
By Suchandra Datta
I've always been fascinated with languages and the inherent beauty of words. But I used to think that language comprehension was an exclusive human trait.
So when machines started generating, understanding, classifying, and summarizing text using Transformers, I was excited to learn more. And I wanted to learn how to implement and see it in action.
In this article, I'll walk you through the following topics:
- how to fine-tune BERT for NER tasks using HuggingFace
- how to set up Weights and Biases for MLOps
- how to write a model card and share your model on Huggingface Model Hub
I was able to create this model as a side project and share it at https://huggingface.co/Suchandra/bengali_language_NER, thanks to the wonderful resources which I am linking below:
- The Illustrated Transformer
- The Illustrated BERT, ELMo, and co.
- HuggingFace docs
- Model Hub docs
- Weights and Biases docs
Let's go!
A brief overview of Transformers, tokenizers and BERT
Tokenizers
Tokenization is the process of breaking up a larger entity into its constituent units. Large blocks of text are first tokenized so that they are broken down into a format which is easier for machines to represent, learn and understand.
There are different ways we can tokenize text, like:
- character tokenization
- word tokenization
- subword tokenization
For example, consider the text below
The moon shone over laketown
- for character tokenization, we would represent it as a list of component characters like [ 'T', 'h','e','m','o','o','n','s','h','o','n','e','o','v','e','r','l','a','k','e','t','o','w','n' ]
- for word tokenization, it would be [ 'The', 'moon','shone','over','laketown']
- for subword tokenization, frequent words would remain the same, less frequent words are divided up into more frequent words like ['The','moon','shone','over','lake','##town'] here the rarer word "laketown" is divided into words that occur more frequently – "lake" and "town". The two hashes before town is necessary to denote that "town" is not a word by itself but is part of a larger word.
Subword tokenization algorithms most popularly used in Transformers are BPE and WordPiece. Here's a link to the paper for WordPiece and BPE for more information. Great, now our input text looks like this:
['The','moon','shone','over','lake','##town']
Now what? How will it make sense to a machine? Enter transformers.
Transformers and BERT
Transformers are a particular architecture for deep learning models that revolutionized natural language processing.
The defining characteristic for a Transformer is the self-attention mechanism. Using it, each word learns how related it is to the other words in a sequence.
For instance, in the text example of the previous section, the word 'the' refers to the word 'moon' so the attention score for 'the' and 'moon' would be high, while it would be less for word pairs like 'the' and 'over'.
For a full description of the formulae needed to compute the attention score and output, you can read the paper here.
Here's a simplified example of how it all works together. We have our input:
['The','moon','shone','over','lake','##town']
Each token is represented as a vector. So let's say 'the' is represented as [0.1,0.2,1.3,-2.4,0.05] with arbitrary size of 5. The model doesn't know what the values of the vector should be yet so it initializes with some random values.
Then it starts learning the relationships between words using the Transformer architecture and keeps on updating the vector values till it can perform classification with our desired accuracy.
And now, we move on to BERT, which is a model architecture that is based on Transformers. It uses a large text corpus to learn how best to represent tokens and perform downstream-tasks like text classification, token classification, and so on.
The Project's Dataset
NER, or Named Entity Recognition, consists of identifying the labels to which each word of a sentence belongs.
For example, in the sentence "Last week Gandalf visited the Shire", we can consider entities to be "Gandalf" with label "Person" and "Shire" with label "Location".
To build a model that'll perform this task, first of all we need a dataset. We'll be using the WikiANN dataset for the Bengali language, which is easily available via the datasets module of HuggingFace.
It includes multiple languages, where words are annotated with labels like location (LOC), organization (ORG), and person (PER). Here's a link to the Dataset Card for more information.
The model for fine-tuning
We'd be using the BERT base multilingual model, specifically the cased version. I started with the uncased version which later I realized was a mistake.
I soon found that if I encode a word and then decode it, I do get the original word but the spelling of the decoded word has changed.
It turns out that uncased version faces normalization issues that could explain this behavior. Such issues are cleared out in the cased version, as described in the official GitHub repo here.
How to Load the Dataset
First off, let's install all the main modules we need from HuggingFace. Here's how to do it on Jupyter:
!pip install datasets
!pip install tokenizers
!pip install transformers
Then we load the dataset like this:
from datasets import load_dataset
dataset = load_dataset("wikiann", "bn")
And finally inspect the label names:
label_names = dataset["train"].features["ner_tags"].feature.names
How to Preprocess the Dataset
For each sample, we need to get the values for input_ids, token_type_ids and attention_mask as well as adjust the labels.
Why is adjusting labels necessary? Well, BERT models use subword tokenization, where frequent tokens are clubbed together into one token and rare tokens are broken down into frequently occurring tokens.
For example, let's say we have a name "Johnpeter". It would get broken into more frequent words like "John" and "##peter". But "Johnpeter" has only 1 label in the dataset which is "B-PER". So after tokenization, the adjusted labels would be "B-PER" for "John" and again "B-PER" for "##peter".
The code below first encodes all samples for each train, test, validation split. Then it uses word_ids, which is a list with repeated indexes for each word that gets split like word_ids = [0,0,0,1,2,3,3]. This means that the word at index 0 is split into 3 tokens, the word at index 3 is split into 2 tokens. So we repeat the labels in adjusted_label_ids till a change of index occurs.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
#Get the values for input_ids, token_type_ids, attention_mask
def tokenize_adjust_labels(all_samples_per_split):
tokenized_samples = tokenizer.batch_encode_plus(all_samples_per_split["tokens"], is_split_into_words=True)
#tokenized_samples is not a datasets object so this alone won't work with Trainer API, hence map is used
#so the new keys [input_ids, labels (after adjustment)]
#can be added to the datasets dict for each train test validation split
total_adjusted_labels = []
print(len(tokenized_samples["input_ids"]))
for k in range(0, len(tokenized_samples["input_ids"])):
prev_wid = -1
word_ids_list = tokenized_samples.word_ids(batch_index=k)
existing_label_ids = all_samples_per_split["ner_tags"][k]
i = -1
adjusted_label_ids = []
for wid in word_ids_list:
if(wid is None):
adjusted_label_ids.append(-100)
elif(wid!=prev_wid):
i = i + 1
adjusted_label_ids.append(existing_label_ids[i])
prev_wid = wid
else:
label_name = label_names[existing_label_ids[i]]
adjusted_label_ids.append(existing_label_ids[i])
total_adjusted_labels.append(adjusted_label_ids)
tokenized_samples["labels"] = total_adjusted_labels
return tokenized_samples
tokenized_dataset = dataset.map(tokenize_adjust_labels, batched=True)
Here's what it looks like after tokenization for 1 sample:
{'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'input_ids': [101,
978,
12235,
38044,
40349,
52245,
950,
21790,
12079,
89362,
77045,
117,
978,
12235,
38044,
40349,
102],
'labels': [-100, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 0, 5, 5, 5, 5, -100],
'langs': ['bn', 'bn', 'bn', 'bn', 'bn'],
'ner_tags': [5, 6, 6, 0, 5],
'spans': ['LOC: সিডনি ক্রিকেট গ্রাউন্ড', 'LOC: সিডনি'],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['সিডনি', 'ক্রিকেট', 'গ্রাউন্ড', ',', 'সিডনি']}
How to Pad the Samples
Another issue is different samples can get tokenized into different lengths, so we need to add pad tokens so all samples are of the same length.
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer)
How to Set Up Integration for Weights and Biases
Weights and Biases is a super powerful platform that helps streamline tracking model training, dataset versioning, hyperparameter optimizations and visualizations. It has integrations for HuggingFace, Keras, and PyTorch.
It's easier to keep track of all the parameters for each experiment, how losses are varying for each run, and so on, which makes debugging faster.
Check out their website linked here for a full list of features offered, usage plans, and how to get started.
!pip install wandb
import os
import wandb
os.environ["WANDB_API_KEY"]="API KEY GOES HERE"
os.environ["WANDB_ENTITY"]="Suchandra"
os.environ["WANDB_PROJECT"]="finetune_bert_ner"
The advantage of Weights and Biases is the automatic logging and graphs using which we get to compare model performance across multiple runs and figure out for which values it is working well. Like here:
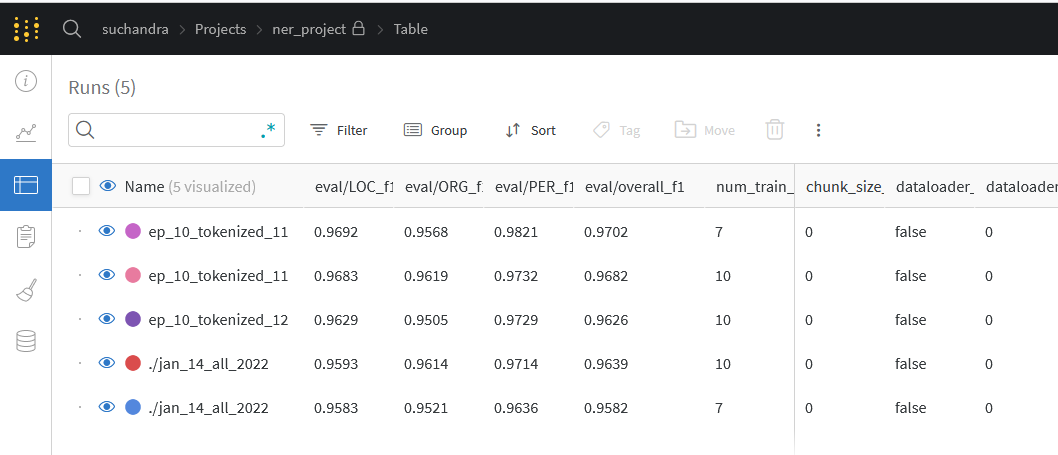
I can see at one glance how the F1 score and loss is varying for different epoch values:
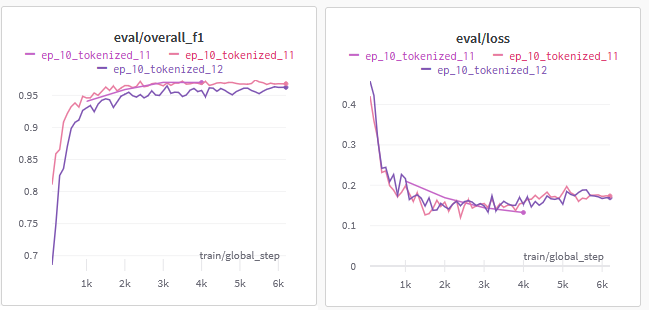
How to Train the Model using Trainer API
HuggingFace Trainer API is very intuitive and provides a generic train loop, something we don't have in PyTorch at the moment.
To get metrics on the validation set during training, we need to define the function that'll calculate the metric for us. This is very well-documented in their official docs.
from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
import numpy as np
from datasets import load_metric
metric = load_metric("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_names[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
flattened_results = {
"overall_precision": results["overall_precision"],
"overall_recall": results["overall_recall"],
"overall_f1": results["overall_f1"],
"overall_accuracy": results["overall_accuracy"],
}
for k in results.keys():
if(k not in flattened_results.keys()):
flattened_results[k+"_f1"]=results[k]["f1"]
return flattened_results
I wanted to see the entity level metrics too, so I added this snippet:
flattened_results = {"overall_precision": results["overall_precision"],"overall_recall": results["overall_recall"],"overall_f1": results["overall_f1"],"overall_accuracy": results["overall_accuracy"],}
for k in results.keys():
if(k not in flattened_results.keys()):
flattened_results[k+"_f1"]=results[k]["f1"]
Next, we load the model checkpoint to fine-tune on and pass in all the arguments to Trainer and train.
model = AutoModelForTokenClassification.from_pretrained("bert-base-multilingual-cased", num_labels=len(label_names))
training_args = TrainingArguments(
output_dir="./fine_tune_bert_output",
evaluation_strategy="steps",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=7,
weight_decay=0.01,
logging_steps = 1000,
report_to="wandb",
run_name = "ep_10_tokenized_11",
save_strategy='no'
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
wandb.finish()
I was training this on Google Colab and hit the Colab usage limits. I am not sure why this happened, since I didn't train for 12 hours or anything like that.
From Colab's official FAQ here, it outlines this issue and possible causes for it. I finished the train by switching to Kaggle.
Here's some of the train, validation, and test set results:
 Train and validation results
Train and validation results
 Test results
Test results
How to Save the Model to HuggingFace Model Hub
I found cloning the repo, adding files, and committing using Git the easiest way to save the model to hub.
!transformers-cli login
!git config --global user.email "youremail"
!git config --global user.name "yourname"
!sudo apt-get install git-lfs
%cd your_model_output_dir
!git add .
!git commit -m "Adding the files"
!git push
How to Create a Model Card
Now let's add useful information about our model by creating a model card on HuggingFace. It serves as the README.md for the repository.
Whilst most of it is very straightforward, here's some things that took me a while to figure out:
- how to change the default language of the Inference API. My NER model is fine-tuned on the Bengali language but the example inputs were in English. To change that, I had to give the language info in the metadata of the model card, which is written in YAML. You can refer to the Model Repo docs here
- customize the input examples like this: ```examples: widget:
- text: "মারভিন দি মারসিয়ান" ```
- you can also give a name to each example like this: ```
- text: "সাউথ ইস্ট ইউনিভার্সিটি" example_title: "Sentence_4" ```
Here's all the metadata I added to my model card
---
language: bn
datasets:
- wikiann
examples:
widget:
- text: "মারভিন দি মারসিয়ান"
example_title: "Sentence_1"
- text: "লিওনার্দো দা ভিঞ্চি"
example_title: "Sentence_2"
- text: "বসনিয়া ও হার্জেগোভিনা"
example_title: "Sentence_3"
- text: "সাউথ ইস্ট ইউনিভার্সিটি"
example_title: "Sentence_4"
- text: "মানিক বন্দ্যোপাধ্যায় লেখক"
example_title: "Sentence_5"
---
And here's what my model card looks like

Let's summarize
In this article, we covered how to fine-tune a model for NER tasks using the powerful HuggingFace library.
We also saw how to integrate with Weights and Biases, how to share our finished model on HuggingFace model hub, and write a beautiful model card documenting our work.
That's a wrap on my side for this article. Keep learning coders, keep upskilling, and always remain curious. Take care and happy coding!