
By Hrishikesh Pathak
PDF stands for portable document format. PDFs were designed by Adobe in the 90s for Windows. They are self-contained documents with support for nearly all major operating systems.
But sometimes you'll need to modify a PDF to suit your needs and not just view it. Unfortunately, the available software meant for PDFs often falls short of your specialized requirements.
But you are a programmer, right? Why not make some software that helps the PDF work as you want it to? Well, this is the inspiration for this article.
In this article, we'll explore all the popular PDF-related libraries in JavaScript. Why JavaScript? Because it has some pretty decent PDF packages available, and people like it. Especially myself.
The PDF Viewer Project You Will Build in this Tutorial
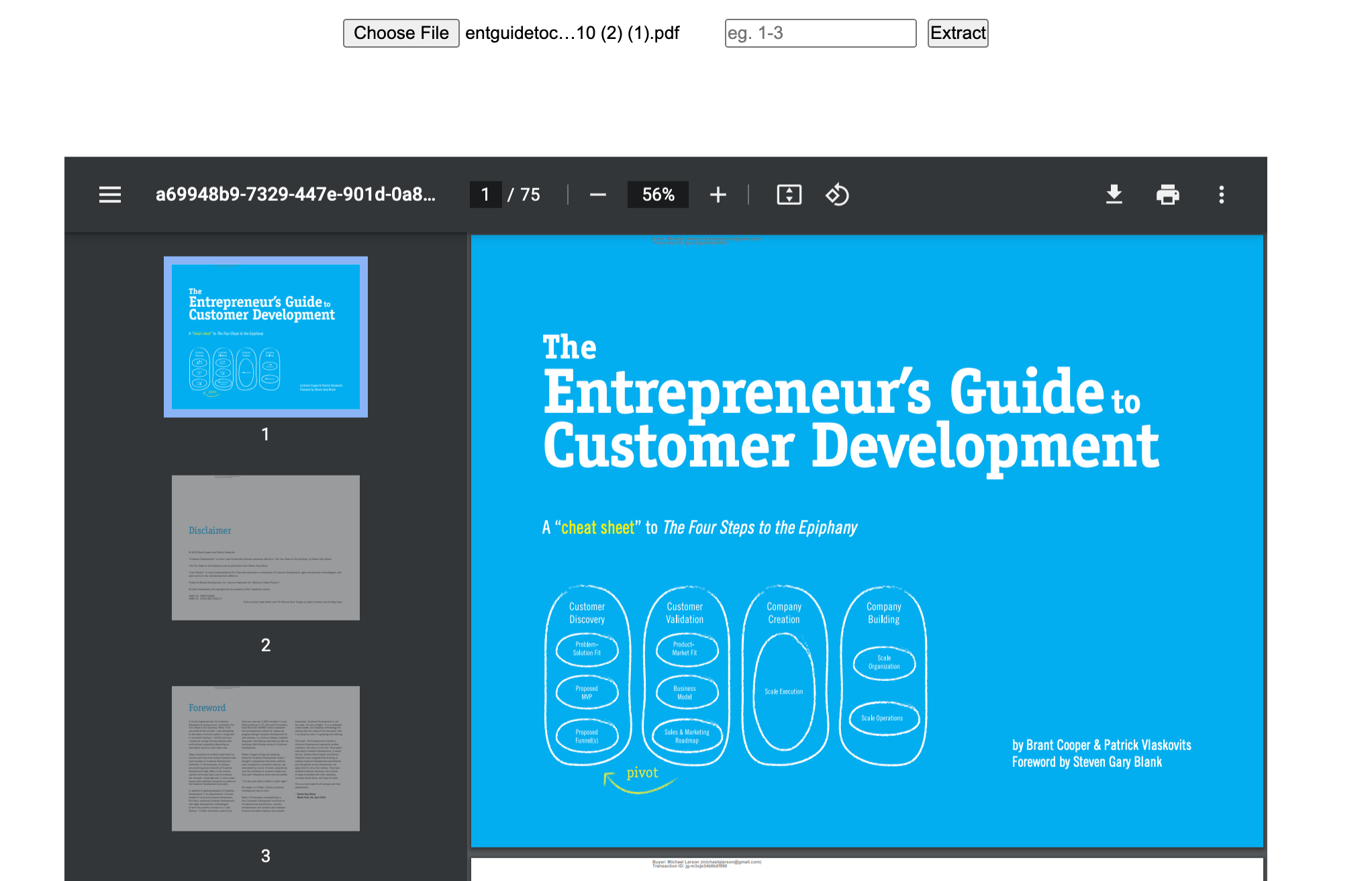 A screenshot of the PDF viewer you'll build
A screenshot of the PDF viewer you'll build
Here is a live demo of what you will build during this tutorial.
- First, we'll explore some popular PDF packages out there for PDF-related work in JavaScript. Then we'll compare them and find the best package that suits our requirements.
- Next we'll load an existing PDF and extract some pages from it. The extracted pages will make a new PDF document.
- Then we'll render the new PDF (that we made in the 2nd step) inside the browser.
- Finally, we'll download the new PDF for later use.
So these are all the steps we'll go through here. I hope you're excited to see the results. Let's dive in.
PDF Libraries for JavaScript
I've discovered two main types of PDF libraries in JavaScript. One is for PDF rendering and the other is for PDF manipulation (or modification). I found a bunch of PDF libraries after searching for an hour or so, and these are my best picks.
All the packages listed here are free and open-source packages. You can find all of these packages in the npm registry.
pdfjs
This package is made by Mozilla, the company behind the Firefox web browser. pdfjs is a web standards-based platform for parsing and rendering PDFs.
When you view a PDF in Firefox, the PDF viewer is made with this pdfjs package.
The core strength of this package is PDF rendering on a web page. Other PDF modification features are very limited with this package. If you want to make a custom PDF viewer for your site, probably this is the package you are searching for.
pdfjs has a very simple API. They have a lot of tutorials for getting started with the library. If you are not convinced enough, play with this library for some time and you will surely fall in love with it.
pdf-lib
Unlike the previous pdfjs package, pdf-lib is mainly used for PDF creation and manipulation. You can generate a new PDF document dynamically with this package as per your need.
This package has robust support for modifying an existing document. You can do a lot of PDF modifications with this library. For example, you can do PDF splitting and merging, and you can extract a page, annotate a pdf document, add an outline, and many more things you can imagine.
It only has JavaScript as a dependency. So, it can run on any device that has a JavaScript runtime. Browser, Nodejs, Deno, and React Native are well-supported. If you can manage to install JavaScript on a device, then this library will work for sure.
The primary drawback of pdf-lib is that it doesn't have strong rendering support. If you want to make a nice UI for pdf viewing with this library, then pdf-lib is not the right choice for you. In this scenario, you should use pdfjs instead.
pdfjs #2
If you are thinking that I am repeating myself, then I'm not. This is a JavaScript library for creating PDF documents. It has a very simple API to work with.
The previous pdfjs library we have discussed has very strong rendering support in the UI but it lacks PDF creation and modification features.
But this library is built with PDF creation in mind. It has a very simple API and is beginner-friendly. You can compare it with the pdf-lib package.
The primary drawback of this pdfjs library is that the support for modification of existing documents is still in the beta phase. It doesn't work all the time and is still a work in progress.
If your primary focus is PDF modification (for example, page extraction, merging, splitting, annotation, and so on) then this library might not work for you.
If the contributors can make the modification feature work, then this may be the best PDF package for JavaScript.
js-pdf
Unlike all the PDF packages listed above, this library is a complete beast. You can do any PDF-related work with this library. This is like a jack of all trades library. If you want some sophisticated PDF-related stuff, then this library can do it.
But there are better packages in JavaScript that are very good for individual tasks. For example pdfjs is a better PDF renderer than js-pdf, and pdf-lib has better modification support than js-pdf.
Here I am not talking about the actual performance or other types of metrics, I am talking about developer experience. I find that its API is not very intuitive. For a beginner, it can be overwhelming at first sight. This is my opinion, though, and what I experienced when I used it.
PDF generation is the main strength of this library. You can generate any type of PDF with whatever design you have. This package will do all the heavy lifting for you. If you are experienced, then this might be the best bet for you.
react-pdf
As the name suggests, this library is specialized in React ecosystems. The usage is very React-ish. You can easily create a document with its JSX-like syntax.
You can create and display a PDF document with simple React components. But the features are very limited. This library is mainly for PDF generation.
If your goal is to display a PDF to the user, then you can use this package. As a React lover, you will love this library. Check out their playground and spend some time with this package. This way you will know if you need this library or not.
Why We'll Use pdf-lib in This Tutorial
Out of all these PDF libraries mentioned above, I'll use pdf-lib for this article. As we are going to split and merge PDF pages and also render them in the browser, pdf-lib seems to be the best choice for this context.
Also, pdf-lib has a pretty simple API to work with and all these APIs are well documented. If you are using TypeScript, you can also get type inference, which is very helpful.
Last but not least, their examples are very good. You can get up and running in a few minutes. So I like this library for my use cases.
How to Read a Local PDF File in JavaScript
Before doing any operations on our PDF document, we have to get the document from the user. Reading any file in the browser can be handled by FileReader web API.
First, we'll make and file input button and then process the uploaded file using the FileReader web API.
<input type="file" id="file-selector" accept=".pdf" onChange={onFileSelected} />
As the Filereader API works with callbacks, I find async/await a lot cleaner and easier to work with. So let's make a helper function to modify Filereader callbacks into async/await.
function readFileAsync(file) {
return new Promise((resolve, reject) => {
let reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(file);
});
}
Now when a user uploads a file using the previous file input, we listen to the file input event and then read the file using this readFileAsync function.
The implementation of this logic looks like this in code:
const onFileSelected = async (e) => {
const fileList = e.target.files;
if (fileList?.length > 0) {
const pdfArrayBuffer = await readFileAsync(fileList[0]);
}
};
How to Extract PDF Pages
Up to this point, our PDF is uploaded and converted into JavaScript ArrayBuffer. As we are extracting a range of pages from the PDF, we want an array with those page numbers of the PDF.
Generating an array of natural numbers is not hard in JavaScript. So we make a function named range() to generate all the indexes we want.
We have to provide the start page number and end page number and then this range() function can generate an array with appropriate page numbers.
function range(start, end) {
let length = end - start + 1;
return Array.from({ length }, (_, i) => start + i - 1);
}
Here we add -1 at the end. Do you know the reason? Yes – in programming, indexes start from 0, not 1. So we have to deduct -1 from every page number to get the behaviour we want.
Now let's start the main part of this article: the extraction. Before doing any of the work, import the pdf-lib library.
import { PDFDocument } from "pdf-lib";
At first, we load the PDF ArrayBuffer we got from the previous onFileSelected function. Then we load the ArrayBuffer into the PDFDocument.load(arraybuffer) function. This is our user-provided PDF. For convenience, we'll call it pdfSrcDoc.
Now we'll create a new PDF. All the extracted PDF pages from the user-provided document are merged in the new document. We use the PDFDocument.create() function to do that. For ease of use, we call it pdfNewDoc.
After that we copy our desired pages from the pdfSrcDoc into pdfNewDoc by using the copyPages() function. Then we'll add the copied page to pdfNewDoc.
To save the changes, run pdfNewDoc.save(). Let's create a function called extractPdfPage() to reuse the logic. The code inside the function will look like this:
async function extractPdfPage(arrayBuff) {
const pdfSrcDoc = await PDFDocument.load(arrayBuff);
const pdfNewDoc = await PDFDocument.create();
const pages = await pdfNewDoc.copyPages(pdfSrcDoc,range(2,3));
pages.forEach(page=>pdfNewDoc.addPage(page));
const newpdf= await pdfNewDoc.save();
return newpdf;
}
We are returning a Uint8Array from the extractPdfPage() function.
How to Render the PDF in the Browser
As of now, we have a Uint8Array of a modified PDF. To render it inside your browser, we have to convert it into a Blob.
Then we'll make a URL out of it and render it inside an iframe.
You can also make your custom PDF viewer using the pdfjs library as I mentioned above. But if you don't need such branding and customization, the browser's default PDF viewer is fine for this purpose.
function renderPdf(uint8array) {
const tempblob = new Blob([uint8array], {
type: "application/pdf",
});
const docUrl = URL.createObjectURL(tempblob);
setPdfFileData(docUrl);
}
Now you can easily render this docUrl returned from the renderPdf() function inside an iframe.
Complete Code Example
I am using Next.js for this tutorial. If you are using some other framework or vanilla JavaScript, the results will be similar. Here's all the code for this project:
import { useState } from "react";
import { PDFDocument } from "pdf-lib";
export default function Home() {
const [pdfFileData, setPdfFileData] = useState();
function readFileAsync(file) {
return new Promise((resolve, reject) => {
let reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(file);
});
}
function renderPdf(uint8array) {
const tempblob = new Blob([uint8array], {
type: "application/pdf",
});
const docUrl = URL.createObjectURL(tempblob);
setPdfFileData(docUrl);
}
function range(start, end) {
let length = end - start + 1;
return Array.from({ length }, (_, i) => start + i - 1);
}
async function extractPdfPage(arrayBuff) {
const pdfSrcDoc = await PDFDocument.load(arrayBuff);
const pdfNewDoc = await PDFDocument.create();
const pages = await pdfNewDoc.copyPages(pdfSrcDoc, range(2, 3));
pages.forEach((page) => pdfNewDoc.addPage(page));
const newpdf = await pdfNewDoc.save();
return newpdf;
}
// Execute when user select a file
const onFileSelected = async (e) => {
const fileList = e.target.files;
if (fileList?.length > 0) {
const pdfArrayBuffer = await readFileAsync(fileList[0]);
const newPdfDoc = await extractPdfPage(pdfArrayBuffer);
renderPdf(newPdfDoc);
}
};
return (
<>
<h1>Hello world</h1>
<input
type="file"
id="file-selector"
accept=".pdf"
onChange={onFileSelected}
/>
<iframe
style={{ display: "block", width: "100vw", height: "90vh" }}
title="PdfFrame"
src={pdfFileData}
frameborder="0"
type="application/pdf"
></iframe>
</>
);
}
You can now save the resulting PDF using the download button on the PDF viewer.
Where to Go from Here
In this article, I've touched just the tip of the iceberg. If you want to work with PDFs and want to make something out of it, then pdf-lib is a very powerful library for this purpose.
You can merge two PDFs into one, you can rotate pages, or delete some pages from a PDF. These are just some examples – the possibilities are endless.
If you want to deploy your Next.js application to Cloudflare pages, this is the article you should check out.
Make something out of it. Do some creative stuff and show me on Twitter.
Conclusion
If you've read until now, I am very grateful. It feels like I am making content that someone from another part of the world will read. Do share with your coding friends.
Do you want to add an outline to your PDF doc? I know this is a very hard task to achieve. I have gone through a lot of pain to add this feature in a PDF document using JavaScript. Are you interested? That's a story for the future.
Have a good day.