
By Matt Morgan
Event-driven architecture is a software design pattern where components or services perform actions in response to events, often asynchronously.
This post serves as a companion to our video course, "Deep Dive into Event-Driven Architecture on AWS." In the course, we delve into some of the core fundamentals of event-driven architecture on AWS in detail.
This blog post complements the video course by closely examining a practical example: modernizing our Warehouse Inventory Management System (WIMS) application. Learn more about Matt Martz and his work at martz.codes and explore Matt Morgan's insights at mattmorgan.cloud.
You can watch the full video course on the freeCodeCamp.org YouTube channel (1.5-hour watch).
Why refactor?
Most builders understand that nothing beats speed to market. All of us can think of applications that found success in spite of, not because of, their system architectures. Once the system gains momentum and users, imperfections can really stand out, and then it's time to refactor. Sometimes the system is replatformed to something more scalable and performant. Sometimes it's rebuilt from the ground up. This blog post will demonstrate how to adopt event-driven architecture, the problems it can solve, and some of the great tools that AWS has to offer in this space. Let's get started!
WIMS v1
Our fictitious business application manages a warehouse full of MacGuffins. We're going to focus on a part of the system that handles order intake. It can be represented with this architecture diagram:
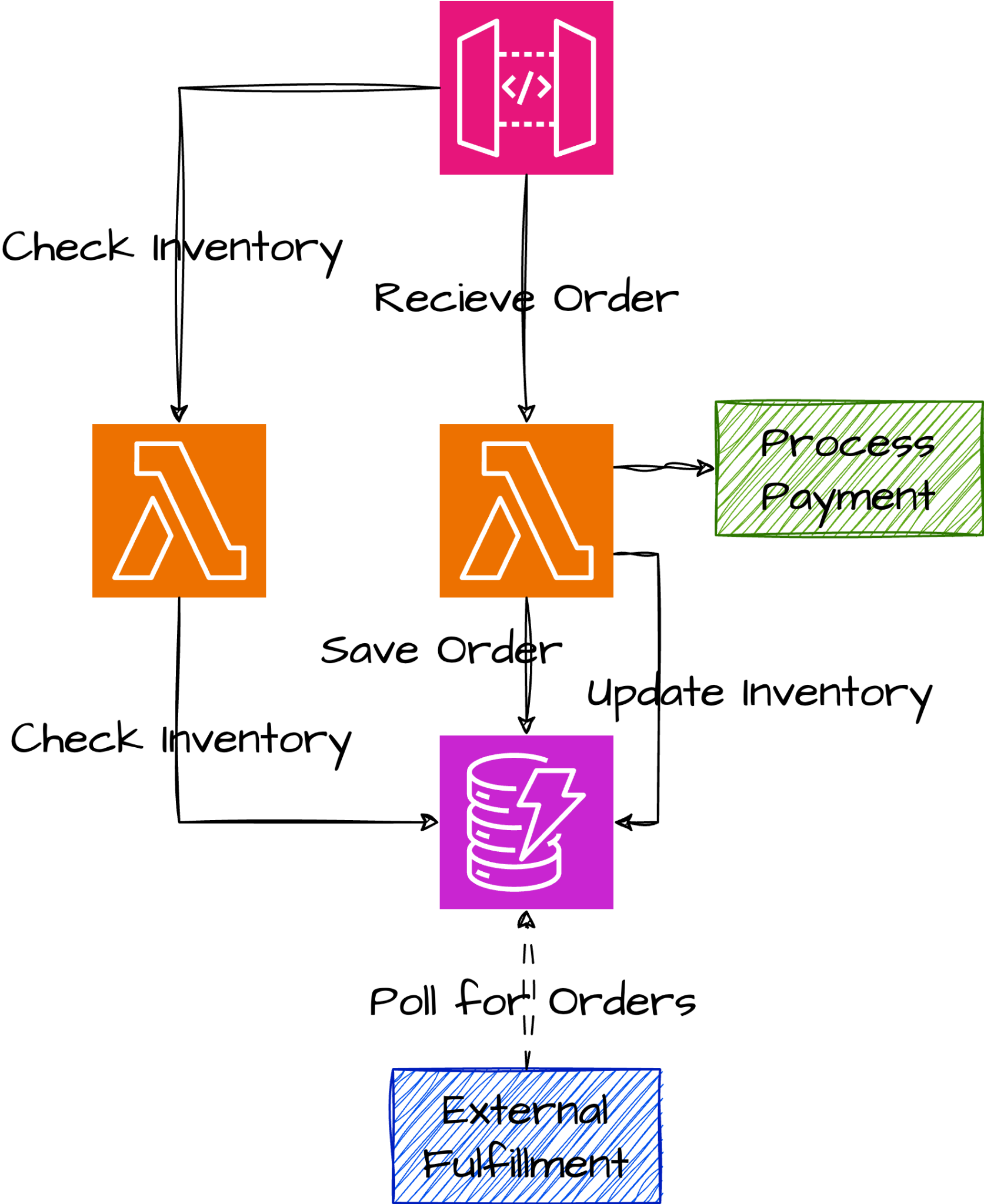
This system was built with AWS serverless technologies, but focuses mostly on API Gateway, Lambda, and DynamoDB. These services are great, but limiting ourselves to them brings in some technical challenges as well soon discover.
Our main flow is that we receive the order through our API Gateway which triggers a Lambda function to handle the order creation. The Lambda function will do three things:
- Save the order in our database.
- Reduce the current inventory level by the number of units in the order.
- Restfully notify our Payments API to handle the payment.
A Lambda function is certainly capable of performing these tasks, but as our business grows, we discover some weaknesses in our architecture:
Payment throttles
Our Payments API unfortunately seems to throttle during busy periods. Because our architecture requires the CreateOrder Lambda function to complete before the API Gateway timeout of 29 seconds, that gives us only limited time to retry the requests.
Our payment processing is already asynchronous, so there's no concern if this processing is delayed, but we don't have a good way to throttle ourselves and avoid overcoming the Payments API with requests during busy periods.
We're scraping by with a manual process for now, but we need a technical solution to handle our scaling business!
Low inventory notifications
MacGuffins are selling like crazy, so much so that we've missed some opportunities by selling out a couple of times and then seeing a lull in our business while we restock.
We want to add a low stock notification that will let us know it's time to reorder. We thought about creating an SNS Topic with an email subscription. We could check inventory and trigger the event immediately after making the inventory adjustment.
This could work, but is it the best solution? Our Lambda function now does five things instead of three, so there's more that could go wrong. But worse than that, what if some other process adjusted the inventory below the warning level? If that logic only exists in our CreateOrder Lambda function, then we'd never send the notification.
Fulfillment operations
Our fulfillment process is largely manual, driven off a dashboard that queries for pending orders. We have a plan to automate more of it, but how do we know it's time to kick off the fulfillment process? We need to have some way to wait and confirm the payment was successful and we have the desired inventory on hand. To do so, it's clear that we need some kind of event-driven system.
Design considerations
Most of us are aware of the challenges associated with refactoring. For one, there's always a trade-off between refactoring and building new features. We can argue that refactoring is necessary to support new features, but the fact is we'll be doing some work that is invisible to customers and stakeholders. In order to have a chance at success and meet expectations, we need to be clear about our design considerations and desired outcomes of the refactor.
Scalability and eventual consistency
WIMS v1 works fine in our test environment and when under a light load, but it degrades under heavy workloads. We know this is because we're trying to do too much work in a customer-facing request. To resolve this issue, we want to design WIMS v2 to simply register customer intent: "We have received your order!" Our system will process that intent in an eventually consistent manner and notify the customer via email if there's a problem with payment or if an item is on backorder.
Eventual consistency is part of the scalability story. We need to ask ourselves "What happens if we get a 10x day or a 100x day?" Building with serverless is a great start, but the v1 version of our system was already serverless and yet had scaling problems. By making our system eventually consistent, we can control the throughput of our events to protect downstream services. We know that some events (such as registering customer intent) must be immediately consistent. We want to make those as responsive and lightweight as possible and offload the heavy lifting to other services.
Idempotency, fault tolerance, and replay
No system can expect to be 100% error-free. We may push a bug. We may discover an edge case or hit a service limit. Our customers will do things we don't anticipate! The managed services we build with can have their own bugs and operational issues. To mitigate these risks, we need a system that can replay events and we need the system to be tolerant to redelivery of events as well as handle the case when events are delivered an order that's different from what we expect.
Yes, it's possible to use FIFO queues, and DynamoDB Streams guarantee ordering and will not contain duplicate events, but these guarantees can be deceiving when other parts of the system may use an at-least-once delivery model. Designing for idempotency not only allows us to mitigate the risk that events may be redelivered, it allows us to replay events should the system suffer a failure. We can have the confidence to replay all events that should've been sent during an incident, rather than having to determine exactly which events need to be replayed.
Modularization
We know from experience that not long after we ship WIMS v2, we'll find a new requirement that wasn't considered during our design. For example, we could find that we have notification requirements that can't be satisfied with an SNS email subscription. If our notification implementation lives in the CreateOrder Lambda function, it could be challenging to add a new and more complex implementation in place, but since we are embracing event-driven architecture, we can simply pipe the event somewhere else.
Observability
Many developers feel distributed systems can be harder to observe. This is definitely true for systems that rely on customer complaints, server metrics, and HTTP status codes to determine system health. If WIMS v1 replies 200 OK, we're reasonably confident in thinking everything worked well. That won't be true for WIMS 2. So how do we know the system did what we wanted it to do?
First of all we need to deconstruct that HTTP 200 OK response a bit. Does a 200 response mean we've received payment and the customer received a MacGuffin? No, of course not. We're really just using that status code as a proxy for a business outcome.
A better solution is to emit business events upon completion (be it success or failure) of critical operations. These events can alert the team to things that need to be addressed (such as low inventory) and can also be used to track things like a successful payment, delivery of an item, and the current status of an order.
Change Data Capture (CDC)
Leveraging CDC events can be one of the best ways to add events to a system. For example, we could wait for a status field to change and fire an event based on that. Instead of writing code like:
updateStatus('PENDING');
sendEvent('PENDING', order);
We simply update the status and let our CDC system handle the rest. This will be a much more reliable and consistent system. What if we had to do a bulk status update to fix a bug? If we're relying on imperative code to send that event, it could be missed in the bulk update. Using CDC will guarantee the next stage of our system is invoked.
Cost
At AWS re:Invent 2023, Amazon CTO, Dr. Werner Vogels, used his keynote to make an interesting point about using cost as a proxy for good architecture and launched a website in support of this idea. Even though our MacGuffin business is growing nicely, we still want to maintain operational costs and we know that waste will not only hit our bottom line, it'll also impact operability of this system. We'll run some cost projections to make sure we're exercising frugality in our architecture.
WIMS version 2
Given our design considerations and what we've learned about event-driven architecture, our new system diagram looks like this. We will leverage CDC events from DynamoDB Streams to enable low inventory notifications and to handle asynchronous order processing. We'll use SQS to enqueue payments, leveraging redelivery mechanisms and a dead-letter queue to handle exceptions.
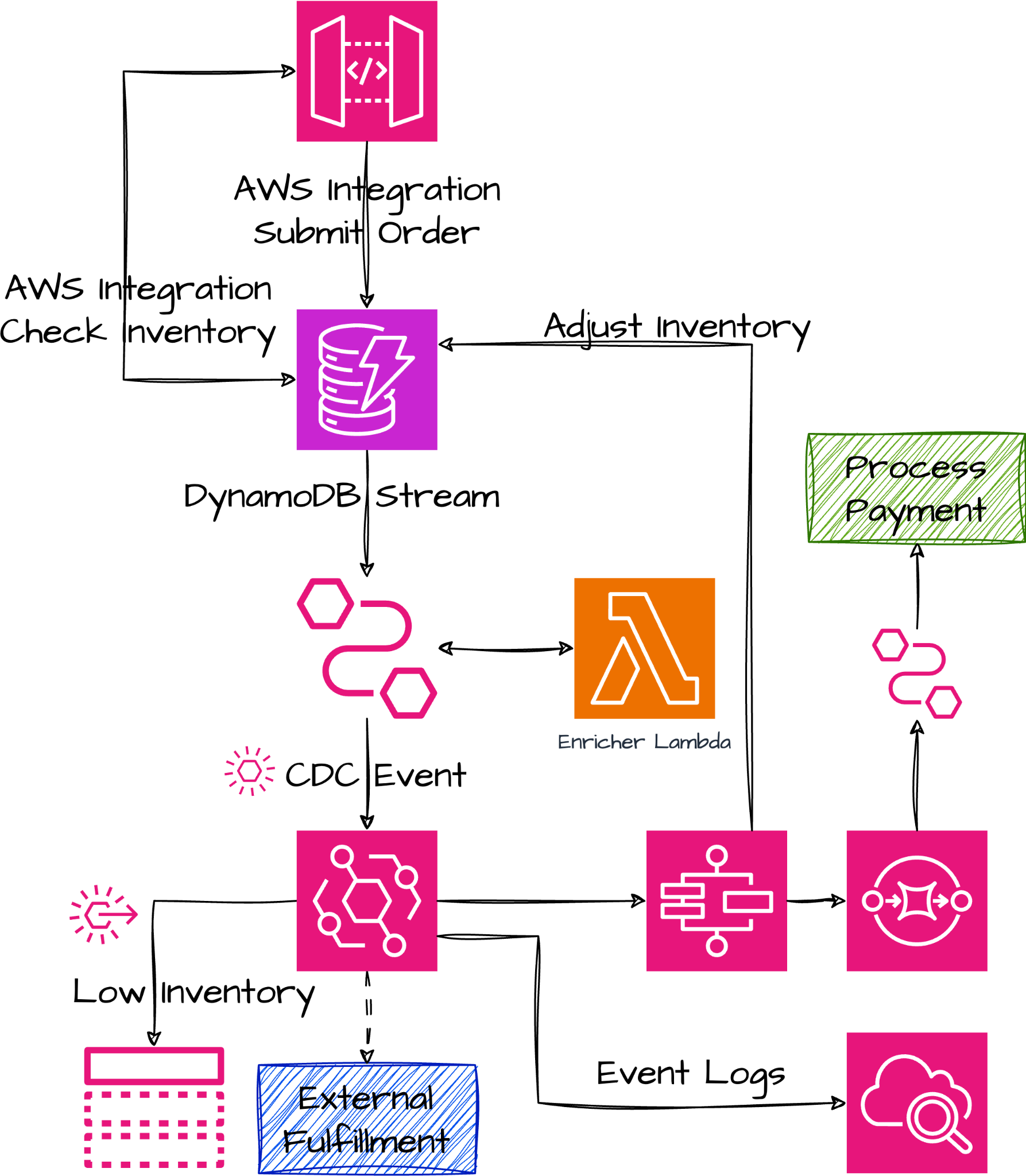
Refactoring CDK
As we start to refactor, we should think about how we're going to construct our code. It's possible to write CDK applications as a single "my-stack.ts" file, but doing so can lead to readability problems. Since a CDK application is a collection of resources, creating one very large class for all your resources can create maintainability issues. It's a best practice to give a logical organization to your resources. If we think about the domains we want to focus on here, they include:
- Orders
- Inventory
- Payments
Additionally, there are some technical considerations that need to be included in the application. These are not business domains, but they are important features that need to be included in the new architecture:
- Change Data Capture (CDC)
- Observability
Because CDK applications utilize imperative code there are a lot of different ways we can achieve this logical organization. One such tool is CDK's L3 construct. L3 constructs (also called "patterns") are often used to create, share, and publish new constructs, but they can also be simple organizational tools within an application, to allow developers to interact with part of the application as an API instead of as a collection of resources.
In this example, we'll create several L3 constructs to organize our application:
- CDC (or Change Data Capture), for capturing and routing change events
- InventoryMonitor, for checking inventory levels and sending appropriate notifications
- Observability, to add additional logging and set up an EventBridge Schema Registry
- OrdersAPI, to group our existing API for orders
- OrdersProcessor, to handle an order once it's created
- PaymentsAPI, representing our troublesome payments system
- PaymentsProcessor, wherein we attempt to solve our throughput problem
Note that while we're thinking about the critical business domains, these L3 constructs do not have a 1:1 mapping with our domains. Instead our constructs correspond to capabilities our application needs to implement those domains. domain-driven design and how that relates to event-driven architecture is a topic beyond this blogpost.
We can create L3 constructs by creating a new Typescript file with our construct's name. We'll put them in a folder under ./src/constructs, but they could go anywhere as TypeScript can import them from whatever directory structure makes sense for our team. We define the construct as a class that implements Construct.
import { TableV2 } from 'aws-cdk-lib/aws-dynamodb';
import { Construct } from 'constructs';
export interface CDCProps {
table: TableV2;
}
export class CDC extends Construct {
constructor(scope: Construct, id: string, props: CDCProps) {
super(scope, id);
// create resources
// Do something with the table prop
}
}
We can expose resources and pass them from one construct to another using standard TypeScript class syntax. To gain a reference to our Payments API RestAPI construct, we can create an accessor called getApi().
import { Stack } from 'aws-cdk-lib';
import {
RestApi,
MockIntegration,
PassthroughBehavior,
} from 'aws-cdk-lib/aws-apigateway';
import { Construct } from 'constructs';
export class PaymentsApi extends Construct {
private api: RestApi;
constructor(scope: Stack, id: string) {
super(scope, id);
// Payments is an external system so mocked here.
this.api = new RestApi(this, 'WIMSPayments', {
deployOptions: { throttlingBurstLimit: 5, throttlingRateLimit: 5 },
});
}
getApi() {
return this.api;
}
}
This can then be used to pass the api from one L3 construct to another.
const paymentsApi = new PaymentsApi(this, 'PaymentsApi');
const paymentsProcessor = new PaymentsProcessor(this, 'PaymentsProcessor', {
api: paymentsApi.getApi(),
});
You can find the original wims-stack.ts in the project's GitHub Repository on the legacy branch. It's just over 100 lines of code, so not too terrible. However by the time we're done refactoring and moving all our resources to L3 constructs, we'll cut that down by half. Our stack now creates the same DynamoDB table and then adds in our new L3 constructs.
import { CfnOutput, RemovalPolicy, Stack, StackProps } from 'aws-cdk-lib';
import {
AttributeType,
StreamViewType,
TableV2,
} from 'aws-cdk-lib/aws-dynamodb';
import { Construct } from 'constructs';
import { TABLE_PK, TABLE_SK } from '../constants';
import { CDC } from '../constructs/cdc';
import { InventoryMonitor } from '../constructs/inventory-monitor';
import { ObservabilityConstruct } from '../constructs/observability';
import { OrdersApi } from '../constructs/orders-api';
import { OrdersProcessor } from '../constructs/orders-processor';
import { PaymentsApi } from '../constructs/payments-api';
import { PaymentsProcessor } from '../constructs/payments-processor';
export class WimsStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
const table = new TableV2(this, 'WIMSTable', {
dynamoStream: StreamViewType.NEW_AND_OLD_IMAGES,
partitionKey: { name: TABLE_PK, type: AttributeType.STRING },
removalPolicy: RemovalPolicy.DESTROY,
sortKey: { name: TABLE_SK, type: AttributeType.STRING },
tableName: 'WIMS',
});
new CDC(this, 'CDC', { table });
new InventoryMonitor(this, 'InventoryMonitor');
new ObservabilityConstruct(this, 'Observability');
const paymentsApi = new PaymentsApi(this, 'PaymentsApi');
const paymentsProcessor = new PaymentsProcessor(this, 'PaymentsProcessor', {
api: paymentsApi.getApi(),
});
const ordersApi = new OrdersApi(this, 'OrdersApi', { table });
new OrdersProcessor(this, 'OrdersProcessor', {
queue: paymentsProcessor.getQueue(),
table,
});
new CfnOutput(this, 'InventoryUrl', {
value: ordersApi.getApi().deploymentStage.urlForPath('/inventory'),
});
new CfnOutput(this, 'OrdersUrl', {
value: ordersApi.getApi().deploymentStage.urlForPath('/orders'),
});
}
}
Now let's delve into the capabilities of these L3 constructs and how they'll solve our business and technical needs.
OrdersApi
This existed in V1 of our application, but had the drawback of trying to do too much. create-order.ts perhaps should've been called create-order-then-update-inventory-and-finally-call-payments-api.ts. Rather than give it a more descriptive name, let's strip it down to the core capability that we care most about - creating an order. This L3 construct will do that simple thing and defer the rest to other constructs. We could achieve this aim by removing code from our Lambda function.
import { DynamoDBClient } from '@aws-sdk/client-dynamodb';
import { DynamoDBDocumentClient, PutCommand } from '@aws-sdk/lib-dynamodb';
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import { TABLE_PK, TABLE_SK } from '../constants';
const client = DynamoDBDocumentClient.from(new DynamoDBClient({}));
const api = process.env.API_URL;
const table = process.env.TABLE_NAME;
if (!api || !table) {
throw new Error('Missing required env var!');
}
export const handler = async (
event: APIGatewayProxyEvent
): Promise<APIGatewayProxyResult> => {
if (!event.body) {
throw new Error('Missing event body!');
}
const order = JSON.parse(event.body);
if (!order.customerId || !order.quantity) {
throw new Error('Invalid order!');
}
const timestamp = new Date().getTime();
// First create the order
const createOrderCommand = new PutCommand({
Item: {
...order,
status: 'PENDING',
timestamp,
[TABLE_PK]: `CUSTOMER#${order.customerId}`,
[TABLE_SK]: `TIMESTAMP#${timestamp}`,
},
TableName: table,
});
await client.send(createOrderCommand);
return {
body: 'Order created!',
statusCode: 200,
};
};
We've deleted a bunch of code and now we have a nice, single-purpose Lambda function! But at this point, we don't really have much in the way of custom code or logic. API Gateway has the ability to integrate directly with DynamoDB. Doing this has some advantages:
- No cold starts.
- No Lambda functions to maintain, bundle, deploy, upgrade, ignore deprecation warnings of, etc.
- No Lambda charges or concurrency use.
- Forces us to keep it simple as VTL is not a great place for complex logic.
On the other hand, there are some disadvantages to consider:
- There may be a learning curve or challenge adopting this pattern.
- We're changing something that doesn't necessarily need to be changed (our stated problem is the Lambda function is trying to do too much, not that it exists).
- As our business grows, complexity may be unavoidable and we may have to return to Lambda, so we'd face more rework.
All that considered, let's try the direct integration. To do so we'll delete the create-orders Lambda function and replace our LambdaIntegration with AwsIntegration.
orders.addMethod(
'POST',
new AwsIntegration({
action: 'PutItem',
options: {
credentialsRole: role,
integrationResponses: [
{
responseTemplates: {
'application/json': JSON.stringify({
message: 'Order created!',
}),
},
statusCode: '200',
},
],
requestTemplates: {
'application/json': JSON.stringify({
Item: {
[TABLE_PK]: {
S: "CUSTOMER#$input.path('$.customerId')",
},
[TABLE_SK]: {
S: 'TIMESTAMP#$context.requestTimeEpoch',
},
customerId: {
S: "$input.path('$.customerId')",
},
quantity: {
N: "$input.path('$.quantity')",
},
status: {
S: 'PENDING',
},
timestamp: {
N: '$context.requestTimeEpoch',
},
},
TableName: table.tableName,
}),
},
},
service: 'dynamodb',
}),
{
methodResponses: [{ statusCode: '200' }],
}
);
Because our OrdersApi creates an order and immediately responds to the client, it's an example of a synchronous event. View the construct in our repo.
CDC
While it's possible to implement CDC patterns on any kind of database, DynamoDB is a stand-out choice for this pattern due to it's streaming capabilities. The DynamoDB developer guide event has a section on change data capture.
To leverage DynamoDB Streams for CDC, we first need to enable streams on our table. This is very simple to do using AWS CDK.
const table = new TableV2(this, 'WIMSTable', {
dynamoStream: StreamViewType.NEW_AND_OLD_IMAGES,
partitionKey: { name: TABLE_PK, type: AttributeType.STRING },
removalPolicy: RemovalPolicy.DESTROY,
sortKey: { name: TABLE_SK, type: AttributeType.STRING },
tableName: 'WIMS',
});
Adding a dynamoStream key with the value of NEW_AND_OLD_IMAGES will give us all the information we need to start capturing create, update, and delete events and routing them to appropriate handlers.
We can subscribe one or more Lambda functions to the stream, but it's not recommended to have more than two subscribers to a stream as it can result in throttling.
Instead of using Lambda handlers for the stream, we'll use an EventBridge Pipe. The Pipe will allow us to subscribe to the stream, enrich and transform the stream data, and then send the event back to our event bus where we can define rules to route the events to appropriate handlers.
At the time of this writing, the EventBridge Pipes L2 construct is still in RFC status. It's possible to use the proposed construct, but it is unstable and subject to change. We'll stick with the L1 CfnPipe construct for now and hope to update to L2 when that's ready.
Our Pipe is going to read from the DynamoDB stream, use a Lambda function to unmarshall the DynamoDB record to plain JSON, then send the event to our default event bus.
Because this construct is an L1, we'll need to explicitly define a role as well as grants.
const cdcPipeRole = new Role(this, 'CDCPipeRole', {
assumedBy: new ServicePrincipal('pipes.amazonaws.com'),
});
table.grantStreamRead(cdcPipeRole);
Now we can define the Pipe.
new CfnPipe(this, 'CDCStreamPipe', {
name: 'CDCStreamPipe',
roleArn: cdcPipeRole.roleArn,
source: table.tableStreamArn!,
sourceParameters: {
dynamoDbStreamParameters: { batchSize: 10, startingPosition: 'LATEST' },
},
target: bus.eventBusArn,
targetParameters: {
eventBridgeEventBusParameters: {
source: PROJECT_SOURCE,
detailType: CDC_EVENT,
},
},
});
In order to target our default event bus, we'll need to grab a reference to it and grant our role access to send events to it.
const bus = EventBus.fromEventBusName(this, 'DefaultBus', 'default');
bus.grantPutEventsTo(cdcPipeRole);
Finally, we'll define a Lambda function to enrich and transform our data and grant invoke cdcEnrichmentFn.grantInvoke(cdcPipeRole); to our role.
Our cdc-enrichment Lambda function leverages the unmarshall function from @aws-sdk/lib-dynamodb to transform the DynamoDB records into JavaScript objects that then can be consumed as JSON. We also add data and meta keys to our payload and clearly label the type of event to make it easier for downstream consumers. We could perform any sort of transformation that makes sense for our business here. The purpose of this function is to prep our data for the many consumers in our system.
import { unmarshall } from '@aws-sdk/util-dynamodb';
import type { AttributeValue } from '@aws-sdk/client-dynamodb';
import type { DynamoDBRecord } from 'aws-lambda';
import { TABLE_PK, TABLE_SK } from '../constants';
export const handler = async (records: DynamoDBRecord[]) => {
return records.map((r) => {
const oldImage = r.dynamodb?.OldImage
? unmarshall(r.dynamodb?.OldImage as Record<string, AttributeValue>)
: undefined;
const newImage = r.dynamodb?.NewImage
? unmarshall(r.dynamodb?.NewImage as Record<string, AttributeValue>)
: undefined;
const result: {
meta: Record<string, string>;
data: {
pk: string;
sk: string;
eventName: string;
eventType: string;
NewImage?: Record<string, unknown>;
OldImage?: Record<string, unknown>;
}
} = {
meta: {
fn: process.env.AWS_LAMBDA_FUNCTION_NAME!,
},
data: {
pk: oldImage?.[TABLE_PK] || newImage?.[TABLE_PK] || '',
sk: oldImage?.[TABLE_SK] || newImage?.[TABLE_SK] || '',
eventName: r.eventName || 'UNKNOWN',
eventType:
oldImage && newImage ? 'UPDATE' : oldImage ? 'REMOVE' : 'INSERT',
},
};
if (newImage) result.data.NewImage = newImage;
if (oldImage) result.data.OldImage = oldImage;
return result;
});
};
Our complete construct includes the enrichment as well as additional logging which may be helpful in understanding how our Pipe is operating.
OrdersProcessor
This L3 construct will consist of an EventBridge Rule that triggers a Step Function whenever a new order is created. The Step Function will make inventory adjustments based on the order and put enqueue messages for SQS to be sent to our payments system.
The Step Function consists of two steps that are executed in parallel. To make inventory adjustments, we could use a Lambda Function or we can use the direct integration.
const adjustInventory = new DynamoUpdateItem(this, 'AdjustInventory', {
expressionAttributeNames: { '#quantity': 'quantity' },
expressionAttributeValues: {
':quantity': DynamoAttributeValue.numberFromString(
JsonPath.format(
'{}',
JsonPath.stringAt('$.detail.data.NewImage.quantity')
)
),
},
conditionExpression: '#quantity >= :quantity',
key: {
[TABLE_PK]: DynamoAttributeValue.fromString('INVENTORY#MACGUFFIN'),
[TABLE_SK]: DynamoAttributeValue.fromString('MODEL#LX'),
},
resultPath: JsonPath.DISCARD,
table,
updateExpression: 'set #quantity = #quantity - :quantity',
});
This statement contains a conditionExpression that will ensure we don't decrement the inventory below zero. This should trigger another event that could then notify the customer that they'll need to wait for us to resupply.
Another direct integration with SQS passes those messages along to be queued for payment.
const enqueuePayment = new SqsSendMessage(this, 'EnqueuePayment', {
messageBody: TaskInput.fromJsonPathAt('$.detail.data.NewImage'),
queue,
});
We wrap all of this up in an Express Workflow because we know it'll execute very quickly and Express Workflows are more cost-efficient for short workflows. An alternate implementation of this workflow could involve sending a Task Token to the payment system and pausing until it's returned. In that case a Standard Workflow is required as we know our payment system is not fast.
const sm = new StateMachine(this, 'OrdersStateMachine', {
definitionBody: DefinitionBody.fromChainable(parallel),
logs: {
destination: new LogGroup(this, 'SMLogs', {
logGroupName: '/aws/vendedlogs/states/OrdersSMLogs',
removalPolicy: RemovalPolicy.DESTROY,
retention: RetentionDays.ONE_DAY,
}),
includeExecutionData: true,
level: LogLevel.ALL,
},
stateMachineName: 'orders-state-machine',
stateMachineType: StateMachineType.EXPRESS,
tracingEnabled: true,
});
Unlike Standard Workflows, Express Workflows require logging to be set up in order to have dashboard visibility. If we omit the logging, we may have a frustrating time observing the state machine.
Our EventBridge Rule includes some filters so that we'll only trigger the workflow on an order creation event.
new Rule(this, 'OrderStateMachineRule', {
eventBus: bus,
eventPattern: {
source: [PROJECT_SOURCE],
detailType: [CDC_EVENT],
detail: {
data: {
eventType: ['INSERT'],
pk: [{ prefix: 'CUSTOMER#' }],
},
},
},
ruleName: 'OrdersStateMachine',
targets: [new SfnStateMachine(sm)],
});
}
Check out the full source of the OrdersProcessor. This construct uses an EventBridge Rule to implement an async bus pattern as a consumer of an event that could potentially have other consumers.
PaymentsQueue
Our PaymentsQueue construct consists of an SQS Queue, a corresponding dead-letter queue, and another Pipe resource that routes our events to the Payments API. Using SQS in this way gives us the ability to store and redeliver events when we face throttles. We can configure our queue to allow as many retries as make sense for our system before finally delivering to our dead-letter queue
const dlq = new Queue(this, 'PaymentsDlq', { queueName: 'payments-dlq' });
new Queue(this, 'PaymentsQueue', {
deadLetterQueue: { maxReceiveCount: 10, queue: dlq },
queueName: 'payments-queue',
});
Our CfnPipe construct using our queue as a source and pipes those events to the Payments API using an ARN (Amazon Resource Name) comprised of the RestAPI id, the stage, the HTTP method, and the resource.
new CfnPipe(this, 'PaymentsPipe', {
name: 'PaymentsPipe',
roleArn: paymentsPipeRole.roleArn,
source: this.paymentsQueue.queueArn,
target: Arn.format(
{
service: 'execute-api',
resource: `${api.restApiId}/prod/POST/payments`,
},
Stack.of(this)
),
targetParameters: {
inputTemplate: `{
"body": <$.body>
}`,
},
});
In this simple example, we're just pushing the same event along as the POST body, but there could be good reason to use another enrichment function here.
See the full source of this construct. It implements an async queue pattern where events are enqueued until they can be successfully delivered.
InventoryMonitor
This construct really demonstrates the power of EDA. We will define an SNS Topic with an email subscription and then a rule to invoke it.
const inventoryStockTopic = new Topic(this, 'InventoryStockTopic');
inventoryStockTopic.addSubscription(new EmailSubscription('theteam@ourcompany.com'));
These two lines of code are all we need to create the topic and subscribe our team to it. Then we define the EventBridge Rule.
new Rule(this, 'InventoryStockRule', {
eventBus: bus,
eventPattern: {
source: [PROJECT_SOURCE],
detailType: [CDC_EVENT],
detail: {
data: {
eventType: ['UPDATE'],
pk: [{ prefix: 'INVENTORY#' }],
NewImage: {
quantity: [{ numeric: ['<=', 100] }],
},
},
},
},
targets: [new SnsTopic(inventoryStockTopic)],
});
EventBridge Rules allow numeric matching on filters so we can easily implement our business logic here so the rule is only triggered when our inventory level falls to 100 units or fewer. Note that this construct does not need to be concerned with dispatching the event. That is managed by the CDC construct.
The source is available here. This construct is triggered by an async bus event which is converted to a broadcast event using SNS.
Benchmarking v1 vs. v2
v1
We can use a simple script to do some benchmarking. This script will attempt to fire off 10 concurrent events, wait for them to complete and then loop until we've created 1000 orders. A tool running on NodeJS isn't going to give us true concurrency (requests are initiated sequentially), but it's good enough for our purposes.
Running the script against the v1 system a few times gives fairly consistent results.
Time for 1000 orders.: 2:04.980 (m:ss.mmm)
{ '200': 613, '429': 387 }
It took over 2 minutes to get through 1000 orders. Since we were running ten at a time, that means it took about 1.25 seconds for each iteration. That's not bad, but we have a big problem in that when our Payments API throttles, that error is returned back to the user. In this case, the order and inventory adjustment were both captured successfully, but the payment failed. An error rate of 38.7% is way too high! We might want to improve latency, but the error rate is a critical problem. Can this be solved with the new architecture?
v2
Running the same script agianst the v2 system, we see immediate improvement!
Time for 1000 orders.: 39.588s
{ '200': 1000 }
Our iterations are taking less than 1/3 the time and we have no errors! But that's not really fair, since the entire point of this architecture is that we're doing less up front when we create the order. Does everything else happen as it should? How eventual is the consistency?
To check on our inventory adjustments, we can query inventory levels before and after the script runs and see if they all happened. The script makes a variable number of units per orders so we'll keep a running total and see if they all reconcile.
Starting Inventory: 1000000
Inventory at next tick: 994536
Inventory reduced by: 5464 of sales total 5536.
Time for 1000 orders.: 39.396s
{ '200': 1000 }
Querying immediately after finishing our orders, we can see that some of the adjustments are still in flight. How long does it take for them to settle?
Adding an additional wait of 500ms produces the desired result.
Starting Inventory: 994464
Inventory at next tick: 988938
Inventory reduced by: 5526 of sales total 5628.
Time for 1000 orders.: 31.332s
{ '200': 1000 }
Inventory after 500ms: 988836
Inventory reduced by: 5628 of sales total 5628.
Waited 500 ms.
All our adjustments were completed in less time than it took the original system to do synchronously!
Note that DynamoDB reads can be eventually consistent themselves, so we won't actually know if that's the cause of the slight latency in updates or if our events are still in flight. In the end it doesn't matter if we've embraced the idea of eventual consistency.
One more thing we're ignoring is whether or not the payments all went through successfully. Since our example Payments API is just a RestAPI with a rate limit and a mock response, it won't be possible for it to tell us if it got all the payments like it would be in a real system. We can look to our queuing architecture to determine whether or not delivery was successful.
We've configured SQS to attempt 10 deliveries after which it'll fail over to our dead-letter queue. When running the benchmark, we can use the "Poll for messages" functionality on the AWS console and see the messages in flight waiting for redelivery.
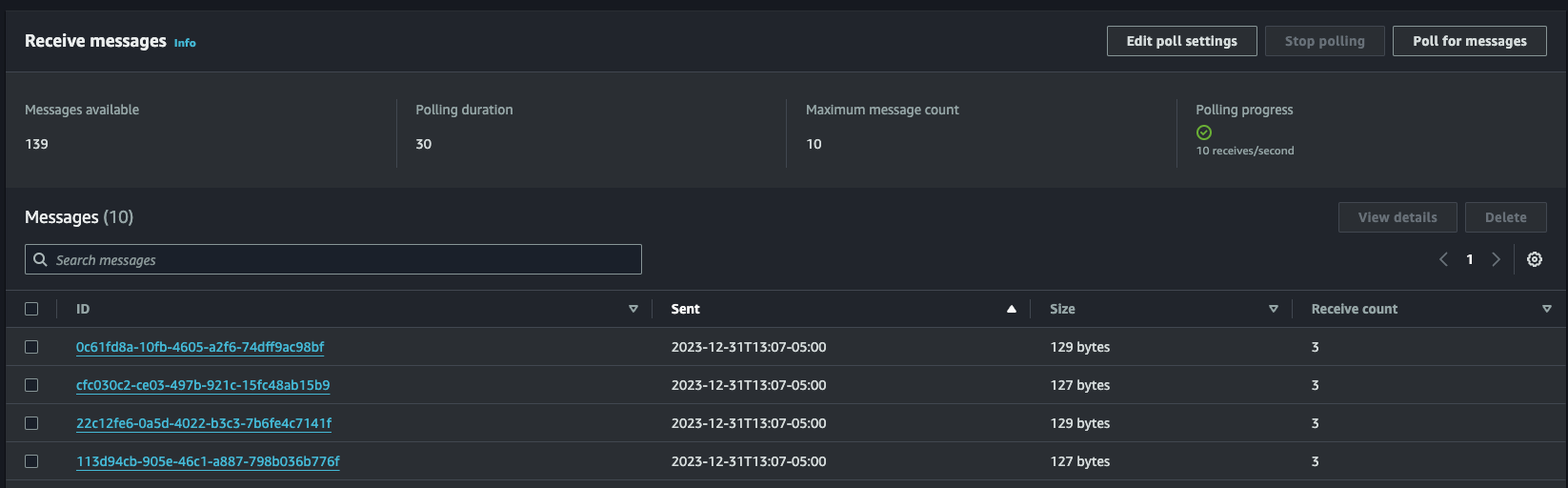 AWS SQS console showing messages queued for redelivery
AWS SQS console showing messages queued for redelivery
As long as "Receive count" is below 10, we can expect these messages to keep trying. We'll want to switch over to our dead-letter queue to check for messages there at the end. If there are none, then everything eventually was processed!
 AWS SQS console showing the dead-letter queue has no messages
AWS SQS console showing the dead-letter queue has no messages
Our Payments API has a rate limit of 5 requests per second so it should take at least 200 seconds to handle 1000 requests.
Results are in!
The v1 system processed 1000 orders in about 125 seconds with a miserable 61.3% success rate. The v2 system responds in 30-40 seconds with 500ms additional latency on completing inventory adjustments. Payments lag behind for a couple more minutes, but that's just a limitation of the payments system. We've solved the error rate problem and now 100% of our requests succeed!
Cost
Let's run the numbers on what this system will actually cost to operate. We know based on experience that there's no cost for running 1000 orders. Everything is well within the free tier at that level. What about a million orders?
Here's a stab at estimating that with the AWS Pricing Calculator.
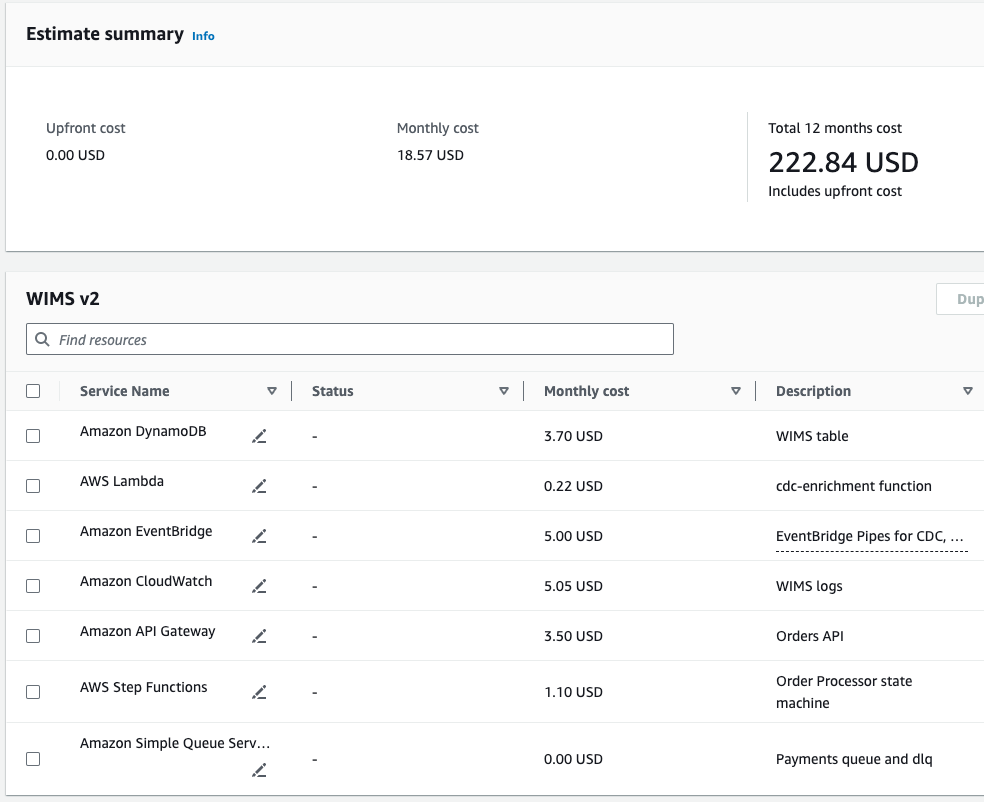 Cost estimate for 12 months of the WIMS 2.0 system showing a total of $222.84
Cost estimate for 12 months of the WIMS 2.0 system showing a total of $222.84
This is assuming 1 million units moved every month. Hopefully our margins are good enough to afford $222.84 on 12 million sold. Of course this is an incomplete system so it's easy to imagine the full system costing 10x or 100x of this, but even at those levels this remains fairly affordable (again assuming we've got reasonable margins per MacGuffin). The best part is that our costs will ebb and flow with sales numbers, so any time our AWS bill is higher than normal, that should be accompanied with some great revenues and likewise if sales are down, we should be able to console ourselves with lower-than-usual bills.
Conclusion
We started with an API-driven system that had problems scaling up and adding new features and broke down some of the parts to create an event-driven, eventually consistent system that is still quite responsive, observable, extensible, and cheap to operate.
We explored different event patterns including synchronous, async queue, async bus and broadcast events. We discussed design principles like eventual consistency and idempotency as well as techniques that can lead to stated outcomes.
I hope you enjoyed this journey and are inspired to build better, more scalable, more observable, and more cost-efficient systems as a result. I'd love to hear from you and happy building!