
By Thomas Simonini
In 2014, the research paper Generative Adversarial Nets (GAN) by Goodfellow et al. was a breakthrough in the field of generative models.
Leading researcher Yann Lecun himself called adversarial nets “the coolest idea in machine learning in the last twenty years.”
Today, thanks to this architecture, we’re going to build an AI that generates realistic pictures of cats. How awesome is that?!
 DCGAN during training
DCGAN during training
To view the full working code, see my Github repository. It will help if you already have some experience in Python, Deep Learning and Tensorflow, and CNNs (Convolutional Neural Nets).
If you new in Deep Learning, please check this excellent series of articles:
Machine Learning is Fun!
_The world’s easiest introduction to Machine Learning_medium.com
What is DCGAN?
Deep Convolutional Generative Adverserial Networks (or DCGAN) are a deep learning architecture that generate outputs similar to the data in the training set.
This model replaces the fully connected layers of the generative adversarial network model with convolution layers.
To explain how DCGAN works, let’s use the metaphor of the art expert and the counterfeiter.
The counterfeiter (a.k.a. “the generator”) tries to produce fake Van Gogh paintings and pass them off as real.
 _Criminal icon made by Roundicon from [www.flaticon.com](http://www.flaticon.com" rel="noopener" target="blank" title="Flaticon)
_Criminal icon made by Roundicon from [www.flaticon.com](http://www.flaticon.com" rel="noopener" target="blank" title="Flaticon)
On the other hand, the art expert (a.k.a., “the discriminator”) tries to catch the counterfeiter by using their knowledge of real Van Gogh paintings.

Over time, the art expert gets better at detecting counterfeit paintings, and the counterfeiter gets better at faking them.

As we see, DCGANs are composed of two separate deep neural networks competing against each other.
- The generator is a counterfeiter trying to produce seemingly real data. It has no idea of what the real data is, but it learns to adjust from the feedback of the other model.
- The discriminator is a inspector trying to determine what the fake counterfeit data is (by comparing it with real data), while trying to not raise false positives on the real data. The output results of this model will serve for the backpropagation of the generator.
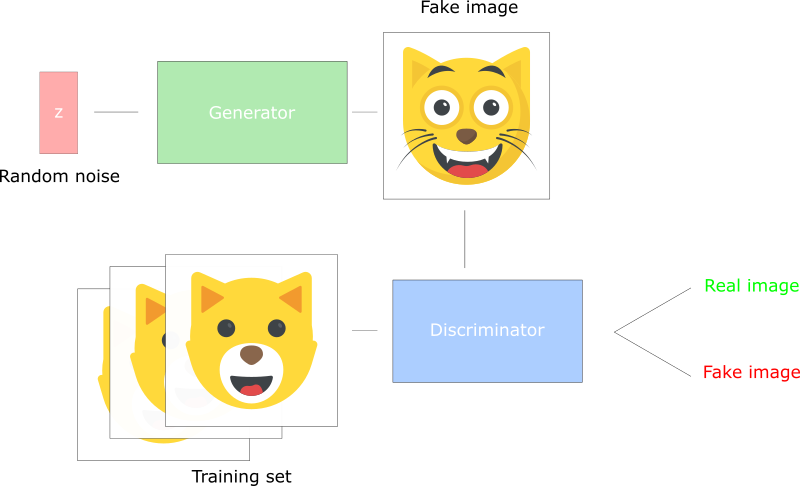 DCGAN illustration
DCGAN illustration
- The generator takes a random noise vector and generates a picture.
- This picture is fed into the discriminator, which compares the training set against the generated image.
- The discriminator returns a number between 0 (fake image) and 1 (real image).
Let’s create a DCGAN!
Now, we’re ready to create our AI.
In this part, we will focus on the main elements of our model. If you want to check out the whole code, use the notebook here.
Inputs
Here, we create the inputs placeholders: inputs_real for the discriminator and inputs_z for the generator.
Note that we use two learning rates, one for the generator and one for the discriminator.
DCGANs are very sensitive to hyperparameters, so it’s very important to tune them precisely.
The discriminator and the generator
We use tf.variable_scope for two reasons.
First, we want to make sure that all variables names start with generator / discriminator. This will help out later when we train the two networks.
Second, we want to reuse these networks with different inputs:
- For the generator: we’re going to train it, but also sample fake images from it after training.
- For the discriminator: we need to share variables between the fake and real input images.
 The discriminator
The discriminator
Now let’s create the discriminator. Remember, it takes as an input a real or fake image and outputs a score.
Some technical remarks:
- The principle is to double the filter size at each convolution layer.
- It’s not recommended to use downsampling. Instead, we use only strided convolutional layers.
- We use batch normalization at each layer (except for the input layer), because it reduces the covariance shift. For more information, check this great article.
- We utilize Leaky ReLU as an activation function, because it helps to avoid the vanishing gradient effect.

Then, we create the generator. Remember, it takes as an input a random noise vector (z) and outputs a fake image, thanks to transposed convolution layers.
The idea is that at each layer we halve the filter size, and double the size of the picture.
The generator has been found to perform best using tanh as the output activation function.
Discriminator and generator losses
Because we train the generator and discriminator at the same time, we need to calculate losses for both networks.
We want the discriminator to output 1 when it “thinks” an image is real, and 0 for fake images. Therefore, we need to set up the losses to reflect that.
The discriminator loss is the sum of loss for real and fake images:
d_loss = d_loss_real + d_loss_fake
d_loss_real is the loss when the discriminator predicts an image is fake, when in fact it was a real image. It is calculated as follows:
- Use
d_logits_realand labels are all 1 (since all real data is real) labels = tf.ones_like(tensor) * (1 - smooth)We use label smoothing: it means reducing the labels a bit from 1.0 to 0.9 in order to help the discriminator generalize better.
d_loss_fake is the loss when the discriminator predict an image is real, when in fact is was a fake image.
- Use
d_logits_fakeand labels are all 0.
The generator loss again uses the d_logits_fake from the discriminator. This time the labels are all 1, because the generator wants to fool the discriminator.
Optimizers
After calculating the losses, we need to update the generator and discriminator separately.
To do this, we need to get the variables for each part by using tf.trainable_variables(). This creates a list of all the variables we’ve defined in our graph.
Training
Here, we’re implementing the training function.
The idea is relatively simple:
- We’re saving the model each five epochs.
- We’re saving a picture in images folder each ten batches trained.
- We’re displaying the
g_loss , d_lossand the image generated each 15 epochs. This is for a simple reason: Jupyter notebook can bug if too many pictures are displayed. - Or, we can directly generate real images by loading the saved model (this will save you 20 hours of training).
How to run it
You can’t run this on your personal computer — unless you have your own GPUs or are ready to wait maybe 10 years!
Instead, you must use cloud GPU services, such as AWS or FloydHub.
Personally, I trained this DCGAN for 20 hours with Microsoft Azure and their Deep Learning Virtual Machine.
Disclaimer: I don’t have any business relations with Azure. I just loved their excellent customer service!
If you have trouble running it on a virtual machine, follow this excellent article here.
That’s all, I hope that this tutorial has been helpful!
If you’ve improved the model, don’t hesitate to make a pull request.

If you have any thoughts, comments, or want to show me your results, feel free to comment below or send me an email: hello@simoninithomas.com, or tweet me @ThomasSimonini.
And if you liked my article, please click the ? below so other people will see this here on Medium. And don’t forget to follow me!
Cheers!