
By Sajal Sharma
You wake up one morning to have your cup of coffee and voilà, the Eureka moment is here. You finally figured out your business model, and it all falls into place. You know investors will love it, and you just can't wait to start building the product. The first mover advantage is yours to take.
These moments are rare, but when they happen you need to jumpstart at the right time. All you need is the right guide to help you figure out what you should and shouldn't do. This isn't a time to experiment, it's the time to execute. It's YOUR time now!
NOTE - The following is related to building software architectures from scratch. So if you are interested in knowing the nitty-gritty of the technologies involved, then proceed. Otherwise, please share with those who will definitely love this :P
Where this guide came from
I have myself worked on a handful of early stage products, and to be honest, I did make mistakes. I always wished there was a checklist to follow while building a product from the ground up.
There are so many things involved in building an architecture from scratch that you will totally forget certain pieces. And they will come back to bite you in later stages of the product cycle.
I finally decided to create this checklist of things that you should consider before hitting that deploy button for the first time.
So without further build-up, here's the checklist you should go through while building a Backend Architecture for a product from scratch.
Choose the CORRECT language and framework (for your project)
Choosing the correct language and framework for your product is tricky, and there's no particular silver bullet for this. My advice is to choose a language you are most comfortable with and know the intricacies of in and out.
Having said this, it's rare, because there are very few people who are Javascript Ninjas, or Python Panthers, or whatever funky names are out there.
So choose a language that has some real good support in the industry, like Javascript, Python, Java, or Go to name a few. You can choose any language, just pick which one is most comfortable for you.
And remember – you are building an MVP (Minimum Viable Product), and will be in the process of creating a POC (Proof of Concept). So get your product out as soon as possible. You don't need to get stuck on issues that might come from the new language in town. To avoid those issues, choose a more widely used, well-documented language.
Lastly, you can scale at a later time. If you are in the phase of doing POCs, just build and get it done. But if you are building something really specific, and there's a language and a framework build especially for that, then you should definitely chose that tech.
But most of the time, the problems we are trying to solve can be easily taken care of with any of the above mentioned languages and their respective frameworks. So just choose one and kickstart your product.
A good resource to help you decide -
Implement authentication and authorisation microservices
There are a lot of ways to authenticate and authorise a user. You could try Session Tokens, JWT (JSON Web Tokens), or OAuth, to name a few. Every option has it's own pros and cons. So let's look at some of them more closely.
JSON Web Tokens
JWTs are fast and easy to implement. This is because the tokens are never stored anywhere on your system. They are just encoded, encrypted, and sent to the user. So validating a JWT is faster than any other method.
But then, since they are not stored on the system, you can't actually make a token expire before its actual expiration time, and this can be an issue in certain cases.
So figure out the pros and cons of each authentication system and choose the one that best suits your requirements. I personally prefer JWTs (but that's my own choice).
Authorization
Never forget to implement authorisation of users. You don't want logged in User1 to change the details of User2. This can cause pure chaos in your system.
Identify the endpoints that need authorisation, and implement them right away. You don't want the state of your database to be corrupted like this. Remember the difference between 401 and 403.
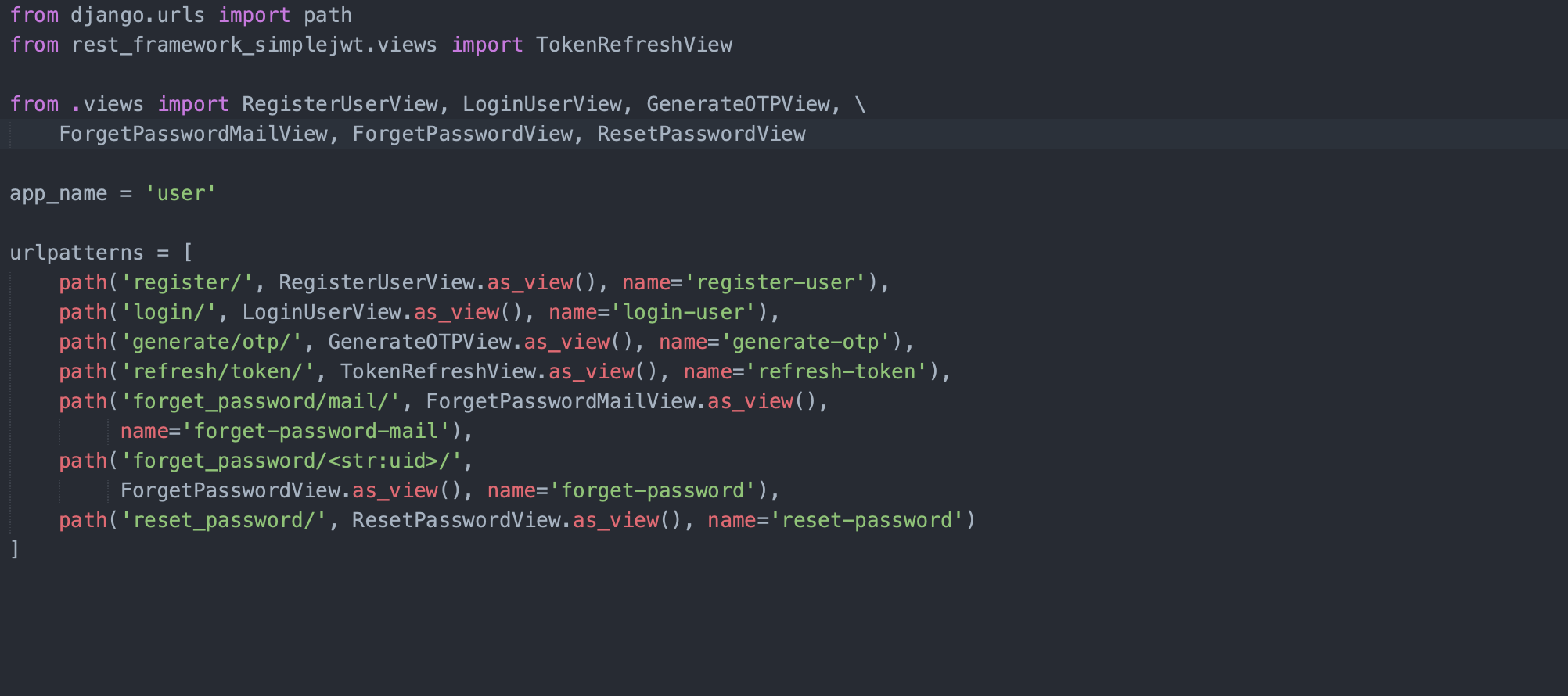
The following are certain end points you should definitely consider while creating your Authentication system (I created one in Django using JWT). There can be certain additions/deletions for your use case, but these are the ones you should consider building.
A lot of frameworks provide them out of the box, but do consider them before building them on your own. Check _authenticationclasses and _permissionclasses in the Django Rest Framework for further reference.
Have a look at this Django REST Framework resource -
https://www.django-rest-framework.org/tutorial/4-authentication-and-permissions/
Create an abstract base model to be inherited by every other model in your database
Remember the DRY Principle - Don't Repeat Yourself? It should be followed to the core in Software Engineering.
Building on the above thought process, there will be certain columns in your database which will be present in every table. Therefore it's better to create an abstract class for them so that other Model Classes can inherit from them.
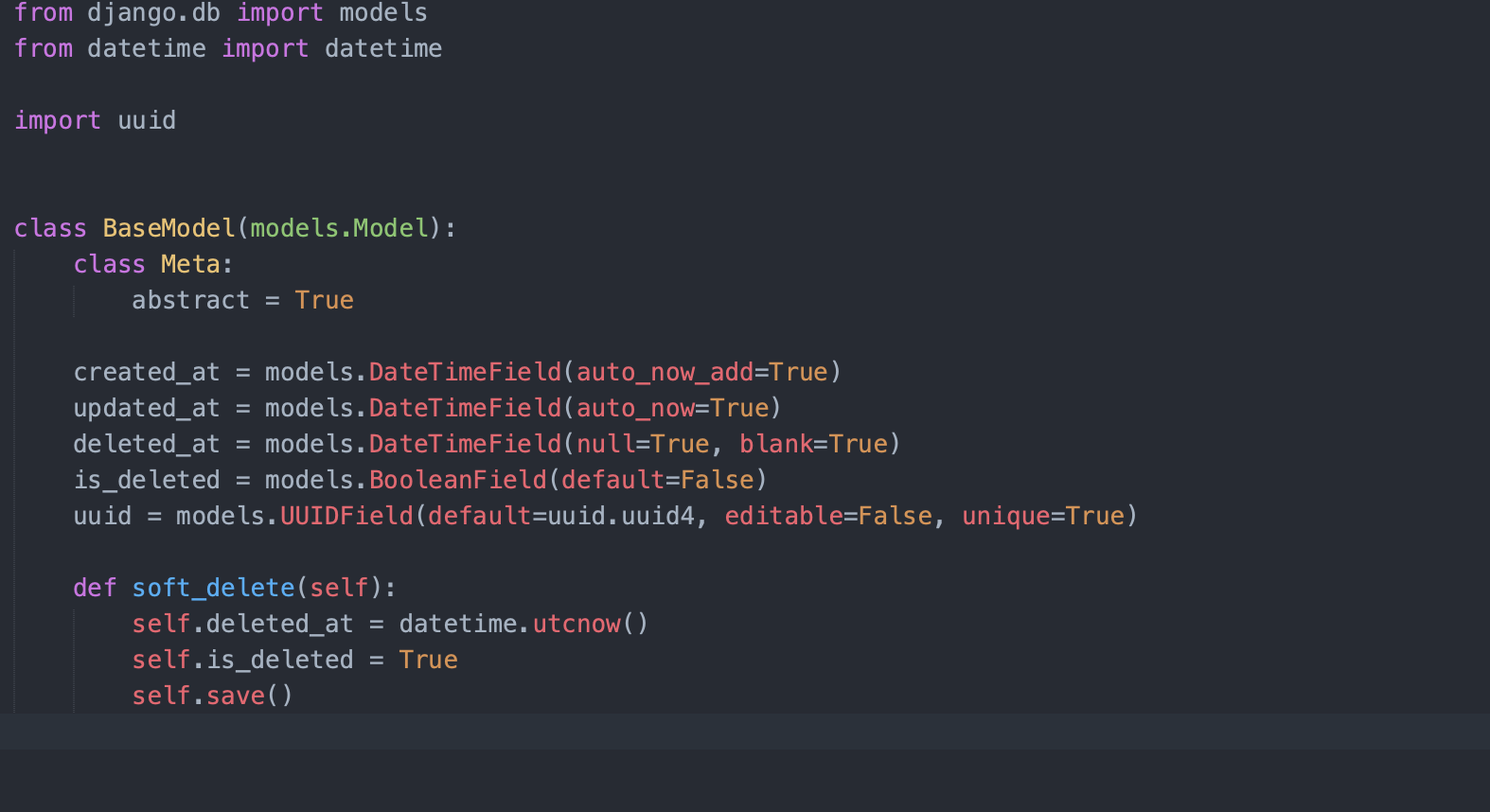
Let's go through this code and what it means:
- id - Though it is not written here, it is automatically created by the Django framework. But if it is not there in yours, write it down in this class. It's just an auto incremented field which can be used as a Primary Key in your database relation.
- _createdat - This implies when the field/row was inserted into your table, and it's filled by the framework itself. You don't need to set it explicitly.
- _updatedat - This implies when the field/row was last modified/updated in your table, and again it's filled by the framework itself.
- _deleted_at + isdeleted - So this is a controversial field. I don't have an exact answer as to whether it should be there or not – because to be honest, nothing on the internet is ever deleted. This field, if filled, depicts that the row is deleted from the system (though the data remains in the system for future references and can be taken off from the database and stored in backups)
- uuid - It depends whether you want to put this in your table or not. If you need to expose the Primary key of your table to an outside system, it's better to expose this one rather than the auto incremented integer field. You might wonder why...? Well, why would you want to tell an outside system that you have 10378 orders in your table? But again it's a personal choice.
Set up a notification microservice
Every product needs to send Reminders and Notifications to the user for engagement and transactional purposes. So every product will need this.
You should definitely consider building a Microservice that provides Notification services (like Push Notification, Emails, and SMS) to your end users.
This should be a separate Microservice altogether. Don't build this inside your Authentication Microservice or your Application Service (the actual Business Logic).
There are a lot of third party libraries/services that can be used to build it for your application. Leverage them and build it on top of that.
Remember to build all the 3 functionalities:
- Push Notifications (APNS + FCM),
- Emails (just integrate an SMTP client for starting)
- and SMS
NOTE - Have two channels for sending SMS, transactional and promotional. Never send a promotional SMS on a transactional channel, as there are chances that you will be sued by a well informed and motivated user.
An easy way to configure your SMTP client in your application is using this in your settings:
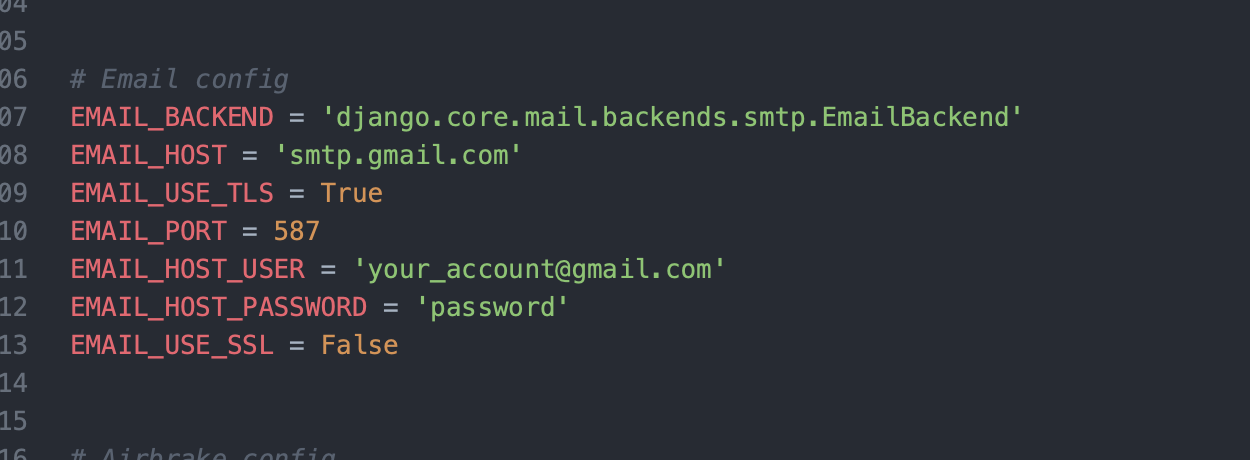
I did this in Django, but you can do the same in your chosen language and framework.
Set up error logging
Use a middleware to log errors that occur on your production system. Your production system will not be monitored by humans sitting there to see the application logs 24/7. So you will need a system that will log those Internal Server Errors in a central place. Then you can go and check them on a daily basis or create a webhook so that you can be alerted at the right time and take care of them.
There are a lot of 3rd party error logging tools in the market. Just choose any one that suits your requirements. I mostly use Sentry/Airbrake.
Consider configuring webhooks, as I mentioned above. They will inform your users about errors and, for example, you can post those errors as and when they occur on certain slack channels. Then you can check those channels on a regular basis and rectify them on the basis of their severity.
Airbrake's official home page - https://airbrake.io/
Sentry's official home page - https://sentry.io/welcome/
Implement request - response and application logging
Scenario - A user comes on your support and says that they haven't received the Transactional Receipt for the purchase they made on your website. What will you do?
If you have put Application Logging in your system, then worry not. Now what do I mean by that? It's always better to show an example than trying to explain with words. So here it is:
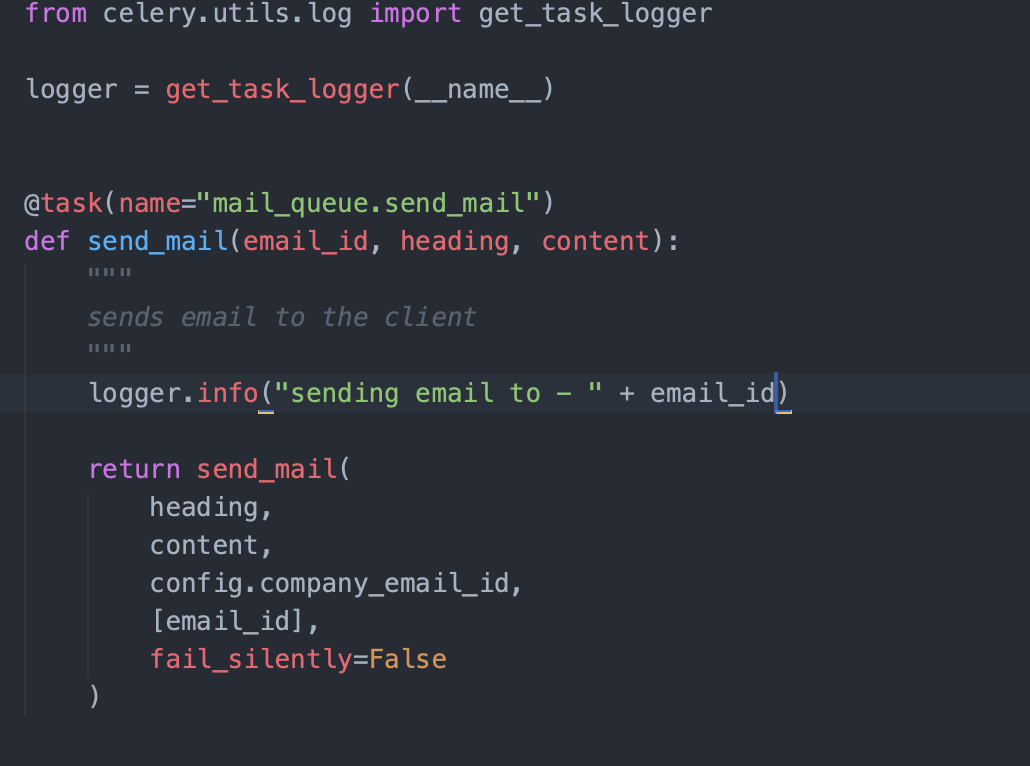
I have logged that I am about to send the email to the mentioned email_id. I can check in the application logs to see if the email was actually sent to the client by checking if such a log exists in the system. Make sure to put comprehensive logs in your system so that you can trace the request's journey.
Additionally, it's a good idea to put an async system in place that will pick out such request-response and application logs from your system and dump them in a central place. There they can be processed to be more easily interpretable.
The ELK stack is a good option for this: ElasticSearch - Logstash - Kibana.
More about the ELK stack - https://www.elastic.co/what-is/elk-stack
NOTE - While logging request and responses, take care of the following:
- Do not log passwords.
- Do not log tokens (the access tokens which are used for Authentication)
- Do not log OTPs
Introduce throttling in your APIs and rate limiting on your application servers
Scenario - You have just launched your service and have marketed the product on social media platforms. A black hat hacker found out, and just wanted to play with your system. So they planned a DOS (Denial of Service) attack on your system.
To combat this, you can set rate limiting based on various factors on top of your load balancers for your application servers. This will take care of DOS attacks and prevent the malicious user from attacking your servers.
Scenario - The API endpoint /otp/validate that takes 4 digit OTPs for authenticating the user and gives back tokens to be used for Authenticated APIs. A malicious user gets the mobile_number for one of your clients, and starts hitting the API endpoint with brute force attack changing the IPs, a DDOS (Distributed Denial of Service) Attack. The rate limiter is not able to stop the user, because the IP keeps on changing with every request made.
To stop this, you can put a throttling on the APIs based on the user as well. You can configure how many requests can be made by a particular user to an API endpoint. For OTP validation, a good number is 5 requests per 10 mins. This will stop the malicious user from performing a brute force DDOS attack on the above API.
Throttling in Django's REST Framework -
https://www.django-rest-framework.org/api-guide/throttling/
Establish and configure asynchronous communication from day one
Scenario - You need to send a welcome email to the user when they register on your application. The front end client hits the Register API, you create the user in the backend after validations, and this starts the process of sending a welcome email.
Sending this welcome email will take time, maybe few seconds. But why would you want the mobile client to be stuck for such a process? This can happen in the background without the user being stuck for no particular reason on the Register page. Every second is precious and you don't want the user to lose those precious seconds.
So just send the email via an Asynchronous task. Use workers, tasks, message brokers and result back ends to perform this.
One good example of this from the Python world is Celery worker. Just put the task that needs to be performed in a message broker (Rabbit MQ/SQS, etc). Celery will listen to this and will send the task to the designated worker. That worker will then process the request and put the result in a result backend which can be a Cache system/database system. (Redis/PostgreSQL for example).
You can monitor these tasks and queues with a lot of third party libraries. A good example of this is Celery Flower which monitors all of this.
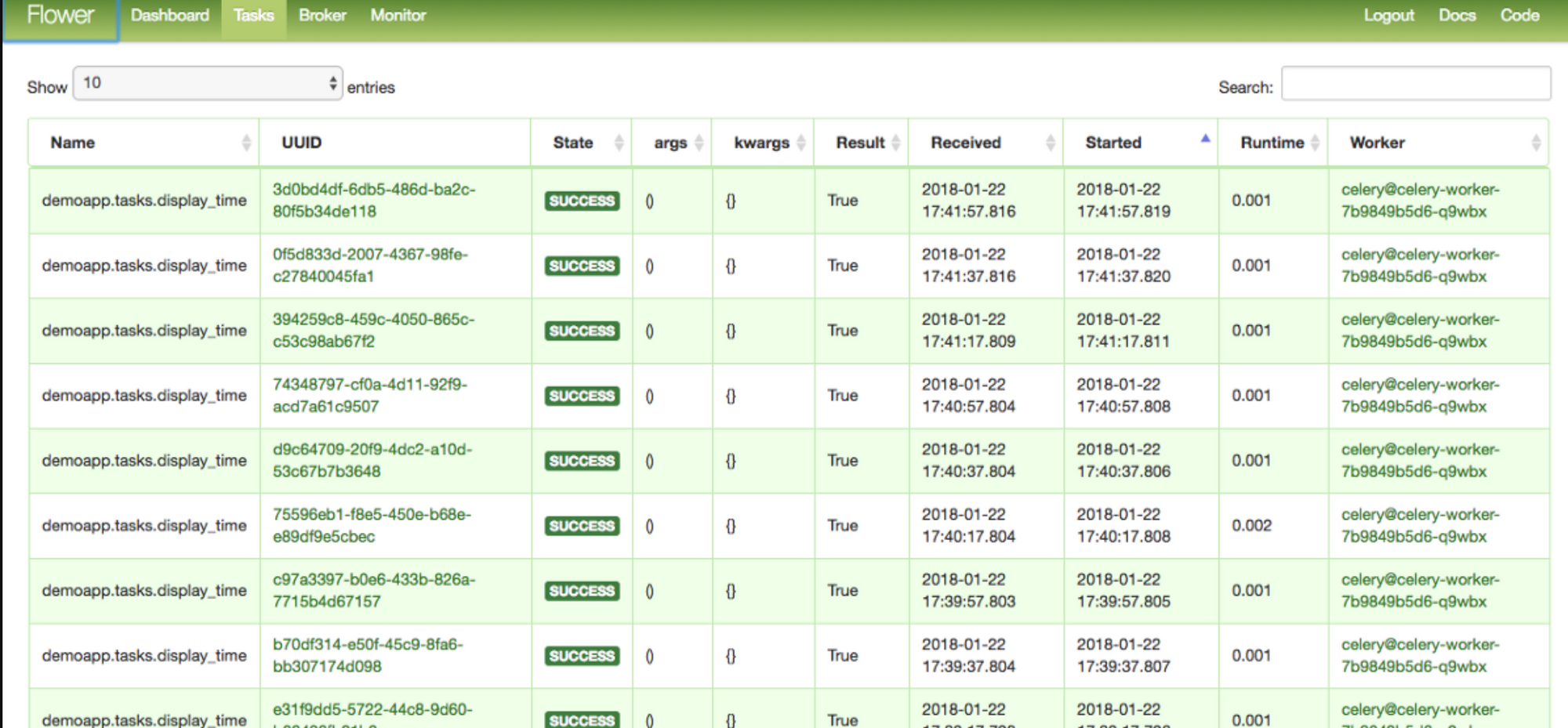
You can read more about RabbitMQ here - https://www.rabbitmq.com/
And Celery - https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html
And finally, Celery Flower - https://flower.readthedocs.io/en/latest/
Set up cron jobs
Scenario - You just launched your product and you need to send recommendations to your users about new products on your platform. You'll send these on the basis of their purchase history each weekend.
The above task can be easily performed using a cron job. It is easily configurable in every framework. The important thing to bear in mind is that you should not put the cron jobs directly in the crontab file of your server. You should let the framework handle it.
This is because the deployment engineer/Devops engineer should be the only person to have access to the system like this for security reasons. Although you don't have to implement it this way it's a good to have thing from the beginning.
In the Django world, you can use celerybeat to configure your crons using celery workers.
Learn more about Celery Beat here -https://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
Manage your secrets properly (parameters file)
There are a lot of ways to manage parameter secrets in your production servers. Some of them are:
- Creating a secrets file and storing it in a private s3 bucket, and pulling the same during deployment of your application.
- Setting the parameters in environment variables during deployment of your application (storing them in s3 again)
- Putting the secrets in some secret management service (e.g. https://aws.amazon.com/secrets-manager/), and using them to get the secrets in your application.
You can chose any of these methods according to your comfort and use case. (You can choose to keep different secret files for local, staging and production environments as well.)
Version your APIs from day one
This is something that you should definitely consider from Day 1. You will never know how frequently your business models might change, and you need to have forward-backward compatibility in your application. So you should version your APIs to ensure everything runs smoothly for everyone.
You can have different apps for different versions and let nginx handle it for your application. Or you can have versioning in the application itself, and let the routes in your application server handle it. You can choose any method to implement it – the main point is to have versioning enabled from the start.
Decide on hard and soft update version checks for your front end clients
So what's the difference between hard and soft updates?
Hard updates refer to when the user is forced to update the client version to a higher version number than what is installed on their mobile.
Soft updates refer to when the user is shown a prompt that a new version is available and they can update their app to the new version if they want to.
Hard updates are not encouraged, but there are times when you need to enforce them. Whatever the case you should definitely consider how you are going to implement this for your applications.
You can do this by implementing or configuring it in the Play Store or App Store. Another way is to create an API in your backend application that will be hit every time the mobile app is launched. This will send two keys: hard_update -> true/false and soft_update -> true/false, depending upon the user's version and the hard and soft update versions set in your backend system.
A good place to store these versions is in your cache (Redis/Memcache), which you can change on the fly without needing to deploy your application.
Introduce continuous integration (CI) from day one
Scenario – one of the interns working in your project isn't proficient enough to write production level code. They may have changed something that might break some critical component in your project. How can you ensure that everything is ok in such cases?
Introduce continuous integration. It will run linters and test cases on each commit, and will break if any rules are violated. This will in turn block pull request from getting merged until all linting rules and test cases pass. It's a nice to have thing, and it actually helps in long run as well, so keep it in mind.
There are a lot of options available in the market. You can either chose to implement one on your own (Jenkins CI/CD), or you can use TravisCI, CircleCI, etc for the same.
Read up on TravisCI here - https://travis-ci.org/
And CircleCI - https://circleci.com/
Enable Docker support (personal preference)
Create a Dockerfile and docker-compose.yml for your application so that everyone runs the application using Docker from the start. One of the main reasons to use such an approach is to have consistency across your local/staging/production environment, so that no developer can ever say this again:
But it ran on my machine.
It's not difficult to employ it from day 1. In the beginning just use Docker for your local environment so that the setup of your application can be really smooth. But keep in mind how you can run it both with and without Docker in production.
Here's more info about Docker Hub - https://hub.docker.com/
Use an APM tool
An Application Monitoring Tool is a must have if you want to monitor your application's APIs, transactions, database connections, and so on.
Scenario - your cron server's hard disc is almost full and it is not able to run cron jobs. Since it can't find space on the disc, your crons are not running. So how can you get notified when this happens?
There are a lot of APM tools that you can use to monitor this. You can configure them according to when you need to be notified. You will get notifications on the medium of your choice when such chaos happens on your system – and trust me it happens all the time. So better be prepared for it. New Relic is a good option.
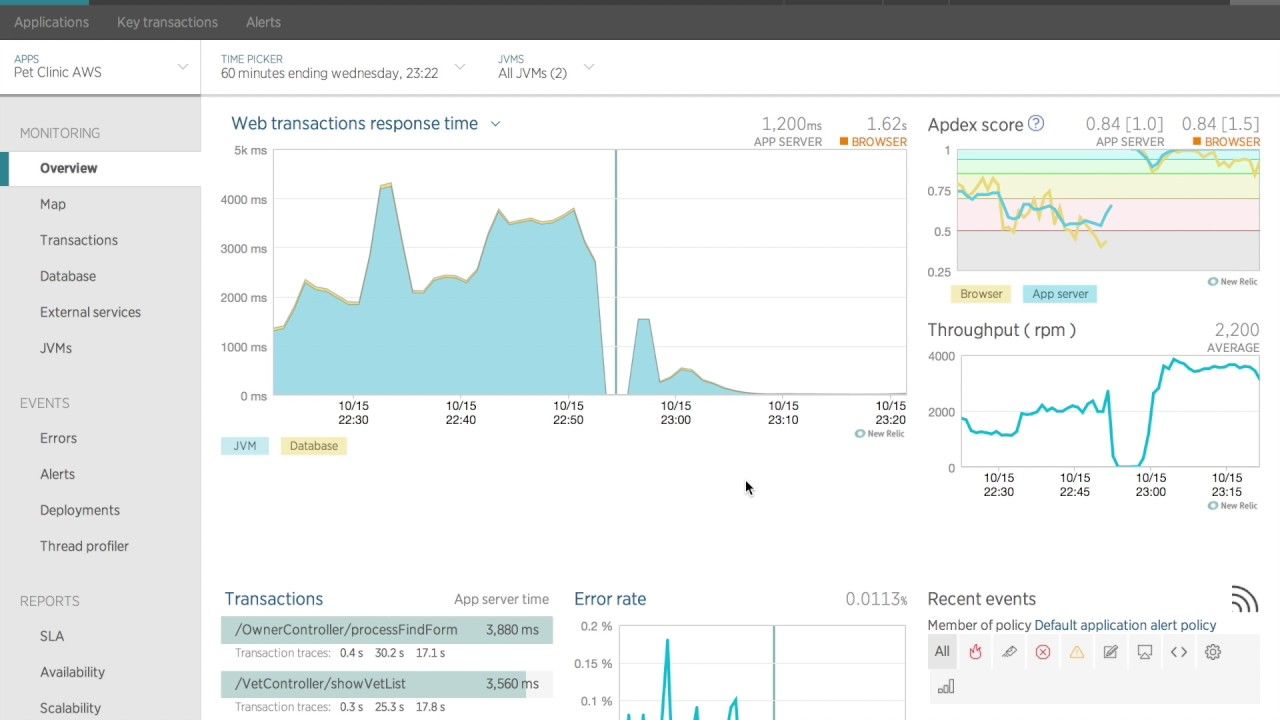
Read more about New Relic here - https://newrelic.com/
Use ElasticSearch to power application-wide searches in your client apps
According to wikipedia,
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
In the beginning, you will be tempted to use traditional database queries to get results in that search bar for the client app. Why? Because it's easy.
But traditional databases are not meant for such performant queries. Figure out a good time to migrate your search to ElasticSearch and introduce a data pipeline into your system. It feeds the elastic search with data and then connects the search from ElasticSearch to the application server.
Here's a good overview of Elasticsearch to get you started.
And the ElasticSearch Docs - https://www.elastic.co/guide/index.html
Put a firewall in your production server
You should definitely do this - it's a must-have. Put a firewall in your production server and close all the ports except the ones to be used for APIs (https connections). Route the API endpoints using a reverse proxy web server, like NGiNX or Apache. No port should be accessible to the outside world other than the ones allowed by NGiNX.
Why you should use NGiNX:
- https://www.nginx.com/resources/wiki/community/why_use_it/
- https://blog.serverdensity.com/why-we-use-nginx/
- https://www.freecodecamp.org/news/an-introduction-to-nginx-for-developers-62179b6a458f/
Wrapping up
The above mentioned points are based off my own preferences and I've developed them over the years. There will be slight differences here and there, but the concepts remain the same.
And in the end we do all this to have a smooth system built from scratch running in production as soon as possible after you've come up with the idea.
I tried penning down all my knowledge that I have acquired over the years, and I might be wrong in a few places. If you think you can offer better info, please feel free to comment. And as always please share if you think this is helpful.