By Sebastian Sigl
Natural language processing (NLP) is an old science that started in the 1950s. The Georgetown IBM experiment in 1954 was a big step towards a fully automated text translation. More than 60 Russian sentences were translated into English using simple reordering and replacing rules.
The statistical revolution in NLP started in late the 1980s. Instead of hand-crafting a set of rules, a large corpus of text was analyzed to create rules using statistical approaches. Different metrics were calculated for given input data, and predictions were made using decision trees or regression-based calculations.
Today, complex metrics are replaced by more holistic approaches that create better results and that are easier to maintain.
This post is about word embeddings, which is the first part of my machine learning for coders series (with more to follow!).
What are word embeddings?
Traditionally, in natural language processing (NLP), words were replaced with unique IDs to do calculations. Let’s take the following example:

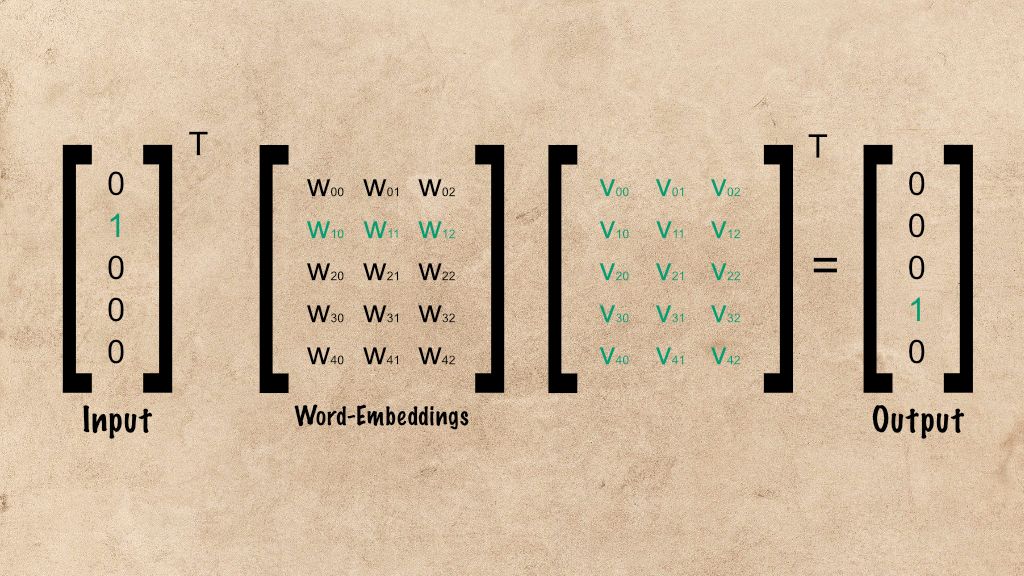
This approach has the disadvantage that you will need to create a huge list of words and give each element a unique ID. Instead of using unique numbers for your calculations, you can also use vectors to that represent their meaning, so-called word embeddings:
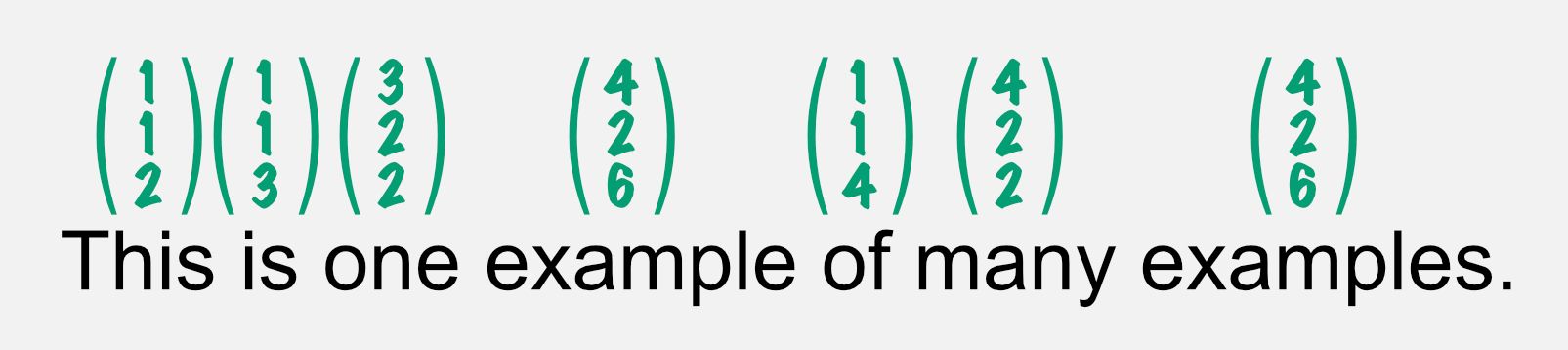
In this example, each word is represented by a vector. The length of a vector can be different. The bigger the vector is, the more context information it can store. Additionally, the calculation costs go up as vector size increases.
The element count of a vector is also called the number of vector dimensions. In the example above, the word example is expressed with (4 2 6), whereby 4 is the value of the first dimension, 2 of the 2nd, and 6 of the 3rd dimension.
In more complex examples, there might be more than 100 dimensions that can encode a lot of information. Things like:
- gender,
- race,
- age,
- type of word
will be stored.
A word such as one is a word that is a quantity like many. Therefore, both vectors are closer compared to words that are more different in their usage.
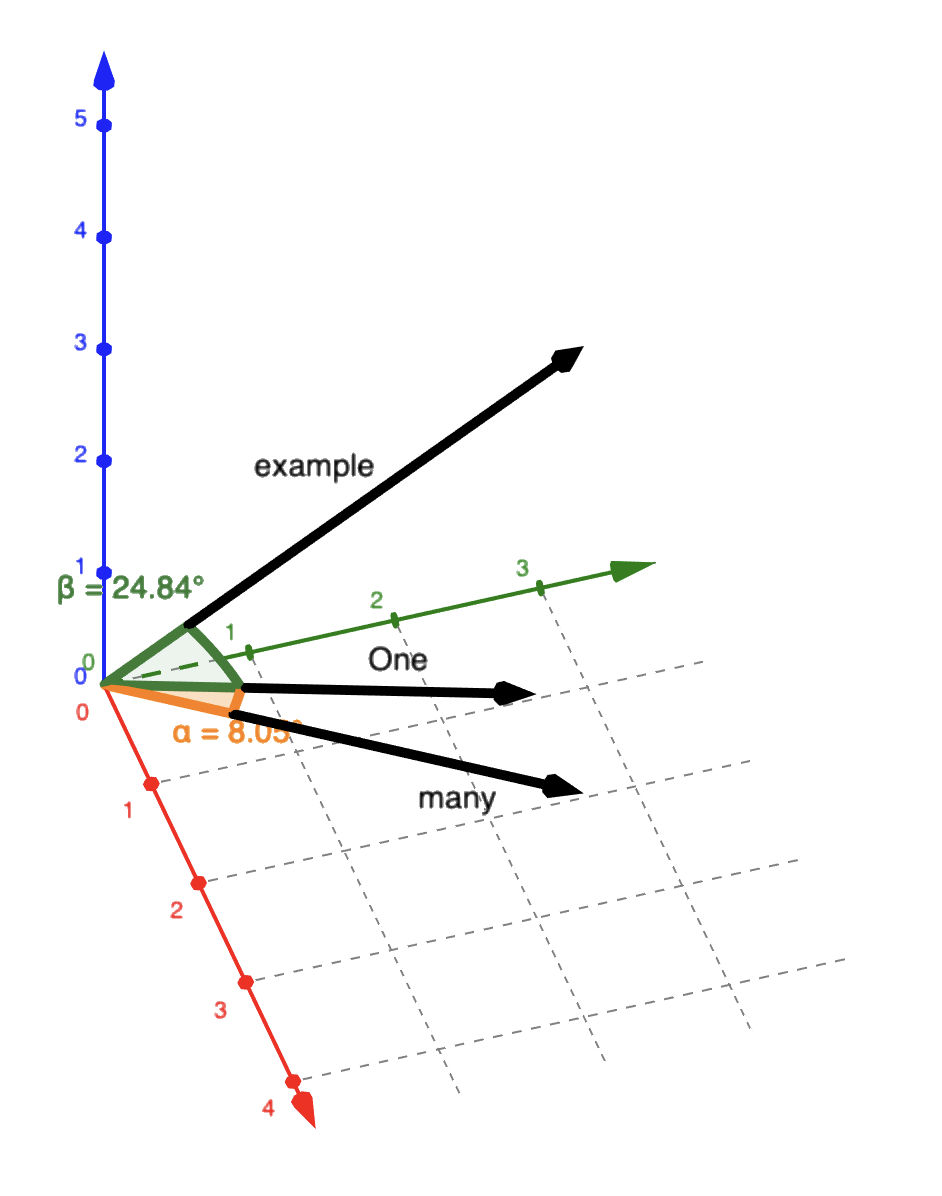
Simplified, if vectors are similar, then the words have similarities in their usage. For other NLP tasks, this has a lot of advantages because calculations can be made based upon a single vector with only a few hundreds of parameters in comparison to a huge dictionary with hundreds of thousands of IDs.
Additionally, if there are unknown words that were never seen before, then this is no problem. You just need a good word embedding of the new word, and calculations are similar. The same applies to other languages. This is basically the magic of word embeddings that enables things like fast learning, multi-language processing, and much more.
Creation of word embeddings
It’s very popular to extend the concept of word embeddings to other domains. For example, a movie rental platform can create movie embeddings and do calculations upon vectors instead of movie IDs.
But how do you create such embeddings?
There are various techniques out there, but all of them follow the key aspect that the meaning of a word is defined due to its usage.
Let’s say we have a set of sentences:
text_for_training = [
'he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'she is a daughter',
'he is a son'
]
The sentences contain 10 unique words, and we want to create a word embedding for each word.
{
0: 'he',
1: 'a',
2: 'is',
3: 'daughter',
4: 'man',
5: 'woman',
6: 'king',
7: 'she',
8: 'son',
9: 'queen'
}
There are various approaches for how to create embeddings out of them. Let’s pick one of the most used approaches called word2vec. The concept behind this technique uses a very simple neural network to create vectors that represent meanings of words.
Let’s start with the target word “king”. It is used within the context of the masculine pronoun “he”. Context in this example means it just is part of the same sentence. The same applies to “queen” and “she”. It also makes sense to do the same approach for more generic words. The word “he“ can be the target word and “is” is the context word.

If we do this for every combination, we can actually get simple word embeddings. More holistic approaches add more complexity and calculations, but they are all based on this approach.
To use a word as an input for a neural network we need a vector. We can decode a word's unique id in a vector by putting a 1 at the position of the word of our dictionary and keep every other index at 0. This is called a one-hot encoded vector:
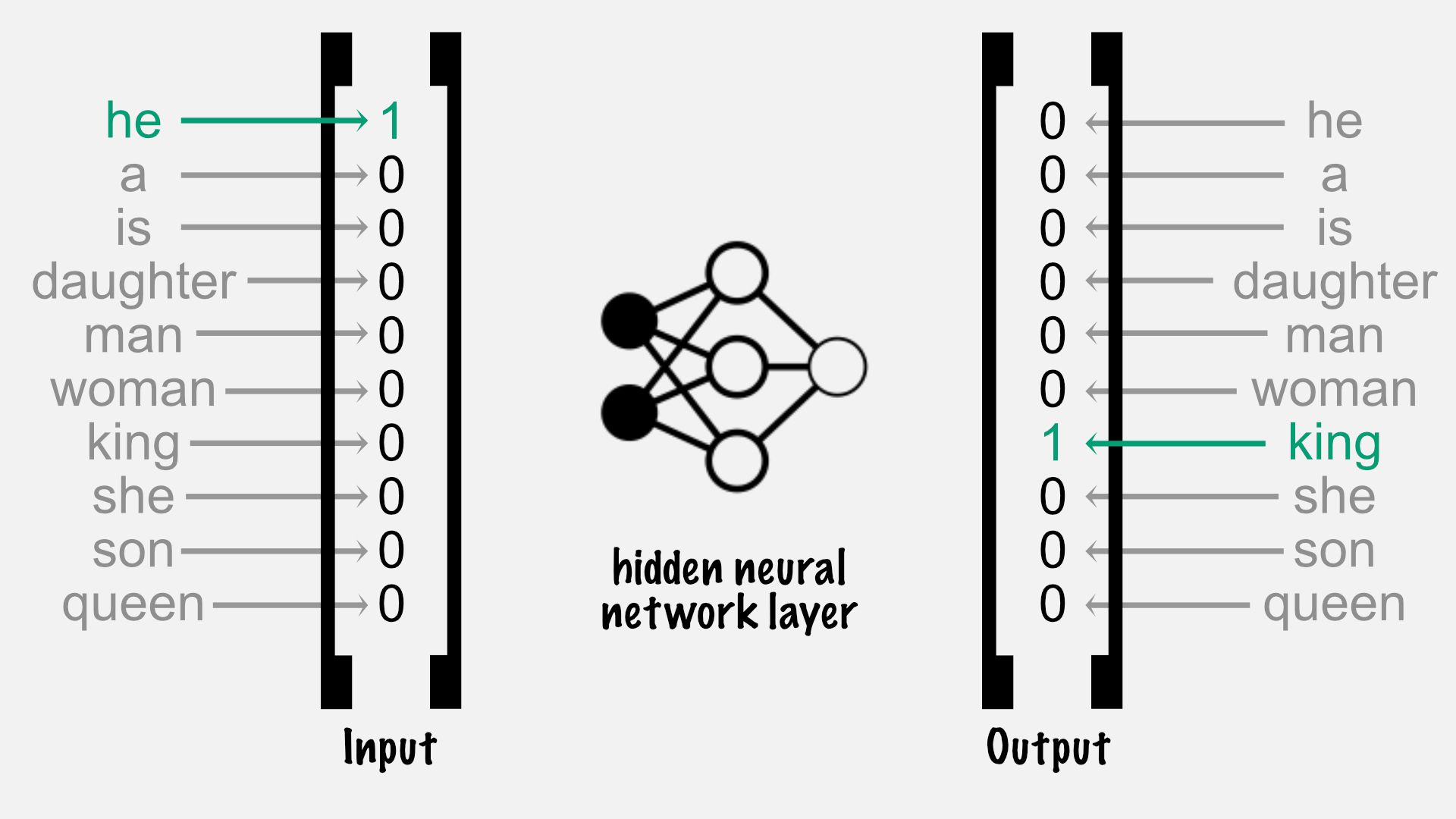
Between the input and the output is a single hidden layer. This layer contains as many elements as the word embedding should have. The more elements word embeddings have, the more information they can store.
You might think, then just make it very big. But we have to consider that we need to store an embedding for each existing word that quickly adds up to a decent amount of data to be stored. Additionally, bigger embeddings mean a lot more calculations for neural networks that use embeddings.
In our example, we will just use 5 as an embedding vector size.
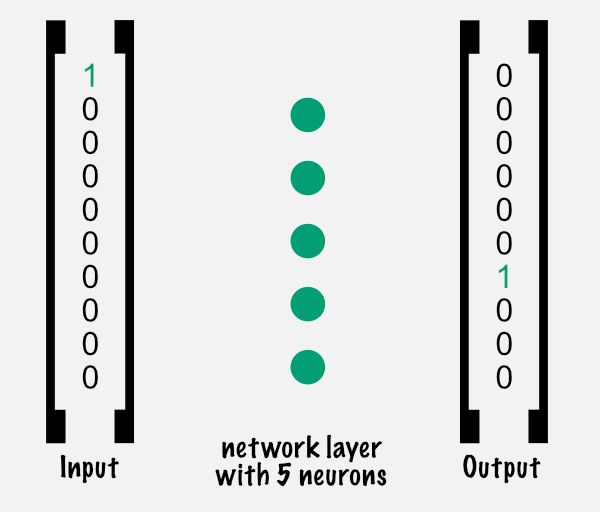
The magic of neural networks lies in what's in between the layers, called weights. They store information between layers, where each node of the previous layer is connected with each node of the next layer.
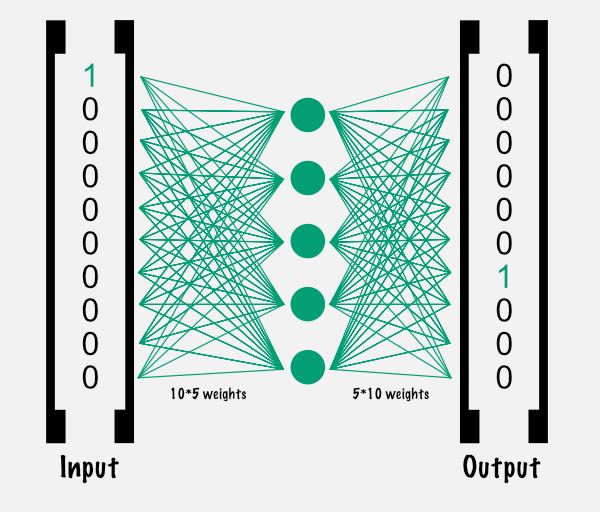
Each connection between the layers is a so-called parameter. These parameters contain the important information of neural networks. 100 parameters - 50 between input and hidden layer, and 50 between hidden and output layer - are initialized with random values and adjusted by training the model.

In this example, all of them are initialized with 0.1 to keep it simple. Let’s think through an example training round, also called an epoch:
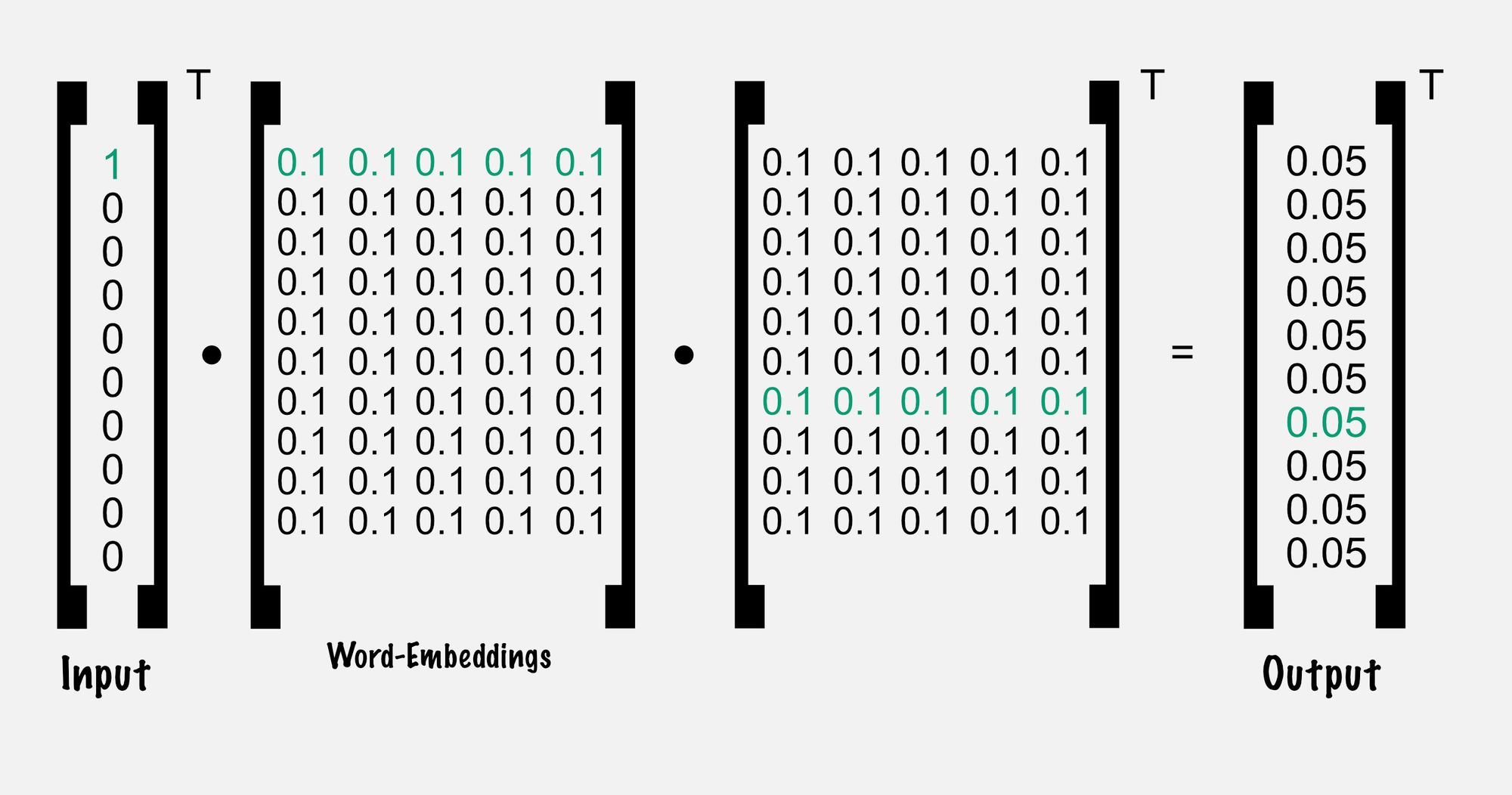
At the end of the calculation of the neural network, we don’t get our expected output that tells us for the given context “he” that the target is “king”.
This difference between the result and the expected result is called the error of a network. By finding better parameter values, we can adjust the neural network to predict for future context inputs that deliver the expected target output.
The contents of our layer connections will change after we try to find better parameters that get us closer to our expected output vector. The error is minimized as soon as the network predicts correctly for different target and context words. The weights between the input and hidden layer will contain all our word embeddings.
You can find the complete example with executable code here. You can create a copy and play with it if you press “Open in playground.”
If you are not familiar with notebooks, it’s pretty simple: it can be read from top to bottom, and you can click and edit the Python code directly.
By pressing “SHIFT+Enter,” you can execute code snippets. Just make sure to start at the top by clicking in the first snipped and pressing SHIFT+Enter, wait a bit and press again SHIFT+Enter, and so on and so on.
Conclusion
In a nutshell, word embeddings are used to create neural networks in a more flexible way. They can be built using neural networks that have a certain task, such as prediction of a target word for a given context word. The weights between the layers are parameters the are adjusted over time. Et voilà, there are your word embeddings.
I hope you enjoyed the article. If you like it and feel the need for a round of applause, follow me on Twitter. I work at eBay Kleinanzeigen, one of the biggest classified companies globally. By the way, we are hiring!
Happy AI exploring :)
References
- Wikipedia natural language processing
https://en.wikipedia.org/wiki/Natural_language_processing - Great paper about text classification created by co-founders of fastai
https://arxiv.org/abs/1801.06146 - Googles state of the art approach for NLP tasks
https://arxiv.org/abs/1810.04805