

API stands for Application Programming Interface. An API communicates with two applications using requests and responses. It is exposed to external users.
How Does an API Work?
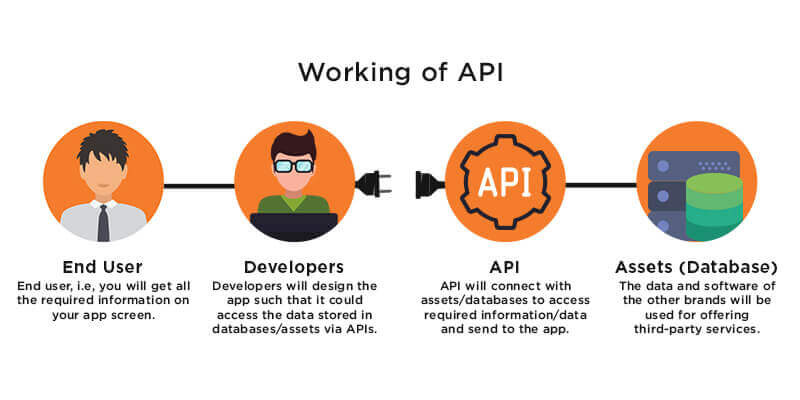 How an API works
How an API works
Imagine you are in a store and want to buy a soda. But you can't just walk in and take one because you are an outsider – an external user – so you need a link (talking to someone and paying for your soda) to get what you want.
You can't link to the shelves – the database – because they can't move or talk. So this is where the seller – the API – comes in. The seller serves as an intermediary between you and the item – the data (soda) – you want.
Now, you have a link to communicate to the items on the shelves, so you request the soda. Then the seller searches for the soda brand and the flavor you want and gives it to you. You pay, take it, and leave.
What just happened?
The seller (acting as the API) queried the shelves (the database) for the requested data.
As you may know, data sets come in different forms. The API queried the database for a table and then searched the table for detailed data. Finally, the API sent you the data you needed.
Let's say you request a Fanta soda.
Your request:

Your Response:

The response is always in JSON (JavaScript Object Notation) format. This is how an API works.
How to Design an API
When designing an API, you should consider some best practices which can help you optimize your APIs and their response times.
Name the API Properly
Suppose you are creating an API that sends you the data of a particular user. It wouldn't be wise to name the API simply GetUsers because it means you want to get all users on the database, and the external user that will call this API will be expecting a response from what you want to give.
Examples of a Good Name for an API
- Use a clear, concise name:
If you want to query a database of apples, it wouldn't make sense for you to name the API "api/fruits/."
Although Apple is a fruit, it isn't what the end-user wants. The end-user wants a particular fruit, so name it "api/apples/".
- Use words that explain the query:
Use words like nouns that represent the resource's contents in the API, for example "api/stationery/pens". This explains the API queries for all pens in the stationery database.
This would be instead of, for example, "api/stationery/write".
- Avoid special characters:
This may confuse the end-user if they see an API like "api/fruits%20?/apple". They will not understand what this API does or how it queries, or what information it will get.
Define Parameters When Necessary
Try as much as possible to avoid using additional parameters unless you need them. Some examples of required parameters when creating a RestFul API are:
- Request headers and cookies: This parameter uses a small piece of data that a server sends to a user's web browser.
- URL query string: These parameter elements are inserted in your URLs to help you filter and organize content or track information on your website.
- URL paths: This is a required parameter that gives the end-user or whoever calls the API a way to get the right information, such as: "/users/", "/users//", "package/".
- Body query string/multipart: This parameter sets the HTTP method for the question or API, such as POST – for sending data, or PUT – for updating the data in an API.
So when do you need parameters? Let's say external users are making multiple queries on an API service, and the API will query other services to get users' desired data.
This will slow the API service, but additional parameters are helpful in this case.
Define Response Objects
In layperson's terms, Response Objects are properties of a response when an API is triggered or called. Some response objects are:
- Title: This is the display title of the response, such as User if the object is returning some user information. This is a required response object.
- Subject: This is the subject of the response, such as the user and any other user-related information the API is meant to relate.
- Sender_id: This is the ID of the sender or user created. This is an option response object, meaning you can choose not to add it to the response object if it isn't needed.
- Categories: This is the category of the response object. If the API returns a user's information, the category will be Users.
Many developers create a response object that contains everything from the API service – even unnecessary information – in the hope of not changing the response object when the user asks for more details (as this takes more network requirements).
Unfortunately, this is a terrible API design practice. When creating a response object, it is wise only to return what the external user will need because building a large microservice will affect the performance and more.
Define Error Objects
When you're returning an error message when an external user queries the database, the message should be clear and concise – not just a generic error message like "Error Found" or "Error occurred."
This should be the title of the response, and the data or subject section should explain what sort of error occurred.
This is my personal take when creating an API error message. Do not return an unnecessary error message. Let's say some user data has a maximum character length of 5, and an external user queries the API for user data with a character length of 8.
Instead of doing this:

Do this:

This explains what the end user did wrong and the formatting shows the end user that this error is a client error.
Use Correct HTTPS Request Methods
When defining an HTTP method%20operations%2C%20respectively.) for an API service, you must use the correct method to let users query the right way. Some HTTPS methods are:
- POST: Use this method if the end-user is to send data to the API.
- GET: Use this method if the end-user is to retrieve data after the API queries the database.
- PUT: Use this method if the end-user updates existing data in the database.
- PATCH: Use this method if the end-user needs to correct or replace existing data in the database.
- DELETE: Use this method if the end-user deletes any information or data from the database.
Imagine an external user wants to query the user table by sending an ID, and the API method you designed uses the POST method. This will limit the users' queries as the end-user isn't adding or creating data, and the user can not query the way they should be able to.
Instead, using the GET method with an ID as a parameter would be best, and it should go this way:
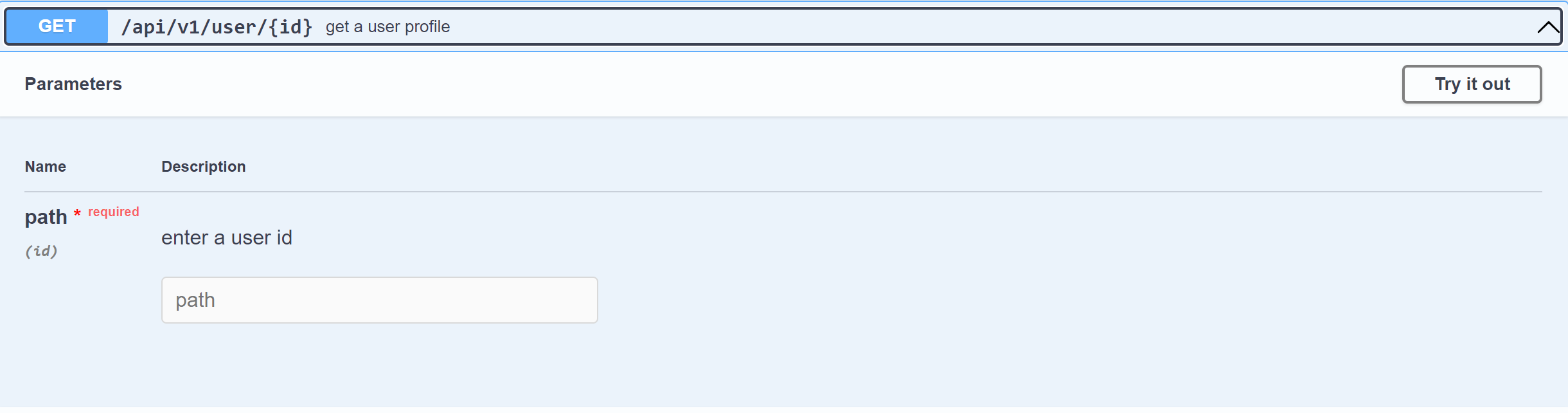
This will give users the option to query using an ID and get specific data.
I suggest knowing all the HTTP request methods before defining a method and returning the correct ID when requested.
Make sure the routing is crystal clear so users can quickly call the API service I showed earlier.
Don't Create Side Effects on the API
A side effect is, for example, when an external user queries an API for the user's first name but it returns the ID and full name.
When creating an API, try not to define everything in one function as much as possible. If the API sets many flags or does many tasks simultaneously, it should be split into multiple APIs. That's where atomicity comes to play.
Atomicity is when multiple operations are grouped into a single logical entity. Atomicity is important when creating an API. When using atomicity, poorly naming a function is just a terrible idea.
When is atomicity needed?
Imagine we want a user to be created as an admin under the admins' group table. Still, we haven't yet created the admin group table, so our logic is to create a user as an admin, create the admin group table, then add the admin user to the admin group table.
But what if it fails? Let's say the user isn't created as an admin, but the admin table is created or vice versa. That is where atomicity comes in play.
When using atomicity to call an action, try to call the right action instead of a generic action. Otherwise it makes a massive mess of the API, and there will be confusion when using the API.
Implement Pagination
When creating a huge microservice and the response body or object becomes too large, pagination makes it easier for the API to return a small amount of information.
Pagination is a method of separating digital content into different pages on a website or a response object.
Imagine a database with seventy users. The API calls getUsers instead of sending the response of all the users at once and making it slow.
You can break the response down, like return the first thirty users, the subsequent thirty users, and the following ten users. The paginated response is faster, though.
But this violates the property of stateless APIs, which is when an external user handles the storing of session-related information on their end.
Use Fragmentation
When an API communicates internally, the response is usually short. But when it is a large response, it is an exception, and when it is an exception, there is a problem.
This occurs when the response surpasses its limit ( 10kb or 15kb per response). The solution here is to break the response down and give it to another service bit by bit.
It is like breaking the TCP (Transmission Control Protocol) number into fragments and giving it out so the service will not be overloaded.
It will know that more details are yet to come, and it will also have an end packet, like a break command, that says the protocol is ending when the fragments are about to end.
Conclusion
Here are some major takeaways from this article:
- Avoid strange character and use words that represent the contents of the API response.
- Pagination and fragmentation are essential when the response object is vast.
- You should cache your requests if you have a lot of load on your database.
- If you have a lot of load, reduce your response time instead of passing the full information to the user. Just pass in the essential or critical data. That is called service degradation. It involves giving the essentials and still responding without crashing the API service.
- When designing an API and you want a perfect data consistency, cache your responses.