generate_input():
n = random.randint(1, 10)
a = [random.randint(1, 10) for _ in range(n)]
a.sort()
x = a[random.randint(0, n - 1)]
return a, x
def debug():
test_cases = 10000
for _ in range(test_cases):
a, x = generate_input()
no_brainer_output = no_brainer(a, x)
solution_output = solution(a, x)
if no_brainer_output != solution_output:
print("Test Case:")
print(a, x)
print("Solution Output:", solution_output)
print("No-Brainer Output:", no_brainer_output)
exit()
print("All test cases passed succesfully")
if __name__ == "__main__":
debug()
After we run this script, we will get a result like the following:
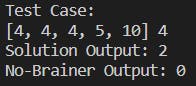
In this case, the input consists of the array [4, 4, 4, 5, 10] and the number 4. This means we need to find the first index where the number 4 appears in the array.
As you can see, our solution using binary search returns the value 2, which is an index where the number 4 is present, but it is not the first one. On the other hand, our no-brainer solution returns the value 0, which is the first index whose value is equal to 4.
And, just like that, in a matter of seconds, we have generated a test case that shows that our solution fails. Now we can proceed to analyze it thoroughly and fix our code.
Note: As an exercise for you, I will skip the part where I explain what is wrong with the implementation above. If you realize what the issue is, let me know so we can start a discussion and keep learning as a community.
A possible fix to our implementation is the following:
def solution(a, x):
l = 0
r = len(a) - 1
pos = -1
while l <= r:
m = (l + r) // 2
if a[m] >= x:
pos = m
r = m - 1
else:
l = m + 1
return pos
Let's see that when we run the script, now that we have modified our solution, we get the gratifying result:
![]()
Which will give us the courage to submit our implementation again.
Conclusion
In this article, we have seen an effective approach for generating test cases to stress-test our solutions. We have automated the process of crafting each case and checking for correctness, making it less time-consuming to find bugs in the code.
The approach seen here is one of the most effective ones used in Competitive Programming, but it sure can be extrapolated to use cases in "real world" software development.
It also shows how you can take advantage of the computing power present in the devices we use every day to speed up the debugging process and deliver features that have been tested thoroughly while still being able to beat your deadlines.
During my Competitive Programming journey through college, I implemented this type of debugging not only in individual competitions but in team contests as well. As a result of that, my teammates and I gained speed when competing and were able to achieve amazing results.
We all agree that this method of debugging played an important role in our achievements as competitive programmers. We went all the way from programming enthusiasts to ICPC World Finalists by making sure that we were the most productive we could be during the limited time we had in every contest. And I assure you: there is no contest without debugging.
I recommend you give it a try. Let me know your results!
👋 Hello, I'm Alberto, Software Developer at doWhile, Competitive Programmer, Teacher, and Fitness Enthusiast.
🧡 If you liked this article, consider sharing it.