
By Tim Grossmann
When people who speak different languages get together and talk, they try to use a language that everyone in the group understands.
To achieve this, everyone has to translate their thoughts, which are usually in their native language, into the language of the group. This “encoding and decoding” of language, however, leads to a loss of efficiency, speed, and precision.
The same concept is present in computer systems and their components. Why should we send data in XML, JSON, or any other human-readable format if there is no need for us to understand what they are talking about directly? As long as we can still translate it into a human-readable format if explicitly needed.
Protocol Buffers are a way to encode data before transportation, which efficiently shrinks data blocks and therefore increases speed when sending it. It abstracts data into a language- and platform-neutral format.
Table of Contents
- Why do we need Protocol Buffers?
- What are Protocol Buffers and how do they work?
- Protocol Buffers in Python
- Final notes
Why Protocol Buffers?
The initial purpose of Protocol Buffers was to simplify the work with request/response protocols. Before ProtoBuf, Google used a different format which required additional handling of marshaling for the messages sent.
In addition to that, new versions of the previous format required the developers to make sure that new versions are understood before replacing old ones, making it a hassle to work with.
This overhead motivated Google to design an interface that solves precisely those problems.
ProtoBuf allows changes to the protocol to be introduced without breaking compatibility. Also, servers can pass around the data and execute read operations on the data without modifying its content.
Since the format is somewhat self-describing, ProtoBuf is used as a base for automatic code generation for Serializers and Deserializers.
Another interesting use case is how Google uses it for short-lived Remote Procedure Calls (RPC) and to persistently store data in Bigtable. Due to their specific use case, they integrated RPC interfaces into ProtoBuf. This allows for quick and straightforward code stub generation that can be used as starting points for the actual implementation. (More on ProtoBuf RPC.)
Other examples of where ProtoBuf can be useful are for IoT devices that are connected through mobile networks in which the amount of sent data has to be kept small or for applications in countries where high bandwidths are still rare. Sending payloads in optimized, binary formats can lead to noticeable differences in operation cost and speed.
Using gzip compression in your HTTPS communication can further improve those metrics.
What are Protocol buffers and how do they work?
Generally speaking, Protocol Buffers are a defined interface for the serialization of structured data. It defines a normalized way to communicate, utterly independent of languages and platforms.
Google advertises its ProtoBuf like this:
Protocol buffers are Google's language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once …
The ProtoBuf interface describes the structure of the data to be sent. Payload structures are defined as “messages” in what is called Proto-Files. Those files always end with a .proto extension.
For example, the basic structure of a todolist.proto file looks like this. We will also look at a complete example in the next section.
syntax = "proto3";
// Not necessary for Python, should still be declared to avoid name collisions
// in the Protocol Buffers namespace and non-Python languages
package protoblog;
message TodoList {
// Elements of the todo list will be defined here
...
}
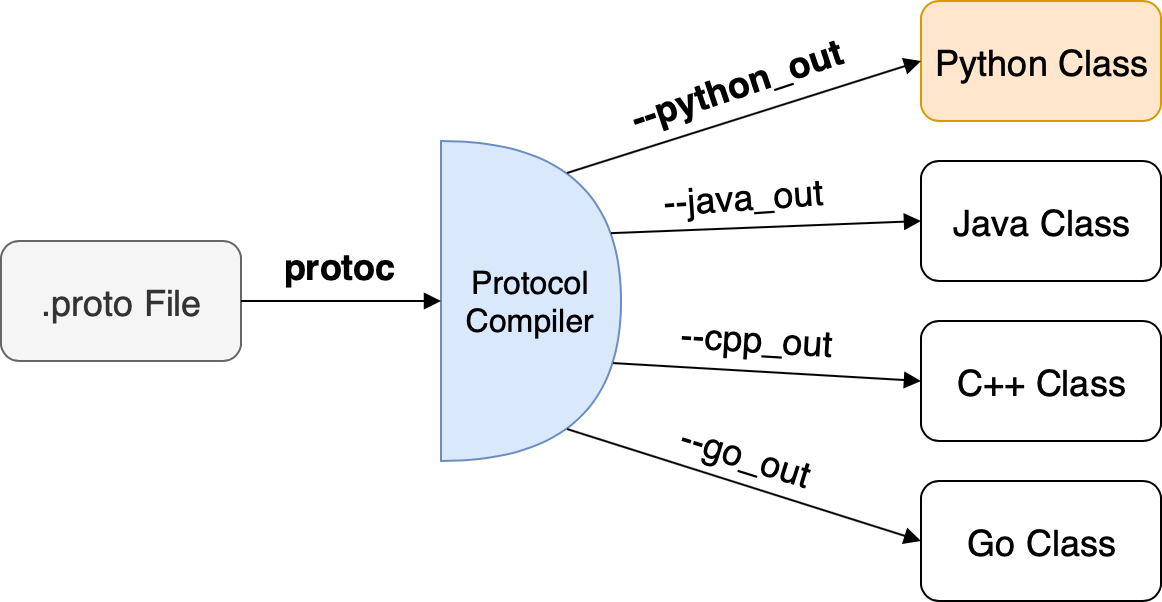
Those files are then used to generate integration classes or stubs for the language of your choice using code generators within the protoc compiler. The current version, Proto3, already supports all the major programming languages. The community supports many more in third-party open-source implementations.
Generated classes are the core elements of Protocol Buffers. They allow the creation of elements by instantiating new messages, based on the .proto files, which are then used for serialization. We’ll look at how this is done with Python in detail in the next section.
Independent of the language for serialization, the messages are serialized into a non-self-describing, binary format that is pretty useless without the initial structure definition.
The binary data can then be stored, sent over the network, and used any other way human-readable data like JSON or XML is. After transmission or storage, the byte-stream can be deserialized and restored using any language-specific, compiled protobuf class we generate from the .proto file.
Using Python as an example, the process could look something like this:
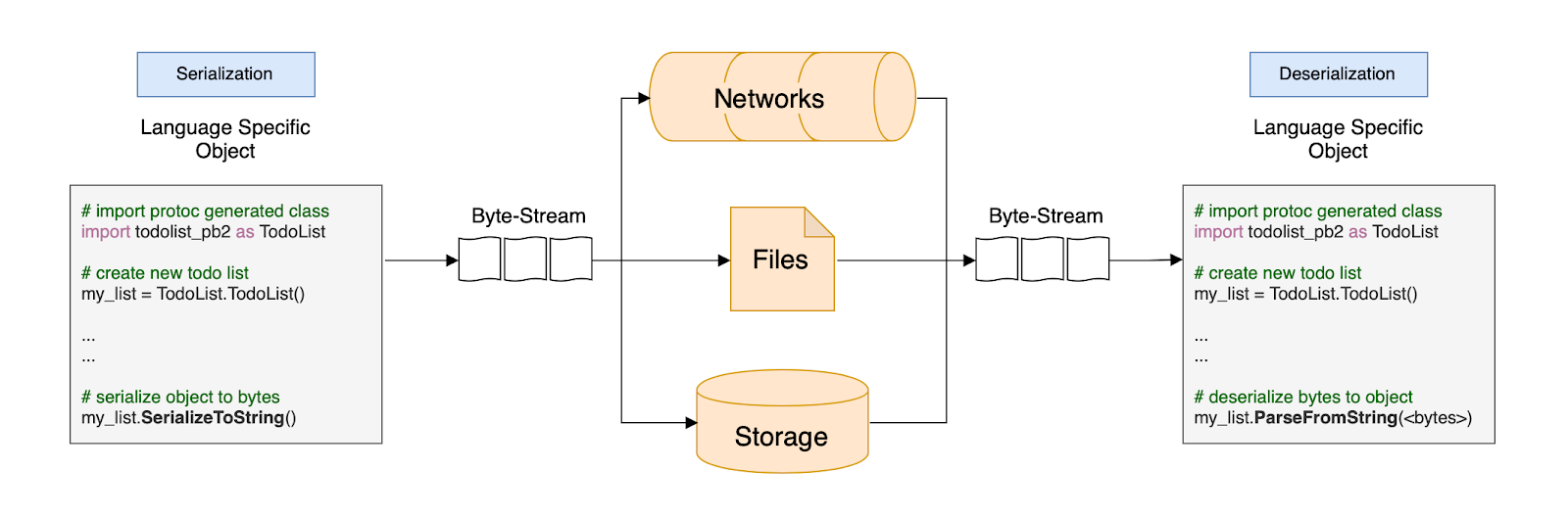
First, we create a new todo list and fill it with some tasks. This todo list is then serialized and sent over the network, saved in a file, or persistently stored in a database.
The sent byte stream is deserialized using the parse method of our language-specific, compiled class.
Most current architectures and infrastructures, especially microservices, are based on REST, WebSockets, or GraphQL communication. However, when speed and efficiency are essential, low-level RPCs can make a huge difference.
Instead of high overhead protocols, we can use a fast and compact way to move data between the different entities into our service without wasting many resources.
But why isn’t it used everywhere yet?
Protocol Buffers are a bit more complicated than other, human-readable formats. This makes them comparably harder to debug and integrate into your applications.
Iteration times in engineering also tend to increase since updates in the data require updating the proto files before usage.
Careful considerations have to be made since ProtoBuf might be an over-engineered solution in many cases.
What alternatives do I have?
Several projects take a similar approach to Google’s Protocol Buffers.
Google’s Flatbuffers and a third party implementation, called Cap’n Proto, are more focused on removing the parsing and unpacking step, which is necessary to access the actual data when using ProtoBufs. They have been designed explicitly for performance-critical applications, making them even faster and more memory efficient than ProtoBuf.
When focusing on the RPC capabilities of ProtoBuf (used with gRPC), there are projects from other large companies like Facebook (Apache Thrift) or Microsoft (Bond protocols) that can offer alternatives.
Python and Protocol Buffers
Python already provides some ways of data persistence using pickling. Pickling is useful in Python-only applications. It's not well suited for more complex scenarios where data sharing with other languages or changing schemas is involved.
Protocol Buffers, in contrast, are developed for exactly those scenarios.
The .proto files, we’ve quickly covered before, allow the user to generate code for many supported languages.
To compile the .proto file to the language class of our choice, we use protoc, the proto compiler.
If you don’t have the protoc compiler installed, there are excellent guides on how to do that:
Once we’ve installed protoc on our system, we can use an extended example of our todo list structure from before and generate the Python integration class from it.
syntax = "proto3";
// Not necessary for Python but should still be declared to avoid name collisions
// in the Protocol Buffers namespace and non-Python languages
package protoblog;
// Style guide prefers prefixing enum values instead of surrounding
// with an enclosing message
enum TaskState {
TASK_OPEN = 0;
TASK_IN_PROGRESS = 1;
TASK_POST_PONED = 2;
TASK_CLOSED = 3;
TASK_DONE = 4;
}
message TodoList {
int32 owner_id = 1;
string owner_name = 2;
message ListItems {
TaskState state = 1;
string task = 2;
string due_date = 3;
}
repeated ListItems todos = 3;
}
Let’s take a more detailed look at the structure of the .proto file to understand it.
In the first line of the proto file, we define whether we’re using Proto2 or 3. In this case, we’re using Proto3.
The most uncommon elements of proto files are the numbers assigned to each entity of a message. Those dedicated numbers make each attribute unique and are used to identify the assigned fields in the binary encoded output.
One important concept to grasp is that only values 1-15 are encoded with one less byte (Hex), which is useful to understand so we can assign higher numbers to the less frequently used entities. The numbers define neither the order of encoding nor the position of the given attribute in the encoded message.
The package definition helps prevent name clashes. In Python, packages are defined by their directory. Therefore providing a package attribute doesn’t have any effect on the generated Python code.
Please note that this should still be declared to avoid protocol buffer related name collisions and for other languages like Java.
Enumerations are simple listings of possible values for a given variable.
In this case, we define an Enum for the possible states of each task on the todo list.
We’ll see how to use them in a bit when we look at the usage in Python.
As we can see in the example, we can also nest messages inside messages.
If we, for example, want to have a list of todos associated with a given todo list, we can use the repeated keyword, which is comparable to dynamically sized arrays.
To generate usable integration code, we use the proto compiler which compiles a given .proto file into language-specific integration classes. In our case we use the --python-out argument to generate Python-specific code.
protoc -I=. --python_out=. ./todolist.proto
In the terminal, we invoke the protocol compiler with three parameters:
- -I: defines the directory where we search for any dependencies (we use . which is the current directory)
- --python_out: defines the location we want to generate a Python integration class in (again we use . which is the current directory)
- The last unnamed parameter defines the .proto file that will be compiled (we use the todolist.proto file in the current directory)
This creates a new Python file called _pb2.py. In our case, it is todolist_pb2.py. When taking a closer look at this file, we won’t be able to understand much about its structure immediately.
This is because the generator doesn’t produce direct data access elements, but further abstracts away the complexity using metaclasses and descriptors for each attribute. They describe how a class behaves instead of each instance of that class.
The more exciting part is how to use this generated code to create, build, and serialize data. A straightforward integration done with our recently generated class is seen in the following:
import todolist_pb2 as TodoList
my_list = TodoList.TodoList()
my_list.owner_id = 1234
my_list.owner_name = "Tim"
first_item = my_list.todos.add()
first_item.state = TodoList.TaskState.Value("TASK_DONE")
first_item.task = "Test ProtoBuf for Python"
first_item.due_date = "31.10.2019"
print(my_list)
It merely creates a new todo list and adds one item to it. We then print the todo list element itself and can see the non-binary, non-serialized version of the data we just defined in our script.
owner_id: 1234
owner_name: "Tim"
todos {
state: TASK_DONE
task: "Test ProtoBuf for Python"
due_date: "31.10.2019"
}
Each Protocol Buffer class has methods for reading and writing messages using a Protocol Buffer-specific encoding, that encodes messages into binary format.
Those two methods are SerializeToString() and ParseFromString().
import todolist_pb2 as TodoList
my_list = TodoList.TodoList()
my_list.owner_id = 1234
# ...
with open("./serializedFile", "wb") as fd:
fd.write(my_list.SerializeToString())
my_list = TodoList.TodoList()
with open("./serializedFile", "rb") as fd:
my_list.ParseFromString(fd.read())
print(my_list)
In the code example above, we write the Serialized string of bytes into a file using the wb flags.
Since we have already written the file, we can read back the content and Parse it using ParseFromString. ParseFromString calls on a new instance of our Serialized class using the rb flags and parses it.
If we serialize this message and print it in the console, we get the byte representation which looks like this.
b'\x08\xd2\t\x12\x03Tim\x1a(\x08\x04\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'
Note the b in front of the quotes. This indicates that the following string is composed of byte octets in Python.
If we directly compare this to, e.g., XML, we can see the impact ProtoBuf serialization has on the size.
<todolist>
<owner_id>1234</owner_id>
<owner_name>Tim</owner_name>
<todos>
<todo>
<state>TASK_DONE</state>
<task>Test ProtoBuf for Python</task>
<due_date>31.10.2019</due_date>
</todo>
</todos>
</todolist>
The JSON representation, non-uglified, would look like this.
{
"todoList": {
"ownerId": "1234",
"ownerName": "Tim",
"todos": [
{
"state": "TASK_DONE",
"task": "Test ProtoBuf for Python",
"dueDate": "31.10.2019"
}
]
}
}
Judging the different formats only by the total number of bytes used, ignoring the memory needed for the overhead of formatting it, we can of course see the difference.
But in addition to the memory used for the data, we also have 12 extra bytes in ProtoBuf for formatting serialized data. Comparing that to XML, we have 171 extra bytes in XML for formatting serialized data.
Without Schema, we need 136 extra bytes in JSON for formatting serialized data.
If we’re talking about several thousands of messages sent over the network or stored on disk, ProtoBuf can make a difference.
However, there is a catch. The platform Auth0.com created an extensive comparison between ProtoBuf and JSON. It shows that, when compressed, the size difference between the two can be marginal (only around 9%).
If you’re interested in the exact numbers, please refer to the full article, which gives a detailed analysis of several factors like size and speed.
An interesting side note is that each data type has a default value. If attributes are not assigned or changed, they will maintain the default values. In our case, if we don’t change the TaskState of a ListItem, it has the state of “TASK_OPEN” by default. The significant advantage of this is that non-set values are not serialized, saving additional space.
If we, for example, change the state of our task from TASK_DONE to TASK_OPEN, it will not be serialized.
owner_id: 1234
owner_name: "Tim"
todos {
task: "Test ProtoBuf for Python"
due_date: "31.10.2019"
}
b'\x08\xd2\t\x12\x03Tim\x1a&\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'
Final Notes
As we have seen, Protocol Buffers are quite handy when it comes to speed and efficiency when working with data. Due to its powerful nature, it can take some time to get used to the ProtoBuf system, even though the syntax for defining new messages is straightforward.
As a last note, I want to point out that there were/are discussions going on about whether Protocol Buffers are “useful” for regular applications. They were developed explicitly for problems Google had in mind.
If you have any questions or feedback, feel free to reach out to me on any social media like twitter or email :)