

If you are coding an international app that uses multiple languages, you'll need to know about encoding. Or even if you're just curious how words end up on your screen – yep, that's encoding, too.
I'll explain a brief history of encoding in this article (and I'll discuss how little standardisation there was) and then I'll talk about what we use now. I'll also cover some Computer Science theory you need to understand.
Introduction to Encoding
A computer only can understand binary. Binary is the language of computers, and is made up of 0's and 1's. There is nothing else allowed. One digit is called a bit, and a byte is 8 bits. So 8 0's or 1's make up one byte.
Everything eventually ends up as binary – programming languages, mouse moves, typing, and all the words on the screen.
If all the text you're reading was once binary too, then how do we turn binary into text? Let's look at what we used to do back in the beginning.
A Brief History of Encoding
In the early days of the internet, it was English only. We didn't need to worry about any other characters and the American Standard Code for Information Interchange (ASCII) was the character encoding that fit this purpose.
ASCII is a mapping, from binary to alphanumeric characters. So when the PC receives binary:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100
With ASCII it can translate that into "Hello world".
One byte (eight bits) was large enough to fit every English character, and some control characters too. Some of these control characters were used for instruments called teleprinters, so at the time they were useful (not so much now!)
But the control characters were things like 7 (111 in binary) that would make a bell sound on your PC, 8 (1000 in binary) that would print over the last character it just printed, or 12 (1100 in binary) that would clear a video terminal from all the text just written.
Computers at this time were using 8 bits for one byte (they didn't always), so there were no issues. We could store all our control characters, all our numbers, all the English characters and have some left! Because one byte can encode 255 characters, and ASCII only needed 127 characters. So we had 128 encodings that were unused.
Let's look at an ASCII table here to see every character. All lowercase and uppercase A-Z and 0-9 were encoded to binary numbers. Remember the first 32 are unprintable control characters.
ASCII Character Table
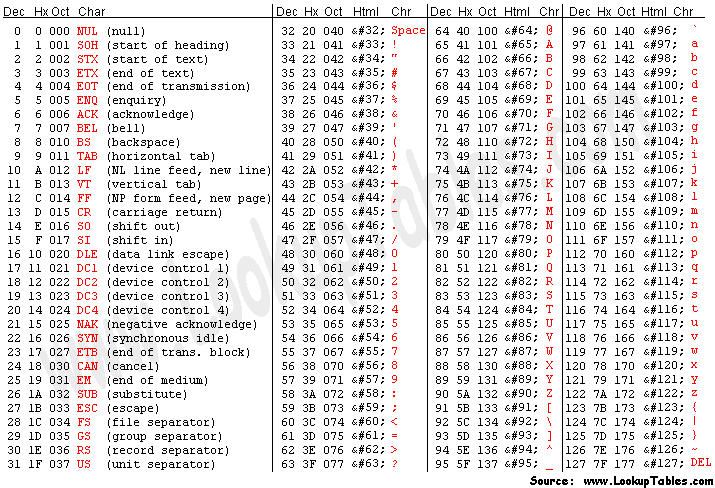
Can you see how it ends with 127? We have some spare room at the end.
Issues with ASCII
The spare characters were 127 through to 255. People began to think about what would be best to fill those remaining characters. But everyone had different ideas about what those final characters should be.
The American National Standards Institute (ANSI - don't get confused with ASCII) is a standards body for establishing standards across lots of different fields. They decided what everyone was doing with 0-127, which is what ASCII was already doing. But the rest were open.
No one was debating what 0-127 in the ASCII encoding was. The problem was with the spare ones.
Below is what the first IBM computers did with the 128-255 encodings for ASCII.
 Some squiggles, some background icons, math operators and some accented characters like é.
Some squiggles, some background icons, math operators and some accented characters like é.
But other computers didn't all follow this. And everyone wanted to implement their own encodings for the end of ASCII.
These different endings for ASCII were called code pages.
What are ASCII Code Pages?
Here's a collection of over 465 different codepages! You can see that there were multiple codepages EVEN for the same language. Greek and Chinese both have multiple codepages, for example.
So how on EARTH were we ever going to standardise this? Or make it work between differing languages? Between the same language with different codepages? In a non English language?
Chinese has over 100,000 different characters. We don't even have enough spare characters for Chinese, let alone agreeing that the final characters should be Chinese ones. This isn't looking so good.
This problem even has its own term: Mojibake.
It's garbled text you may sometimes see from decoding text, but using the wrong decoding. It means character transformation in Japanese.
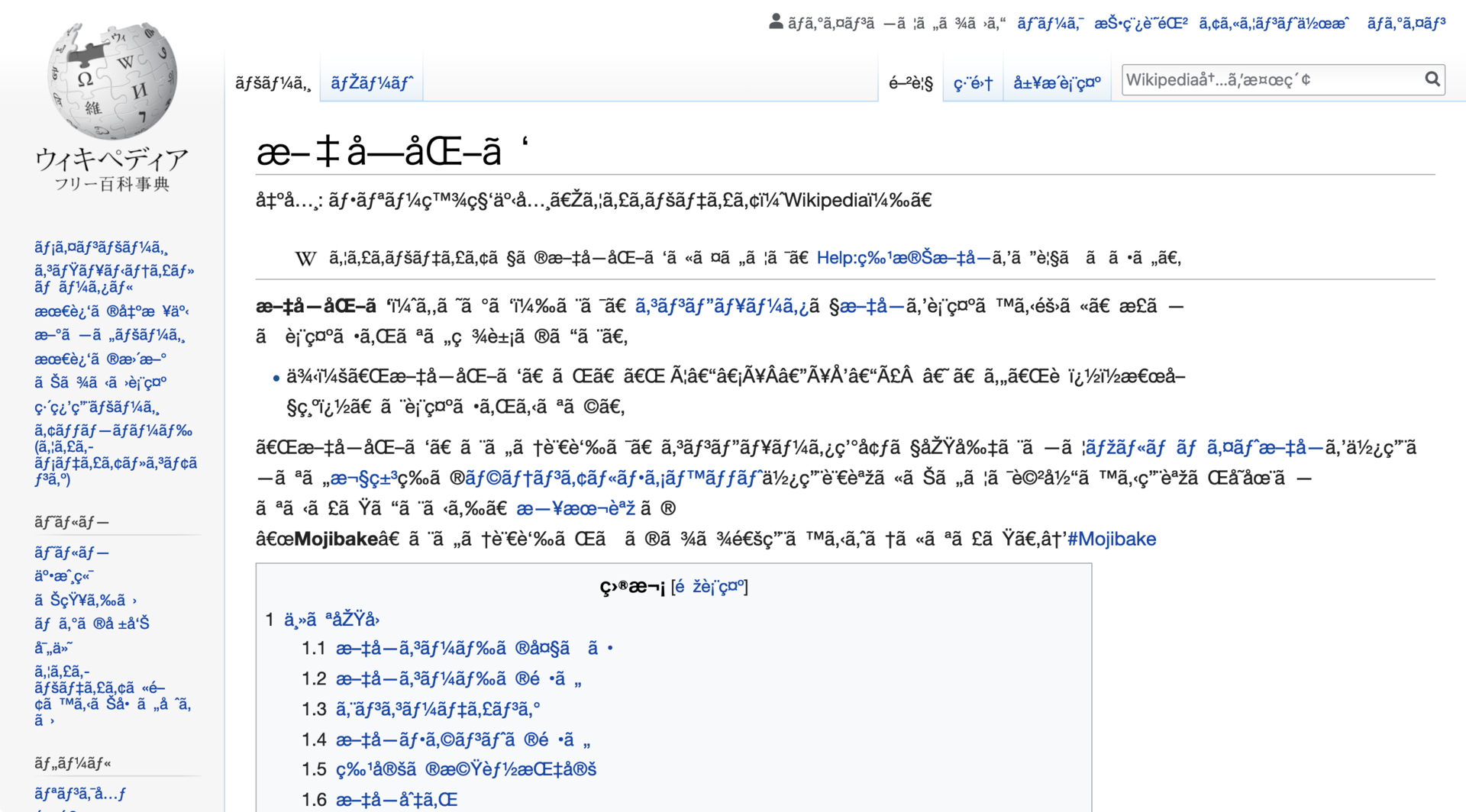 Example of completely garbled text (mojibake).
Example of completely garbled text (mojibake).
This sounds a little insane...
Exactly! We will have zero chance of reliably interchanging data.
The internet is just a huge connection of computers around the world. Imagine if all these countries decided what they each thought the standards should be. If the Greek computers only accepted Greek and the English computers only sent English...? You would just be shouting into an empty cave. No one would understand you. And no one would be able to decode the nonsense.
ASCII wasn't fit for real life use. In a global, connected internet, we had to evolve, or else forever deal with hundreds of codepages.
��� Unless you ������ fancied trying ��� to ��� read paragraphs like this. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Along Came Unicode
Unicode is sometimes called the Universal Coded Character Set (UCS), or even ISO/IEC 10646. But Unicode is its more common name.
But, this is where Unicode entered the scene to help solve the problems that encoding and code pages were causing.
Unicode is made up of lots of code points (mapping lots of characters from around the world to a key that all computers can reference.) A collection of code points is called a character set - which is what Unicode is.
We can map something abstract to a letter we want to reference. And it does every character! Even Egyptian Hieroglyphs.
Some people did all the hard work of mapping what each character would be (in all the languages) to a key that we could all access. They look like this:
"Hello World"
U+0048 : LATIN CAPITAL LETTER H
U+0065 : LATIN SMALL LETTER E
U+006C : LATIN SMALL LETTER L
U+006C : LATIN SMALL LETTER L
U+006F : LATIN SMALL LETTER O
U+0020 : SPACE [SP]
U+0057 : LATIN CAPITAL LETTER W
U+006F : LATIN SMALL LETTER O
U+0072 : LATIN SMALL LETTER R
U+006C : LATIN SMALL LETTER L
U+0064 : LATIN SMALL LETTER D
The U+ lets us know it's the Unicode standard, and the number is what results when the binary get's transformed to numbers. It uses hexadecimal notation which is just a simpler way of representing binary numbers. You don't have to worry too much about the hexadecimal here, though.
Here's a link where you can type whatever you want into the text box, and see the Unicode character encoding. Or look at all 143,859 Unicode character points here. You can also see where each character is from in the world!
I just want to be clear. At this point we have a big dictionary of code points mapping to characters. A really big character set. Nothing more.
There's one final ingredient we need to add to our mix.
Unicode Transform Protocol (UTF)
UTF is a way we encode Unicode code points. The UTF encodings are defined by the Unicode standard, and are able to encode every single Unicode code point we need.
But there are different types of UTF standards. They differ depending on the amount of bytes used to encode one code point. It also depends on whether you're using UTF-8 (one byte per code point), UTF-16 (two bytes per code point) or UTF-32 (four bytes per code point).
If we have these different encodings, how do we know which encoding a file will use? There's a thing called a Byte Order Mark (BOM) - sometimes referred to as an Encoding Signature. The BOM is a two-byte marker at the beginning of a file that tells what encoding the file is using.
UTF-8 is the most used on the internet, and is also specified in HTML5 as the preferred encoding for new documents, so I'll spend the most time explaining this one.
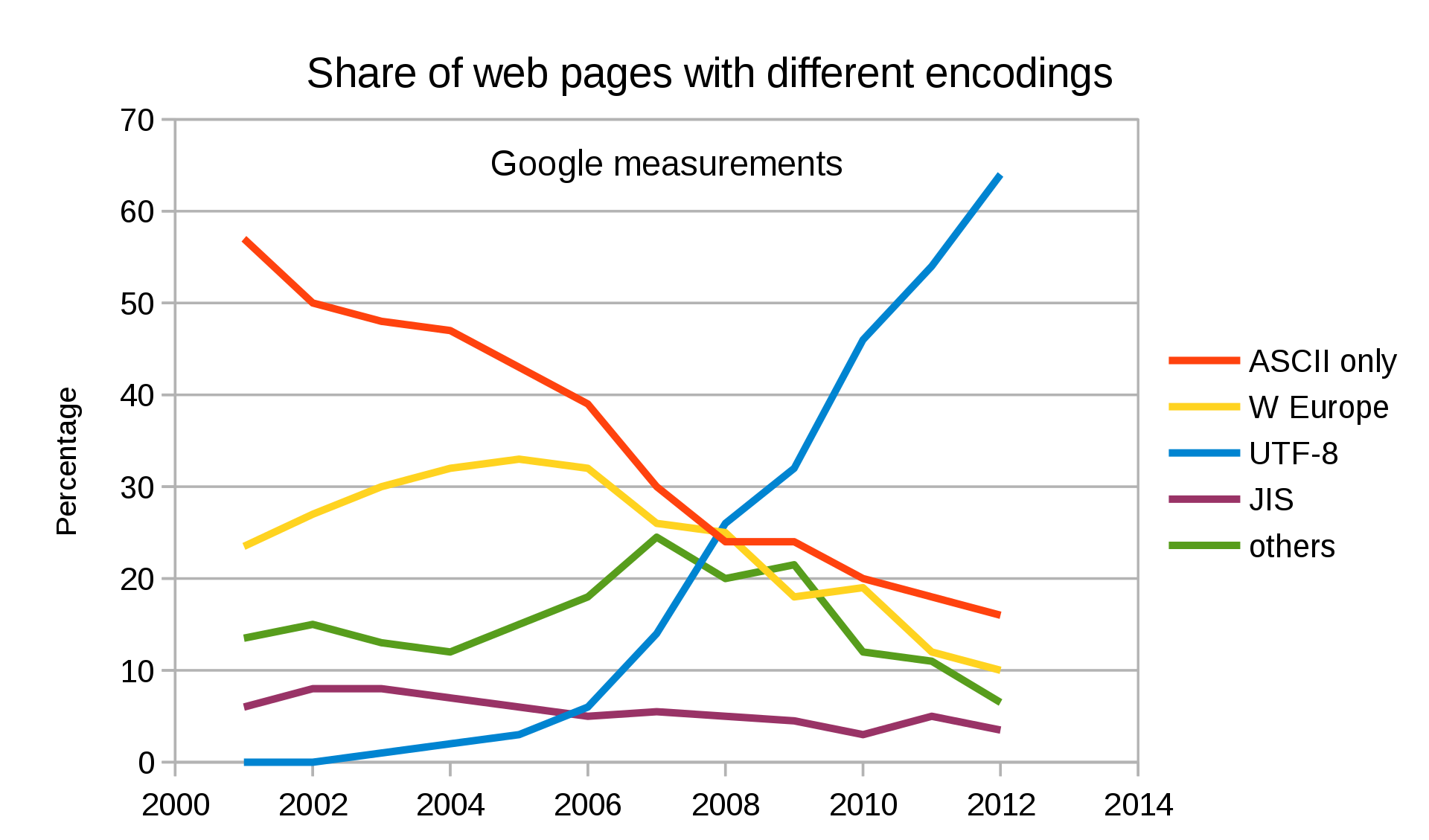 You can see in the diagram even from 2012, UTF-8 was widely becoming the most used encoding. And for the web it still is.
You can see in the diagram even from 2012, UTF-8 was widely becoming the most used encoding. And for the web it still is.
 _W3 diagram to show how well used UTF-8 is used on a variety of websites._
_W3 diagram to show how well used UTF-8 is used on a variety of websites._
What is UTF-8 and How Does it Work?
UTF-8 encodes all the Unicode code points from 0-127 in 1 byte (the same as ASCII). This means that if you were coding your program using ASCII, and your users used UTF-8, they wouldn't notice anything was wrong. Everything would just work.
Just remember how strong a selling point this is. We needed to remain ASCII backwards compatible while UTF-8 was being implemented and used by everyone. It doesn't break anything currently being used.
Because it's called UTF-8, remember that's the minimum number of bits (8 bits being one byte!) that a code point will be. There are other Unicode characters that are stored in multiple bytes (up to 6 bytes depending on the character). This is what people mean when the encoding is called variable length.
It might be more, depending on the language. English is 1 byte. European (Latin), Hebrew and Arabic are represented with 2 bytes. 3 bytes are used for Chinese, Japanese, Korean and other Asian characters. You get the idea.
When you need a character to span more than one byte, you have a bit combination to identify a continuation sign, saying this character is continued over the next several bytes. So you’ll still only use one byte per character for English, but if you need a document to contain some foreign characters, you can do that too.
And now, wonderfully, we can all agree on what the Sumerian cuneiform characters encoding is (𒀵 𒁷𒂅 𒐤), as well as some emoji's 😉😉 so we can all communicate!
The high level overview is: You first read the BOM so you know your encoding. You decode the file into Unicode code points, and then represent the characters from the Unicode character set into characters drawn onto the screen.
A Final Word About UTF
Remember, encoding is key. If I send the complete wrong encoding you can't read anything. Be aware of it when receiving or sending data. Often it is abstracted away in the tools you use everyday, but as programmers it's important to understand what is happening under the hood.
How do we specify our encodings, then? Because HTML is written in English, and almost all encodings can deal with English fine. We can embed it right at the top in the <head> section.
<html lang="en">
<head>
<meta charset="utf-8">
</head>
It's important to do this at the very start of the <head>, as the parsing of the HTML may have to start again if the encoding it's currently using is wrong.
We also can get the encoding from the Content-Type header from the HTTP request/ response.
If an HTML document doesn't contain the encoding tag, the HTML5 spec has some interesting ways it can guess the encoding called BOM sniffing. This is where it guesses the encoding from the Byte Order Mark (BOM) we discussed earlier.
So is that it?
Unicode isn't finished. Like any standard, we add, remove and make new proposals to the standard. No specification is ever considered "complete".
There are generally 1 or 2 release a year, and you can find them here.
Recently I read about a very interesting bug around Twitter rendering Russian Unicode characters incorrectly.
If you have read this far, congratulations – it's a lot to digest.
I would encourage you to do one last piece of homework.
Look at how broken websites can really be when the encoding is wrong. I used this Google Chrome extension and changed my encoding and tried to read webpages. The message was completely unclear. Try and read this article. Try and navigate Wikipedia. See Mojibake for yourself.
It helps to see how important encoding truly is.

Conclusion
In my time spent researching and trying to simplify this article, I learned about Michael Everson. Since 1993, he has proposed over 200 Unicode changes, and has added thousands of characters to the standard. As of 2003, he was credited as the leading contributor of Unicode proposals. He is one huge reason why Unicode is what it is. Very impressive, and he has done a great deal for the Internet as we know it.
I hope this has explained a good overview of why we need encodings, what problems encoding solves, and what happens when it goes wrong.
I share my writing on Twitter if you enjoyed this article and want to see more.