
By Aagam Vadecha
REST and GraphQL are both standard ways to develop backend APIs. But over the past decade REST APIs have dominated as a choice for developing backend API's. And many companies and developers use it actively in their projects.
But REST has some limitations, and there's another alternative available – GraphQL. GraphQL is a great choice for developing APIs in large codebases.
What is GraphQL?
GraphQL was developed by Facebook in 2012 for internal usage and made public in 2015. It is a query language for APIs and a runtime for fulfilling those queries with your existing data. Many companies use it in production.
The official website introduces GraphQL like this:
GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
And we'll see how all this works in this blog.
Issues With REST APIs
- Querying Multiple Endpoints
- OverFetching
- UnderFetching and n+1 Request Problem
- Not super fast to cope up with changing client end requirements
- High Coupling between Backend Controllers and Frontend Views
So, what are these issues and how does GraphQL solve them? Well, we'll learn more going forward. But first we'll need to make sure you're comfortable with the basic concepts of GraphQL like the type system, schema, queries, mutations, and so on.
Now we'll look at some examples to better understand the disadvantages of using REST APIs.
Overfetching
Let's assume that we need to show this User Card in the UI.
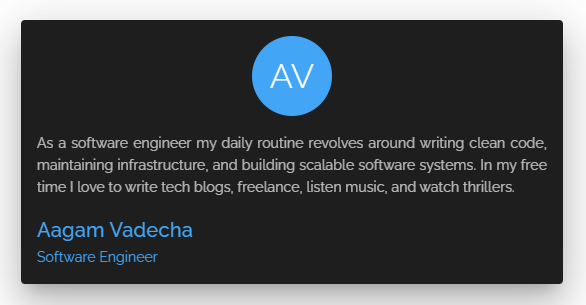
With REST, the request is going to be a GET at /users/1.
The problem here is that the server returns a fixed data-structure, something like this:
{
"_id": "1",
"name": "Aagam Vadecha",
"username": "aagam",
"email": "testemail@gmail.com",
"currentJobTitle": "Software Engineer",
"phone": "9876543210",
"intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.",
"website": "https://www.aagam.tech",
"gender": "MALE",
"city": "Surat",
"state": "Gujarat",
"country": "India",
"display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952",
"phone_verified": true,
"email_verified": true,
"_created_at": "2021-03-08T14:13:41Z",
"_updated_at": "2021-03-08T14:13:41Z",
"_deleted": false
}
The server returns extra data (aside from the Name, Intro, and Job Designation) which is not required at the client-end to build the card at this point – but the response still has it. This is called overfetching.
Overfetching brings extra data in each request which is not required by the client. And this increases the payload size and eventually that has an effect on the overall response time of the query.
What's worse, the situation escalates when a query is bringing data from multiple tables even though the client doesn't require it right then. So if we can avoid it, we definitely should
With GraphQL, the query inside the request body would look something like this:

It will only return the name, intro, and currentJobTitle as required by the client, so the overfetching problem is solved.
Underfetching and the n+1 request problem
Now let's assume this UserList needs to be shown in the UI.

With REST, considering "experience" is a table which has a foreign key of user_id, there are three possible options
- One is to send some exact fixed data-structure from all foreign-key linked tables to the users table in the GET /users request, and many frameworks provide this option.
{
"_id": "1",
"name": "Aagam Vadecha",
"username": "aagam",
"email": "testemail@gmail.com",
"currentJobTitle": "Software Engineer",
"phone": "9876543210",
"intro": "As a software engineer my daily routine revolves around writing cleancode, maintaining infrastructure, and building scalable softwaresystems. In my free time I love to write tech blogs, freelance, listenmusic, and watch thrillers.",
"website": "https://www.aagam.tech",
"gender": "MALE",
"city": "Surat",
"state": "Gujarat",
"country": "India",
"display_picture": "8ba58af0-1212-4938-8b4a-t3m9c4371952",
"phone_verified": true,
"email_verified": true,
"_created_at": "2021-03-08T14:13:41Z",
"_updated_at": "2021-03-08T14:13:41Z",
"_deleted": false,
"experience": [
{
"organizationName": "Bharat Tech Labs",
"jobTitle": "Software Engineer",
"totalDuration": "1 Year"
}
],
"address": [
{
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "929983874",
"geo": {
"lat": "-37,3159",
"lng": "81.1496"
}
}
]
}
But this method makes expensive queries, overfetches all other /users requests as well, and ends up bringing back a lot of data from all foreign tables (address, experience) which is not required in most cases.
For example, you want user data somewhere else in the frontend where you just need to show user's website so you make a GET user/1 request. But it overfetches data from the experience table as well as the address table, which you don't need at all.
- The second option is that the client can make multiple trips to the server like this:
GET /users
GET users/1/experience
This is an example of underfetching, as one endpoint doesn't have enough data. But multiple network calls slows down the process and affects the user experience. :(
Also, in this specific case of a List, underfetching escalates and we run into the n+1 request problem.
You need to make an API call to get all users and then individual API calls for each user to get their experience, something like this:
GET /users
GET /users/1/experience
GET /users/2/experience
...
GET /users/n/experience.
This is known as the n+1 request problem. To solve this issue, what we generally do is the third option, which we'll discuss now.
- Another option is to make a custom controller on the server which returns the data-structure that meets the client requirements at that point in time.
This is what is done in major real world REST API cases.GET /user-experience
On the other hand, a simple GraphQL request which would seamlessly work without any development required on the server end, would look something like this:

No overfetching, no underfetching, and no development on the server. Simply fantastic!
Tight coupling between front end views and back end APIs
Okay, so you might argue that you can just use REST, make the server controller with a one time initial development effort, and be happy – right?
But there's a major drawback which comes along with using custom controllers.
We have formed a tight coupling with the front-end view and the back-end controller, so overall it needs more effort to cope with changes on the client end. It also gives us less flexibility.
As Software Engineers, we know how often requirements change. The custom controller at this point GET /user-experience is returning data depending on what the front-end view wants to display (user-name and current-role). So when a requirement changes, we need to refactor both the client and server.
For example, after a considerable amount of time, requirements change and instead of the experience data the UI needs to show a user's last transaction info.
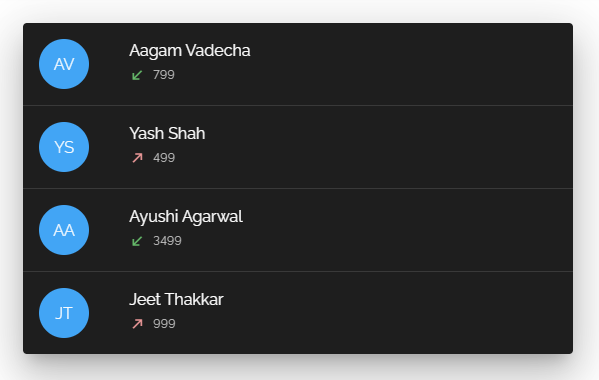
With Rest, we would need to make the relevant changes in the front end layer. Additionally, in order to return transaction data instead of experience data from the back end, the custom controller will either need to be refactored (data sent, route, etc) or we'll need to make a new controller in case we want to preserve the old one.
So basically, a change in client requirements greatly influences what is to be returned by the server – which means we have tight coupling between the front end and the back end!
It would be better not to have to make any changes on the server but only the front end.
With GraphQL we won't need to make any changes in the server side. The change in the front end query would be as minimal as this:

No server API refactoring, deployment, testing – this means time and effort saved!
Conclusion
As I hope you can see from this article, GraphQL has a number of advantages over REST in many areas.
It might take more time to set up GraphQL initially, but there are many scaffolders which make that job easier. And even if it takes more time in the beginning, it gives you long term advantages and is totally worth it.
Thanks for reading!
I hope you liked this article, and that it gave you more insights to help you make your next choice. If you need some help, feel free to reach out to me on LinkedIn.