
By Alex Bunardzic
Test Driven Development (TDD) is sometimes described as “writing tests first”. The TDD mantra states that we should not write code before we have written automated tests that exercise that code. Writing code first is considered suboptimal.
And of course, writing code first is how we develop software following the so-called waterfall model. In that model, we divide software development activities into stages. For example, we have a ‘requirements gathering’ stage, we have an ‘application building’ stage, we have an ‘application testing’ stage, we have an ‘application deployment’ stage and so on.
But how is that different from the agile methodology? Don’t we have the exact same stages in agile?
Agile Methodology vs Waterfall Methodology
Of course we do. The crucial difference is that in agile, those stages are not gated.
In waterfall, we gate the stages and execute them in strict sequence. This means we won’t begin building the shipping application until such time as the requirements have been gathered, completed, signed off on and frozen. Once requirements are frozen (and controlled by our change management policies), we move into the next stage (or phase) – application building.
And similarly, we won’t move into the testing stage until the entire application has been built and we have reached the code complete milestone, at which point code changes have been frozen.
Once code gets frozen (and code freeze is then controlled by our change management policies), we hand it off to the testers. The testing phase begins, and only once all testing has completed (and provided that no significant defects have been detected), do we move into the deployment phase.
In agile, we do all the above activities in parallel. At the same time. We keep working on user stories (specs) while simultaneously building the shipping application. As we’re building the application we are also testing it. And as we are building and testing the application, we are also deploying it.
We learn from the shipping application deployed to production and use that validated learning as the feedback that will inform new user stories. That way, the loop gets closed, and we’re iterating, improving the value incrementally.
The only way to enable such iterative value stream delivery is by relying on automated tests. And as we’ve described, those tests are being written very early in the game. Actually, tests must be written before we write shipping code.
Why then is the title of this article “Don’t Write All Your Tests First, Just Write One”? It sounds a bit confusing. Let’s unpack the meaning of this title. But first, here's an overview of what tech we'll be using:
The technology stack used for this exercise
In the attempt to keep the exercise simple and easy to follow, I have chosen .NET Core platform, together with xUnit.net testing platform. To follow the coding examples, please install .NET Core and xUnit.net.
In order to be able to run the sample code, please open ./tests/tests.csproj file and add this line to the ItemGroup:
<ProjectReference Include="../app/app.csproj" />
You’re now all set for following the coding exercises.
A simple example
To understand the difference between writing all tests first and writing one test first, it may be better to show rather than just tell.
So let’s try to build a simple example – for this exercise I’ve chosen a trivial case of calculating a tip at a restaurant. Often times we find ourselves in a position where we want to tip the restaurant for the service, but it’s tough to calculate percentages in our head. So a nifty little Tip Calculator could come in handy.
Here are the expectations:
As a patron
I want to calculate the total bill (total plus the tip)
Because I want to compliment the restaurant for the service
Scenario #1: Patron calculates the total for terrible service
Given that the restaurant total is $100.00
And the service was terrible
When the tip calculator calculates the total charge
Then tip calculator shows $100.00 total charge
Scenario #2: Patron calculates the total for poor service
Given that the restaurant total is $100.00
And the service was poor
When the tip calculator calculates the total charge
Then tip calculator shows $105.00 total charge
Scenario #3: Patron calculates the total for good service
Given that the restaurant total is $100.00
And the service was good
When the tip calculator calculates the total charge
Then tip calculator shows $110.00 total charge
Scenario #4: Patron calculates the total for great service
Given that the restaurant total is $100.00
And the service was great
When the tip calculator calculates the total charge
Then tip calculator shows $115.00 total charge
Scenario #5: Patron calculates the total for excellent service
Given that the restaurant total is $100.00
And the service was excellent
When the tip calculator calculates the total charge
Then tip calculator shows $120.00 total charge
Let’s now implement the above user story.
We see that the story has 5 acceptance criteria (a.k.a. scenarios). Now we move into the analysis phase – think about what should be the first functionality that our Tip Calculator application should implement. But first, let’s open the command line terminal and create the new directory:
md TipCalculator
cd TipCalculator
and create app and tests directories inside the TipCalculator directory.
Now cd tests and run:
dotnet new xunit
Then cd .. and cd app, then run:
dotnet new classlib
We’re now ready to boogie!
Open your favourite text editor (mine is Visual Studio Code) and set your mind on the expectations. What behaviour are we expecting from the Tip Calculator?
To narrow the scope of our expectations, it usually helps to take one acceptance criteria (i.e. one scenario) and focus on it first. Let’s take scenario #1:
Scenario #1: Patron calculates the total for terrible service
Given that the restaurant total is $100.00
And the service was terrible
When the tip calculator calculates the total charge
Then tip calculator shows $100.00 total charge
In case the service was terrible, we are not adding any tips, and Tip Calculator is calculating a $0.00 tip. So how do we automate that scenario?
My first expectation would be that we need to somehow inform the Tip Calculator that the service was terrible. We either type the word ‘Terrible’ into the input field, or we select ‘Terrible’ from the list of available service ratings.
So the first thing to do here is to articulate some expectations regarding Tip Calculator’s ability to get notified that the service was terrible.
I like to always start with the expectation that what the user inputs is valid. So I’d first write a test that checks if the rating ‘Terrible’ is recognized by the Tip Calculator as a valid rating.
Go to the tests directory, rename the autogenerated UnitTest1.cs file to TipCalculatorTests.cs and add the following test:
[Fact]
public void CheckIfRatingTerribleIsValid(){
var expectedResponseForValidRating = true;
var actualResponseForValidRating = false;
Assert.Equal(expectedResponseForValidRating,
actualResponseForValidRating);
}
Now go to the command line, cd tests, and run:
dotnet test
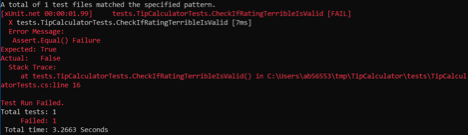
Of course, the above trivial test will fail, because we have hardcoded the values. But it’s always a good practice to make sure we see our tests fail before we proceed. Not observing a test fail may give us false sense of safety later on, if no tests fail and we end up thinking that everything works as expected.
A few more observations about the above test:
- It helps if the test name is descriptive. I chose
CheckIfRatingTerribleIsValidto communicate the fact that we must make sure our application is capable of recognizing our commands. - It also helps if the expected and actual variable names are descriptive. I chose
expectedResponseForValidRatingandactualResponseForValidRatingas fairly indicative of what our expectation in this test is, and also what actual value will theTip Calculatorproduce. - Test is a first-class source code and must be approached with equal care lavished upon the production code.
First design decision
At this point, we are forced to make a decision – how will our nascent Tip Calculator know if the service rating provided by the user is valid or not?
The design decision that comes to mind is that Tip Calculator must be able to store and retrieve some data. In this case, the data we’re interested in is the service rating.
If we go back to the user story and review the five acceptance criteria, we will see that the expectations are that Tip Calculator must be able to recognize five different service ratings:
- Terrible
- Poor
- Good
- Great
- Excellent
So the simplest way to get Tip Calculator to store that information would be to endow it with an array, or a list.
But rather than rushing in to implement that list, we should examine the expectations again, to see if there’s anything else we may have missed. And there is – not only must Tip Calculator be able to recognize valid service ratings, it also must be able to associate each rating with a percentage value.
Our analysis shows the following associations:
- Terrible => 0%
- Poor => 5%
- Good => 10%
- Great => 15%
- Excellent => 20%
In this case, a simple array or a simple list won’t be sufficient for holding the above associations. What’s the next simplest data structure that will allow us to implement these associations? After doing a little bit of research, we figure out that Hashtable is probably the most fitting data structure that can cover our needs with the least amount of ceremony.
We now navigate to the app directory and rename autogenerated Class1.cs file to TipCalculator.cs. We now want to add a Hashtable that will hold service ratings and the associated percentage values:
System.Collections.Hashtable ratingPercentages = new System.Collections.Hashtable();
Now is a good time to recall that TDD is focused on coupling the expectations to the application’s behaviour, not to the application’s structure. Knowing that, we need to modify our test to make Tip Calculator exhibit some behaviour. The test codifies some expectations with regards to how the application must behave, and the running application provides the evidence of the expected behaviour.
But what is the evidence of the application’s behaviour? There is no other way for us to assess and evaluate application’s behaviour other than through examining the values that the running application produces.
In this case, we are expecting the running application to produce values true or false (Boolean values) after we ask the application if certain value (i.e. service rating) is valid.
To teach the application how to behave in the expected fashion, we need to endow it with an API. In this case, we design the API as follows:
public bool CheckIfRatingIsValid(string rating)
In our test, we will modify the actual expected value to exercise the running application and collect the output value:

As you can see from the screenshot above, we have instantiated TipCalculator but when attempting to ask the instance to check if the supplied rating (“Terrible”) is valid, the editor is complaining that it cannot find that method.
Well of course, the method hasn’t been implemented yet. Now’s the time to go ahead and do it:
public bool CheckIfRatingIsValid(string rating) {
return false;
}
Now that the method is implemented, the test works; here is the complete listing:
using Xunit;
using app;
namespace tests {
public class TipCalculatorTests {
TipCalculator tipCalculator = new TipCalculator();
[Fact]
public void CheckIfRatingTerribleIsValid(){
var expectedResponseForValidRating = true;
var actualResponseForValidRating =
tipCalculator.CheckIfRatingIsValid("Terrible");
Assert.Equal(expectedResponseForValidRating,
actualResponseForValidRating);
}
}
}
We see from the above example that we’re cheating again (we have hardcoded return false; in our newly minted method). What’s the point of beating around the bush and merely creating skeletons and scaffoldings instead of rolling up our sleeves and doing actual coding? Let’s discuss this important topic.
Discussion about our first design decision
We’re illustrating here how to do TDD step-by-step. The funny part is that this step-by-step illustration is actually the exact way how we do TDD: step-by-step. There is no other way to do TDD than by doing it step-by-step. One step at a time.
How’s that different from any other way of doing software development? Don’t we also do everything step-by-step even when not following TDD methodology? Well, not really. Let me explain:
TDD to me feels like riding a galloping horse. We’re moving swiftly toward our goal, but we’re frequently touching the ground (the galloping horse is every now and then hitting the ground in order to bounce off and run fast).
In comparison, when I’m doing software development without TDD, it feels to me like I’m flying a kite. I’m making swift moves with the kite, but I never touch the ground, not even once. By the time I land the kite, the landing place may not be where I intended the kite to go (it’s very hard to control the direction of a kite if it’s flying in a strong wind).
With TDD, any time we make a change to the code (both the test code and the shipping application code), we run the tests and so we touch the ground. We are galloping, but at the same time we need this frequent grounding. We need to see whether we’re going in the right direction and also whether we’ve broken anything during our galloping. Our tests are the Oracle who keeps telling us if everything works as expected or if something started misbehaving.
Making changes to the code is a risky business. TDD provides a nice harness that is both guiding our design decisions and ensuring we don’t mess up something that we’ve already confirmed works to our expectations.
Replace hardcoded value with actual processing logic
Let’s now replace the hardcoded value with actual running code. We first teach our Tip Calculator that there is a service rating called “Terrible” and that tip percentage associated with this rating is 0:
public bool CheckIfRatingIsValid(string rating) {
ratingPercentages.Add("Terrible", 0);
return false;
}
Our Tip Calculator is now knowledgeable about the fact that there is a service rating labeled “Terrible” and the tip percentage associated with terrible service is 0%. Great, but we’re still returning hardcoded value false. Time to replace it with actual calculation:
public bool CheckIfRatingIsValid(string rating) {
ratingPercentages.Add("Terrible", 0);
return ratingPercentages.ContainsKey(rating);
}
Run the test again:
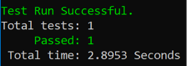
Great, but the code still looks contrived. We are loading the “Terrible” value into the instance of Hashtable ratingPercentages and then immediately checking to see if that value exists in the Hashtable. Now that we have moved from the failing test (Red) to the passing test (Green), it’s time to perform the third step in the TDD loop – Refactor.
Refactoring is basically the activity of modifying the code structure without affecting the code behaviour. Our task here is simple: extract the code responsible for populating of the Hashtable ratingPercentages into a separate block of code.
The most natural place for this loading is in the block of code that is doing the initialization of the Tip Calculator – the constructor method. After refactoring, our shipping application source code looks like this:
using System.Collections;
namespace app {
public class TipCalculator {
private Hashtable ratingPercentages = new Hashtable();
public TipCalculator() {
ratingPercentages.Add("Terrible", 0);
}
public bool CheckIfRatingIsValid(string rating) {
return ratingPercentages.ContainsKey(rating);
}
}
}
Run the test again, and it passes (we’re in green). We have modified the structure of the code without modifying its behaviour! Good job.
Flip the coin
Any time we satisfy a positive expectation, it is a prudent practice to turn things on their head and describe the negative expectation.
At this point, since we’ve satisfied that a legitimate service rating value is found in the Tip Calculator, we want to ensure that non-legitimate values are not found in the Tip Calculator.
What do we mean by non-legitimate values? Any value other than “Terrible”, “Poor”, “Good”, “Great” and “Excellent”. Time to write the new expectation (i.e. test):
[Fact]
public void CheckIfRatingWhateverIsValid() {
var expectedResponseForValidRating = true;
var actualResponseForValidRating =
tipCalculator.CheckIfRatingIsValid("Whatever");
Assert.Equal(expectedResponseForValidRating,
actualResponseForValidRating);
}
Run the tests:
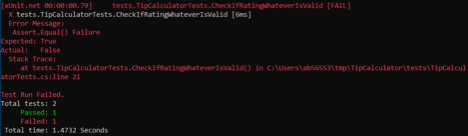
Fails. As expected. (We specified that our expectation when supplying the service rating as “Whatever” should be true. In reality, it is false, because our Tip Calculator does not contain value “Whatever”.)
Fix the test (change the expectedResponseForValidRating from true to false) and run it again:
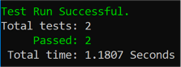
A moment of reflection: why did we fake the first test run and made it fail? Because we always want to make sure we observe our new test failing. That way, we’ll know that in the future any successful passing of the test is not merely a false positive.
In praise of steady state
Software engineering is a balancing act between steady state and periods of unstable state. What do we mean by steady state?
If we have a system (a running application) that behaves the way we expect it to behave (i.e. it produces values we have specified as expected values), we declare that the system is in a steady state. It is running, and delivering some value.
That value delivery is still partial. In our case, the only value to the users this Tip Calculator delivers is its ability to recognize service rating “Terrible” as a legitimate rating. In addition, it is capable of informing us that service rating “Whatever” is not a legitimate rating.
That’s not much, but still is better than nothing. And good news – our running application is currently in a steady state. Now we want to look into how to add more valuable behaviour to our Tip Calculator. And the only way to add more value is by making some changes.
Any time we make a change to our application, we disturb its steady state. This disturbance is risky. It may mean our changes could break something that is already working. Because of that concern, we strive to make the duration of this unstable state as short as possible.
Remember how we compared TDD to riding a galloping horse? When the horse is in flight (i.e. not touching the ground) it is advancing toward our goal, but it’s not in the steady state. Only when the horse touches the ground does its state stabilize.
TDD encourages making small changes (in flight) and immediately grounding the system by verifying that it is back in the steady state. We value steady state despite the fact that we eagerly embrace changes. Without changes, we won’t be able to deliver value, but we must do it in a very deliberate, careful fashion.
When doing TDD, we treat changes to steady state like walking on eggshells. No matter how sure we may be in knowing what and how we’re doing software engineering, it is prudent to still let failing tests guide our decisions.
Check if correct tip percentage is associated with service rating
Let’s now introduce another change into our application – a test to verify if correct tip percentage is associated with service rating “Terrible”. Remember that we populated the instance of Hashtable ratingPercentages with the following values:
ratingPercentages.Add("Terrible", 0);
We have written a test that verifies that our Hashtable ratingPercentages does contain legitimate service rating “Terrible”. Now we need a test that verifies that service rating “Terrible” means that the tip percentage for that rating is 0.
[Fact]
public void CheckIfRatingTerribleHasZeroPercentTip() {
var expectedZeroPercentForTerribleRating = 0;
var actualZeroPercentForTerribleRating = 10;
Assert.Equal(expectedZeroPercentForTerribleRating,
actualZeroPercentForTerribleRating);
}
The new test CheckIfRatingTerribleHasZeroPercentTip should fail:
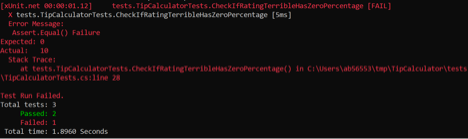
Again, we’re purposefully hard coding wrong actual values just so that we could observe our brand new test fail. Now we must replace hard coded value with the actual call to the Tip Calculator’s method that returns tip percentage for the service rating:
[Fact]
public void CheckIfRatingTerribleHasZeroPercentTip() {
var expectedZeroPercentForTerribleRating = 0;
var actualZeroPercentForTerribleRating =
tipCalculator.GetPercentageTipForRating("Terrible");
Assert.Equal(expectedZeroPercentForTerribleRating,
actualZeroPercentForTerribleRating);
}
As in the previous case, we have invented a new API for Tip Calculator. We call this new capability GetPercentageTipForRating("Terrible"). It takes the value of the service rating and returns the tip percentage for that rating.
Flip over to the app/TipCalculator.cs and add the hard coded skeleton of the new method:
public int GetPercentageTipForRating(string rating) {
return 10;
}
Running the test fails again, because we have hard coded the return value. Let’s replace it with actual processing:
public int GetPercentageTipForRating(string rating) {
int tipPercentage = Int32.Parse(ratingPercentages[rating].ToString());
return tipPercentage;
}
Run the test again:
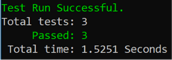
All three tests pass – we’re in green, we’re back to steady state!
What tip percentage do we expect for non-legitimate service ratings?
Many years of experience in the field taught me to be a bit pessimistic. Now that we have our application back in the steady state and delivering value (answering questions about legitimate service ratings and also giving us correct tip percentage for the “Terrible” rating), we need to see what happens when we run our application by giving it non-legitimate service rating value (for example, by giving it service rating “Whatever”).
Time for leaving the steady state yet again. We will write another test:
[Fact]
public void CheckIfRatingWhateverHasNegativeOnePercentTip() {
var expectedZeroPercentForWhateverRating = -1;
var actualZeroPercentForWhateverRating =
tipCalculator.GetPercentageTipForRating("Whatever");
Assert.Equal(expectedZeroPercentForWhateverRating,
actualZeroPercentForWhateverRating);
}
We are describing our expectation when Tip Calculator is asked to return tip percentage for service rating “Whatever”. Because service rating “Whatever” is a non-legitimate rating, we are expecting Tip Calculator to return tip percentage of value -1.
This test now precipitates one improvement to our shipping code. We need to add some logic to first check whether the supplied service rating is legitimate or not. Only if it is legitimate do we ask Hashtable ratingPercentages to tell us what the associated value of the tip percentage is. If the supplied service rating is non-legitimate (for example, if it is “Whatever”) we bypass talking to Hashtable ratingPercentages and simply return -1.
public int GetPercentageTipForRating(string rating) {
int tipPercentage = -1;
if(CheckIfRatingIsValid(rating)) {
tipPercentage = Int32.Parse(ratingPercentages[rating].ToString());
}
return tipPercentage;
}
Run the tests, and all 4 tests pass:
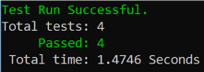
We are back to the steady state. Another short excursion into the volatile area, and another swift victory and a safe return to steady, imperturbable state.
Populate other service rating tip percentages
Now is a good time to take a breather and make less risky changes, following the already established pattern. Leave the safety of the steady state and make short trips into the volatile territory by adding a new test to verify if service rating “Poor” is a valid, legitimate rating:
[Fact]
public void CheckIfRatingPoorIsValid() {
var expectedResponseForValidRating = true;
var actualResponseForValidRating =
tipCalculator.CheckIfRatingIsValid("Poor");
Assert.Equal(expectedResponseForValidRating,
actualResponseForValidRating);
}
Running this test will fail:
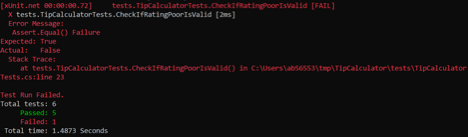
Service rating “Poor” hasn’t been implemented yet. To make the test pass, implement service rating “Poor” by adding this line to the TipCalculator constructor:
ratingPercentages.Add("Poor", 5);
Run the tests, and we’re back to safety:
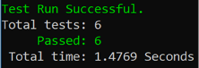
We’re enjoying steady state with 6 tests successfully passing.
Now that we have added service rating “Poor” associated with the 5% tip, let’s write a test that will describe that expectation:
[Fact]
public void CheckIfRatingPoorHasFivePercentTip() {
var expectedZeroPercentForPoorRating = 5;
var actualZeroPercentForPoorRating =
tipCalculator.GetPercentageTipForRating("Poor");
Assert.Equal(expectedZeroPercentForPoorRating,
actualZeroPercentForPoorRating);
}
The tests run successfully, and we’re back to being safe in the steady state.
I will leave it to the reader to make the changes that will drive the implementation of the service ratings “Good”, “Great” and “Excellent”. At the end of the exercise you should have your system back in the steady state with 12 tests successfully passing:
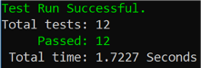
Calculate grand total given the total and the service rating
We are now ready for the final step – given the total bill and the service rating, we expect Tip Calculator to calculate tip percentage and add it to the total, producing the grand total to be paid to the restaurant.
As we always do, first we describe the expectation:
[Fact]
public void CalculateTotalWithTip() {
var expectedTotalWithTip = 135.7;
var actualTotalWithTip = 200.0;
Assert.Equal(expectedTotalWithTip, actualTotalWithTip);
}
As usual, we first hard code some expectations that we know are going to fail. This is so that we observe our new test failing:
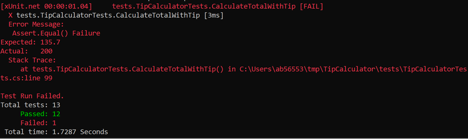
Time to implement processing logic that will calculate correct total with tip. Given the total of $118.0, and the service rating “Great” (15% tip), we’re expecting the total to be $135.7:
[Fact]
public void CalculateTotalWithTip() {
var rating = "Great";
var total = 118;
var expectedTotalWithTip = 135.7;
var actualTotalWithTip = tipCalculator.CalculateTotalWithTip(total,
rating);
Assert.Equal(expectedTotalWithTip, actualTotalWithTip);
}
We have designed a new API the Tip Calculator – a method called CalculateTotalWithTip(total, rating). It takes the total value and the service rating and returns the total with tip. The implementation of the method looks like this:
public double CalculateTotalWithTip(double total, string rating) {
double totalWithTip = -1;
if(CheckIfRatingIsValid(rating)) {
int percentage = GetPercentageTipForRating(rating);
totalWithTip = total + ((total/100) * percentage);
}
return totalWithTip;
}
Run the tests, and we’re back to steady state:
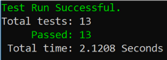
Are we done here?
No, not yet. Even when all tests are in green and we’re back to the steady state, there are still a couple of things we need to do.
To begin with, we need to add a pessimistic expectation for our Tip Calculator calculation of total with the tip based on the service rating:
[Fact]
public void CalculateTotalWithTipForNonlegitimateRating() {
var rating = "Meh";
var total = 118;
var expectedTotalWithTip = 135.7;
var actualTotalWithTip = tipCalculator.CalculateTotalWithTip(total,
rating);
Assert.Equal(expectedTotalWithTip, actualTotalWithTip);
}
Running the tests produces one failing test:
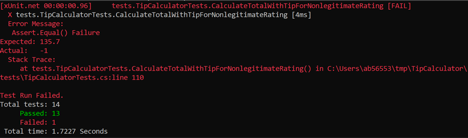
Our expectation for non-legitimate service rating (“Meh”) was incorrect. The actual total is -1, so we need to adjust our expectation by replacing 135.7 with -1. Run the tests again, and we’re back to the steady state!
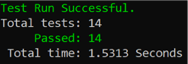
We now have 14 tests, they all successfully pass, and our Tip Calculator works according to our expectations and satisfies the acceptance criteria.
We’re almost done. One more sanity check before we can confidently ship our shiny new Tip Calculator – we must run mutation testing.
Our mutation testing framework will mutate the shipping code, one line at a time, and will run all tests for each individual mutation.
If the tests complain about the mutated code, all is good, we have killed the mutant. If the tests don’t complain, we’re in trouble. We have a surviving mutant in our codebase, which means there are lines of code in our repo that are doing something for which we haven’t provided any expectations.
Let’s run mutation testing to see how solid our solution is. Good news – our solution has killed 100% of mutants!
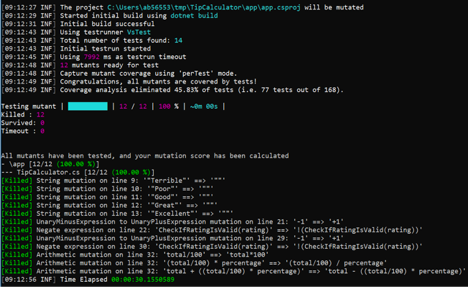
Mutation testing has given our shipping application a clean bill of health. Our Tip Calculator seems to be in good shape.
Red-Green-Refactor-Reflect
Let’s review our Tip Calculator building exercise. We started the process by describing our expectations using the classical user story format. User story (as the name implies) is focused on describing scenarios that fulfill end user’s goals.
In this case, the simple goal is to calculate the tip amount from the supplied service rating and the restaurant bill total. The calculated tip amount is then automatically added to the total.
From there we proceeded to build our shipping application by following the TDD methodology. As we’ve demonstrated, the methodology consists of writing a failing test, observing it fail (the Red phase of TDD), then immediately making code changes that ensure the test passes (the Green phase of TDD). Once the test passes, we move into the Refactor phase (we restructure the code without affecting its behaviour). That way, we make sure our code is not expensive to change.
A proper TDD practice also mandates frequent retrospective – we call it reflection. We stop and think about the things we’ve accomplished thus far, to see if we could learn from our recent experiences. This reflection fortifies the process, as it relies on frequent and tight feedback provided by the failing, then succeeding tests.
I have already compared Test Driven Development to the experience of riding a galloping horse. While riding a horse, we’re alternating between flying through the air (i.e. speed achieved when the horse leaps from the ground) and steering the horse. It is impossible to steer the horse while we’re off the ground, up in the air. At that point, we gain speed, but we cannot make any changes of the direction. It is only once the horse touches the ground that we can make a change in direction.
In TDD, we strive to touch the ground as frequently as possible. The longer the leaps we make without touching the ground, the less chance we have for correcting the course.
I also compared software development practices that don’t follow TDD principles to the experience of flying a kite. When flying a kite, we never touch the ground. It is an exhilarating feeling of letting the wind pick the kite up and bounce it up in the air. We can achieve considerable speed that way. But we struggle in such situations to maintain desired course. And after we eventually land the kite, it usually does not land in the spot we originally wanted it to land.
Why is the emphasis of this article on “don’t write tests first”? Many software engineers who are not familiar with agile practices as implemented in TDD usually either claim that writing automated tests isn’t necessary, or claim that automated tests should be written after the code is complete.
Once they start learning about agile and TDD, they may reconsider their practices and decide that writing tests before writing implementation code may make more sense. Still, because of the ingrained waterfall mentality, some of those engineers make the mistake of writing all tests first, and only then move into writing the code.
That approach is completely wrong. It is equivalent to the traditional waterfall approach where we go through the development process by respecting gated phases.
First we write the requirements (in this case, requirements would be expectations written in the form of automated tests). Only once all the requirements (i.e. automated tests) have been written, signed off and frozen, do we move into the next gated phase – write the code for the shipping application.
TDD is the exact opposite of the “write tests first” approach. In TDD, we always write only one test. That test describes a desired behaviour. The desired behaviour does not exist yet (that’s why it is desired), and the test fails.
We then immediately move into making changes to the code in the attempt to create the desired behaviour. Once desired behaviour is created, it gets validated by the test, and if the expectations of the test are satisfied, we move into refactoring the code (to satisfy nonfunctional requirements, such as cost of change).
We practice a rigorous discipline to never succumb to the temptation to write more than one test at a time. That way, we ensure that we keep touching the ground as frequently as possible.
We prefer to remain ‘in flight’ for the shortest possible time. We are ‘in flight’ during that period when the desired behaviour described in the test has not materialized yet. The smaller the expected and desired behaviour is, the shorter will be our ‘in flight’ trajectory. That way, we keep touching the ground often, which gives us a chance to adjust the steering.
Conclusion
Building a simple Tip Calculator is a toy sized problem, and using that exercise to illustrate TDD methodology is not necessarily providing a convincing argument in favour of TDD. Still, within the constraints of a technical article, going over this hands-on exercise may provide valuable insights into the benefits of adopting TDD.
We would still argue that the real benefits of TDD only become apparent when dealing with much larger, more complex software engineering efforts. The ability to remain grounded while making potentially risky changes to a large, complex system is often a life saver.
In addition to that, building software using TDD methodology results in much less rework. TDD drives high degree of modularization, which results in high cohesiveness of the modules and low coupling between the modules.
All these characteristics produce a shipping application whose codebase is easy and inexpensive to change. And lowering the cost of change has proven to be the best way on the path to embracing changes and abandoning the concept known as ‘scope creep’.
Bottom line, TDD enables software engineering teams to deliver high degree of flexibility to the business.