By Michael Hunger
An interesting use of our community-graph project and gender-API
A while back, I came across Peggy’s Twitter request:
Which got a really cool response from Bonnie that warmed my heart:
And triggered an idea …
Developer Community Activity Data
As you might know, we’re having a lot of fun showing the impressive engagement of developers in their communities (for example GraphQL, Neo4j, …) in a single place by importing them into a “Community Graph.” Usually, it is really hard to follow the flurry of activity on Twitter, Slack, StackOverflow, GitHub, and so on to keep on top of whats happening. Especially if your community is growing quickly.
So we scratched an itch and are continuously importing (via AWS Lambda) the activity for the Neo4j community into a single graph, which can then be queried and visualized — and which is accessible here.
We did the same for the GraphQL community, as their data is also accessible via GraphiQL and documented here.
 GraphQL Community Graph
GraphQL Community Graph
So as we had all the activities of GraphQL from the last few months in our graph database, I thought it would be cool to use it to answer Peggy’s request.
You can access the read-only data here: http://107.170.69.23:7474/browser/ using “graphql” as username and password.
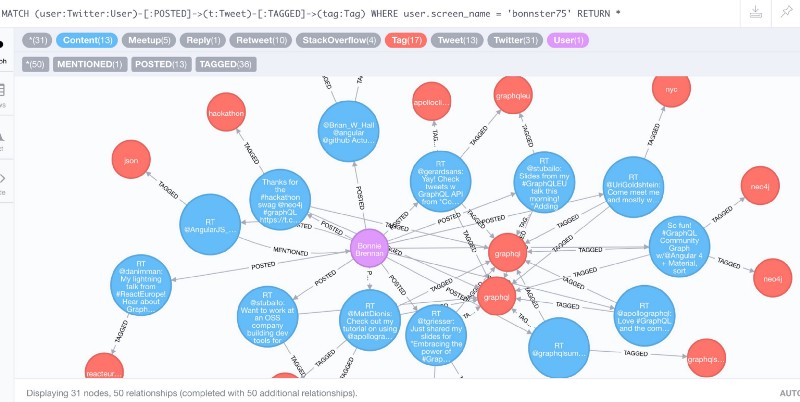
Let’s see if we can find one of the women (Bonnie Brennan) active in Peggy’s Twitter thread, who’s tweeting about GraphQL, and show her tweets and their tags.
_We’re using Neo4j’s query language Cypher here, matching the ASCII-art pattern of “a user posting tweets tagged with these tags” and then binding the user’s screenname to ‘bonnster75’ and returning everything we found.
MATCH (user:Twitter:User)-[:POSTED]->(t:Tweet)-[:TAGGED]->(tag:Tag)WHERE user.screen_name = 'bonnster75'RETURN *
Determining Gender
One simple way to predict gender is to look at the first name. I know that it is far from reliable, but we’re looking only for suggestions that we’ll check manually later. Then the power of the network can reveal further candidates.

I googled for “gender api” and found this site, which looked really nice and came with 500 free monthly requests and a simple HTTP API. Perfect for my late-night (3am) goal.
I tested a few of the names with that came back to Peggy’s request:
Peggy, Bonnie, Belén, Robin, Danielle, and Morgan.
Unfortunately, only a few got recommended to her, so I hoped that I could do better.
I used the interactive first name check at the gender-API homepage, which resulted in these results. I had to change the country to “US” as my default (“DE”) didn’t have the correct mapping for Robin and Morgan.
Peggy{"name":"peggy","country":"US","gender":"female","samples":3015,"accuracy":99,"duration":"51ms"}Bonnie{"name":"bonnie","country":"US","gender":"female","samples":3984,"accuracy":98,"duration":"25ms"}Morgan{"name":"morgan","country":"US","gender":"female","samples":5956,"accuracy":76,"duration":"33ms"}Belén{"name":"belén","country":"US","gender":"female","samples":35,"accuracy":97,"duration":"64ms"}Danielle {"name":"danielle","country":"US","gender":"female","samples":12284,"accuracy":99,"duration":"47ms"}Robin{"name":"robin","country":"US","gender":"female","samples":8088,"accuracy":83,"duration":"31ms"}
Based on this data, I think it makes sense to only look at results with an accuracy of more than 75 and at least 10 samples.
You can use the HTTP API like this:
https://gender-api.com/get?key=<key>&country=US&name=peggy
Gender Detection for Community Graph Twitter Users
Let’s try the same for our community-graph:
- We match twitter users by a list of screen-names, and
- split their name by space and take the first word as firstname.
- Which we then send to the “gender-api” API (by calling a user-defined procedure) and
- get the result back as a map-value.
- We only want to return a few attributes from our user node.
MATCH (user:Twitter:User) WHERE user.screen_name IN ['bonnster75','peggyrayzis','okbel','morgancodes', 'robin_heinze','danimman']
WITH user, head(split(user.name," ")) as firstname
CALL apoc.load.json("https://gender-api.com/get?key=<key>&country=US&name="+firstname) YIELD value
RETURN user { .screen_name, .name, .followers, .statuses} as user_data, firstname, value;
This worked well. Although Morgan got recommended to Peggy, she hadn’t tweeted yet and would probably not be in our “top active” list.
user: {"name":"Bonnie Brennan","screen_name":"bonnster75", "followers":"467","statuses":"2831"}value: {"name":"bonnie","accuracy":"98","samples":"3984", "country":"US","gender":"female"}user: {"name":"Belén Curcio","screen_name":"okbel", "followers":"3821","statuses":"35721"}value: {"name":"belén","accuracy":"97","samples":"35", "country":"US","gender":"female"}user: {"name":"Morgan Laco","screen_name":"morgancodes", "followers":null,"statuses":null}value: {"name":"morgan","accuracy":"76","samples":"5956", "country":"US","gender":"female"}
Now we want to find the “most active” women who tweet about GraphQL. A “score” could contain the number of tweets, and how often those tweets have been favorited, retweeted, or replied to. This is what we do here, we find users who have posted tweets, compute that score per user, and return the top 500 sorted by score.
MATCH (u:Twitter:User)-[:POSTED]->(t:Tweet)WITH u, count(*) as tweets, sum(t.favorites+size((t)<-[:RETWEETED|REPLIED_TO]-())) as scoreWHERE tweets > 5 AND tweets * score > 100RETURN u.name, u.screen_name, tweets, scoreORDER BY tweets * score DESC LIMIT 500
Looking at the results, it makes sense:
╒══════════════════════╤═════════════════╤════════╤═══════╕│"u.name" │"u.screen_name" │"tweets"│"score"│╞══════════════════════╪═════════════════╪════════╪═══════╡│"Sashko Stubailo" │"stubailo" │"538" │"1567" │├──────────────────────┼─────────────────┼────────┼───────┤│"Apollo" │"apollographql" │"150" │"1389" │├──────────────────────┼─────────────────┼────────┼───────┤│"ReactDOM" │"ReactDOM" │"221" │"596" │├──────────────────────┼─────────────────┼────────┼───────┤│"KOYCHEV.DE" │"K0YCHEV" │"309" │"341" │├──────────────────────┼─────────────────┼────────┼───────┤│"Graphcool" │"graphcool" │"84" │"859" │├──────────────────────┼─────────────────┼────────┼───────┤│"adeeb" │"_adeeb" │"179" │"328" │├──────────────────────┼─────────────────┼────────┼───────┤│"ReactJS News" │"ReactJS_News" │"93" │"517" │├──────────────────────┼─────────────────┼────────┼───────┤│"Max Stoiber" │"mxstbr" │"102" │"450" │├──────────────────────┼─────────────────┼────────┼───────┤│"Caleb Meredith" │"calebmer" │"135" │"273" │├──────────────────────┼─────────────────┼────────┼───────┤│"Lee Byron" │"leeb" │"53" │"652" │
Cool, now we can combine our two statements. To save some repeated API calls, I just store the gender information on the user entity (also the accuracy and samples) so that we can reuse it later.
MATCH (u:Twitter:User)-[:POSTED]->(t:Tweet)// name has have at least 2 parts, and gender not yet retrievedWHERE u.name contains " " AND NOT exists(u.gender)
// compute the scoreWITH u, count(*) AS tweets, sum(t.favorites+size((t)<-[:RETWEETED|REPLIED_TO]-())) AS scoreWHERE tweets > 5 AND tweets * score > 100
// top 500 usersWITH u, tweets, score, head(split(u.name," ")) as firstnameORDER BY tweets * score DESC LIMIT 500
// call gender apiCALL apoc.load.json("https://gender-api.com/get?key=<key>&name="+firstname) YIELD value
// set result values as propertiesSET u.gender = value.gender, u.gender_meta = [value.accuracy,value.samples]
RETURN count(*)
So for the 500 top accounts with a space in their name, we got the gender predicted via the API. Now we can look at our resulting data, and hopefully find some women that we can recommend to Peggy.
MATCH (u:Twitter:User)-[:POSTED]->(t:Tweet)WHERE u.gender = "female" AND u.gender_meta[0] > 75 and u.gender_meta[1] > 10
WITH u, count(*) AS tweets, sum(t.favorites+size((t)<-[:RETWEETED|REPLIED_TO]-())) AS scoreORDER BY tweets * score DESC LIMIT 50
RETURN u { .screen_name, .name, .followers, .following, .statuses} as user, tweets, score;
Besides the funny (Ruby Inside, Else if), and the incorrectly classified (Jess,Brooke), we get a number of active women in the GraphQL community that were not recommended before:
ladyleet, _KarimaTounsya, thekamahele, lauralindal, thelamkin, eveporcello and several more.
I manually went over the screen-names, looked at these twitter profiles, and set a check-mark √ for female accounts and an ! for new names.
We found 22 women in total — which is of course not a lot if you look at the absolute number of people tweeting about GraphQL, but it is a start and hopefully growing quickly.
Now that we have our list, let’s put it to good use! Be sure to check out the work of these talented and active women and follow them on Twitter if you aren’t already. By recognizing their contributions, we can hopefully inspire more women to be active members of the GraphQL community and discover more names for our list in the future.
PS: We heard from Nikolas, the curator of @graphqlweekly, that our “this week in GraphQL” overview page helped them a lot in compiling the weekly newsletter. It also features a “Twitter Active” tab, which should help you to find people to follow, too.
We’re also happy to offer the community graph service to other communities, so feel free to reach out to us via devrel@neo4j.com, if you’re interested.
PPS: Thanks so much to Peggy Rayzis who started this engaging activity, provided very valuable feedback for this post, and gave her permission for publication. Make sure to follow her on Twitter and here on Medium.