By Mark Watson
A coming-of-age story for your database model
 _Image credit: [Charlotte Parent](http://www.charlotteparent.com/CLT/Health-Development/More-Than-the-Birds-and-the-Bees-Teaching-Your-Child-About-Healthy-Sexuality/" rel="noopener" target="blank" title=")
_Image credit: [Charlotte Parent](http://www.charlotteparent.com/CLT/Health-Development/More-Than-the-Birds-and-the-Bees-Teaching-Your-Child-About-Healthy-Sexuality/" rel="noopener" target="blank" title=")
Graph databases are a great way to store conversational data. A simple dialog tree can add depth to character interactions in a video game. A knowledge graph can extract more meaning from dialog to better understand how user intent relates to an application’s data.
In this article, I’ll show you a basic graph model for capturing chatbot interactions and how to persist them using the Apache TinkerPop framework. I’ll also show you some Gremlin queries for adding a recommendation feature to the chatbot. The source code and setup instructions for my example “Recipe Bot” are on GitHub.
Review: Recipe Bot
The Recipe Bot is a Slack Bot User that lets people request recipes based on specified ingredients or cuisines. Previously I showed you how to add support for users to request their favorite recipes, like so:
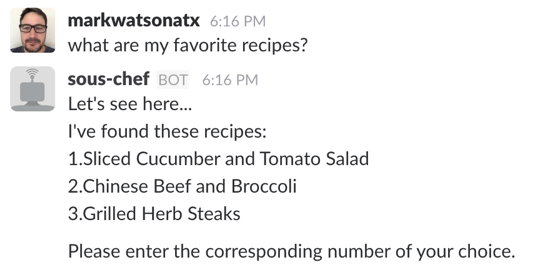
The graph version of the bot has all of the same features I discussed in my previous article on persisting metadata with JSON, but with the graph version you’ll be adding recommendations.
How it works with TinkerPop
Here is an architecture diagram of how the bot works:
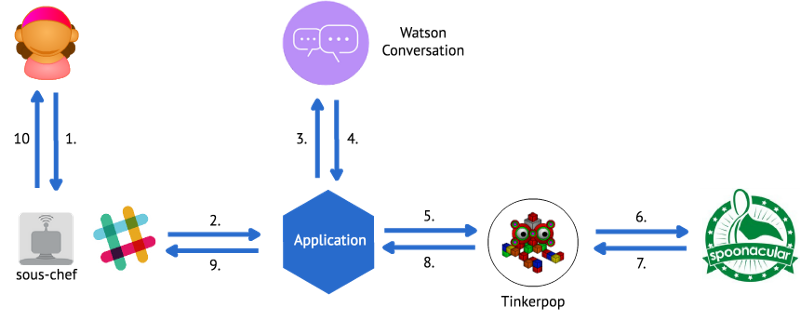 _My Recipe Bot. Hey! The diagram is actually an [undirected graph](https://en.wikipedia.org/wiki/Graph_theory" rel="noopener" target="blank" title="). Who knew?
_My Recipe Bot. Hey! The diagram is actually an [undirected graph](https://en.wikipedia.org/wiki/Graph_theory" rel="noopener" target="blank" title="). Who knew?
You’ll see that I’m using the Watson Conversation service. Watson Conversation lets me describe the flow of the conversation through the use of dialogs, and it helps me extract information and user intent from chat messages. You can code your own dialog tree and perform your own message parsing, or you can use tools like Watson Conversation or Botkit to help. Here is how the dialog tree for the Recipe Bot is modeled:
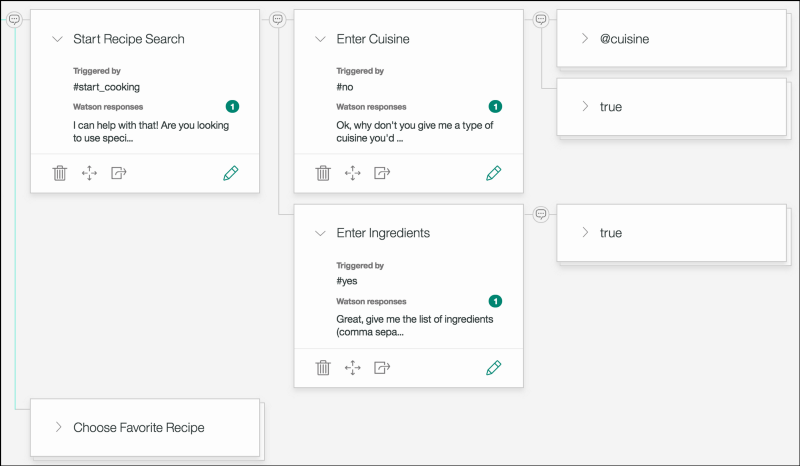 The Watson Conversation UI. Graphs are everywhere.
The Watson Conversation UI. Graphs are everywhere.
You can follow a conversation through the dialog tree similar to how you can follow vertices and edges in a graph (after all, trees are graphs too):
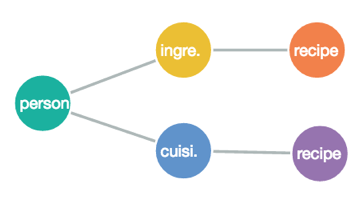 It’s not much of a tree, but I’m keeping it simple, y’all.
It’s not much of a tree, but I’m keeping it simple, y’all.
In the simplified graph above, the Recipe Bot cares only about the progression between the major entities of the bot:
- People
- Ingredients
- Cuisines
- Recipes
Data model & access pattern
As the conversation progresses, you store the following vertices and edges using the TinkerPop API:
- Person vertex: For each person that interacts with the bot, store that person as a vertex in the graph.
{ "label": "person", "type": "vertex", "properties": { "name": "U2JBLUPL2" }}
2. Ingredient or cuisine vertex: When a person requests a specific ingredient or cuisine, you store that ingredient or cuisine — along with the list of recipes retrieved from Spoonacular — as a vertex.
{ "label": "cuisine", "type": "vertex", "properties": { "name": "chinese", "detail": "[{\"id\": 573147, \"title\": \"Kale Fried Rice\"..." }}
3. Selects edge, person → (ingredient | cuisine): You create an edge, labelled "selects", between the person and the ingredient or cuisine (that is, “person selects cuisine”). In addition, store a "count" property on the edge and increment its value each time the user requests the same ingredient or cuisine.
{ "label": "selects", "type": "edge", "inV": 4152, "outV": 4224, "properties": { "count": 3 }}
- Recipe vertex: When a user requests a recipe, store the recipe as a vertex.
{ "label": "recipe", "type": "vertex", "properties": { "name": "573147", "detail": "Ok, it takes *45* minutes to make...*", "title": "Kale Fried Rice" }}
- Selects edge, (ingredient | cuisine) → recipe: You create another
"selects"edge between the ingredient or cuisine and the recipe (that is, “cuisine selects recipe”). In addition, store a"count"property on the edge and increment it each time the ingredient or cuisine selects the same recipe.
{ "label": "selects", "type": "edge", "inV": 4320, "outV": 4152, "properties": { "count": 22 }}
6. Selects edge, person → recipe: You create yet another "selects" edge directly between the person and the recipe (that is, “person selects recipe”). Store a "count" property on the edge and increment it each time a person requests the same recipe.
{ "label": "selects", "type": "edge", "inV": 4320, "outV": 4224, "properties": { "count": 4 }}
7. Has edge, recipe → (ingredient | cuisine): Finally, create an edge, labelled "has", between the recipe and the ingredient or cuisine (that is, “recipe has cuisine”). This relationship allows you to find all the ingredients and cuisines that a recipe uses. There is no count field on this edge.
{ "label": "has", "type": "edge", "inV": 4152, "outV": 4320}
The graph for a single user looks something like this:
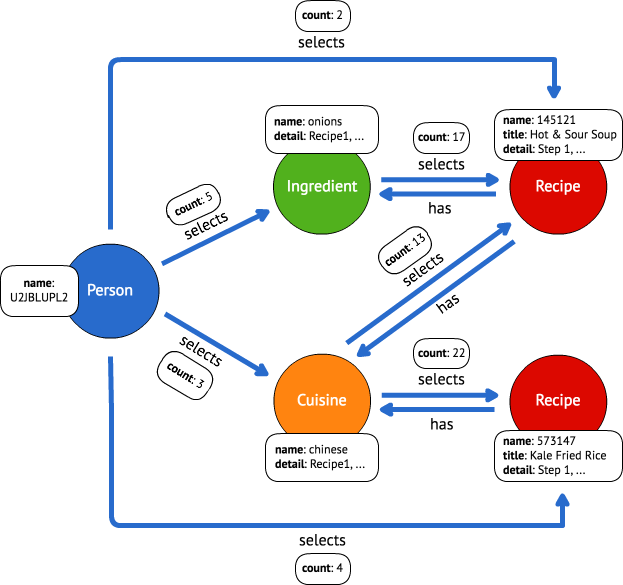 This graph has it going on. It’s a [(weakly) connected graph](https://en.wikipedia.org/wiki/Connectivity%28graph_theory%29#Definitions_of_components.2C_cuts_and_connectivity" rel="noopener" target="blank" title="). There are all kinds of graphs.
This graph has it going on. It’s a [(weakly) connected graph](https://en.wikipedia.org/wiki/Connectivity%28graph_theory%29#Definitions_of_components.2C_cuts_and_connectivity" rel="noopener" target="blank" title="). There are all kinds of graphs.
So far, by using a graph database, you get the following benefits:
- Reduce third-party API calls by caching entities.
- Provide a more personal experience for users by harnessing metadata on their interactions.
A “more personal experience” for Recipe Bot means allowing users to request their favorite recipes. To find a user’s favorite recipes, you use the Gremlin graph traversal language. The following Gremlin query will give you a user’s top-five favorite recipes, sorted by count:
Adding recommendations
Since you track every user interaction with the bot as a graph, you can find popular ingredients, cuisines, or recipes requested by all users. You can use Gremlin to find popular recipes based on an ingredient or cuisine. Here’s how it works:
Let’s say, a user is looking for recipes that use onions:
You can find popular recipes that use onions by issuing the following query. (I’ll unpack it further below—don’t worry!):
This query says, “Give me anyone, excluding the calling user, who has requested recipes more than once that have onions.” It breaks down like so:
- Start with
"onions":
g.V().hasLabel("ingredient").has("name","onions")
- Get the recipes that have
"onions". This API call uses the"has"edge coming from the recipe vertex into the ingredient vertex. Using.in()skips the edge and only returns the recipe vertex. (You don’t need any properties from the edge object, so there’s no reason to return it here.)
.in("has")
- Get the users that have requested these recipes more than once. This call uses the
"selects"edge coming from the person to the recipe:
.inE().has("count",gt(1)).order().by("count", decr)
- Get the users, excluding the current user:
.outV().hasLabel("person").has("name",neq("CURRENT_USER"))
- Get the full path:
.path()
This call returns an array of matching paths that looks like this:
ingredient ← recipe ← edge ← person
You can access these recommended recipes at index 1.
When you return this recipe list to the user, the app puts the recommended recipes at the top and highlights the number of users who have previously used which recipe:
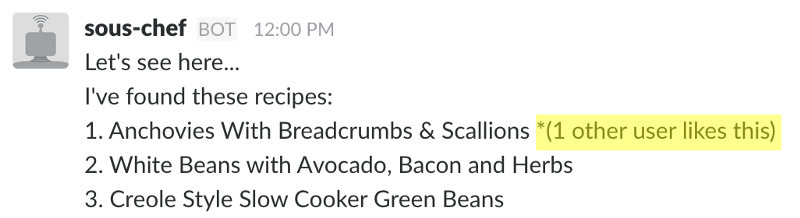
What’s Next?
Try a deployment for yourself. The project’s README has step-by-step instructions for completing your first deployment on IBM Bluemix. There’s also a Java port of the example app.
If you’re already using a dialog tree in your applications and want to use a graph database to persist metadata on interactions, I hope the source code in the repo above gives you some ideas on delivering more personalized experiences to your users.
And if you’ve enjoyed this article, please hit the ol’ ♥ so other Medium users might find it and dig it too. Happy coding!