
By Sterling Osborne, PhD Researcher
Following my recent article on applying Reinforcement Learning to real life problems, I decided to demonstrate this with a small example. The aim is to create an algorithm that can find a suitable choice of food products to fit within a budget and meet my personal preferences.
I have also posted the description, data and code kernel to Kaggle and this can be found here.
Please let me know if you have any questions or suggestions.

Aim
When food shopping, there are many different products for the same ingredient to choose from in supermarkets. Some are less expensive, others are of higher quality. I would like to create a model that, for the required ingredients, can select the optimal products required to make a meal that is both:
- Within my budget
- Meets my personal preferences
To do this, I will first build a very simple model that can recommend the products that are below my budgets before introducing my preferences.
The reason we use a model is so that we could, in theory, scale the problem to consider more and more ingredients and products that would cause the problem to then be beyond the possibility of any mental calculations.
Method
To achieve this, I will be building a simple reinforcement learning model and I’ll use Monte Carlo learning to find the optimal combination of products.
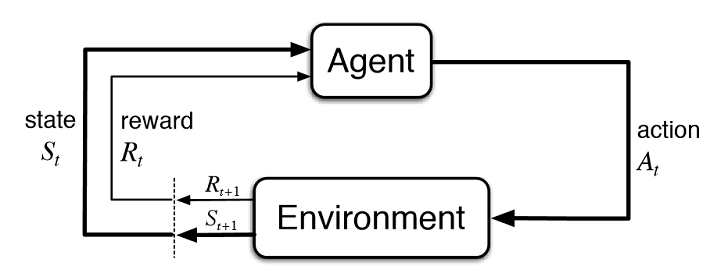
First, let us formally define the parts of our model as a Markov Decision Process:
- We have a finite number of ingredients required to make any meal and are considered to be our States
- There are the finite possible products for each ingredient and are therefore the Actions of each state
- Our preferences become the Individual Rewards for selecting each product, we will cover this in more detail later
Monte Carlo learning takes the combined the quality of each step towards reaching an end goal and requires that, in order to assess the quality of any step, we must wait and see the outcome of the whole combination. This process is repeated over and over again in episodes with many different products until is finds the selection that appears to lead to a positive outcome repeatedly. This is the reinforcement learning process where our environment is simulated based on the knowledge about costs and preferences we obtained.
Monte Carlo is often avoided due to the time required to go through the whole process before being able to learn. However, in our problem it is required as our final check when establishing whether the combination of products selected is good or bad is to add up the real cost of those selected and check whether or not this is below or above our budget. Furthermore, at least at this stage, we will not be considering more than a few ingredients and so the time taken is not significant in this regard.
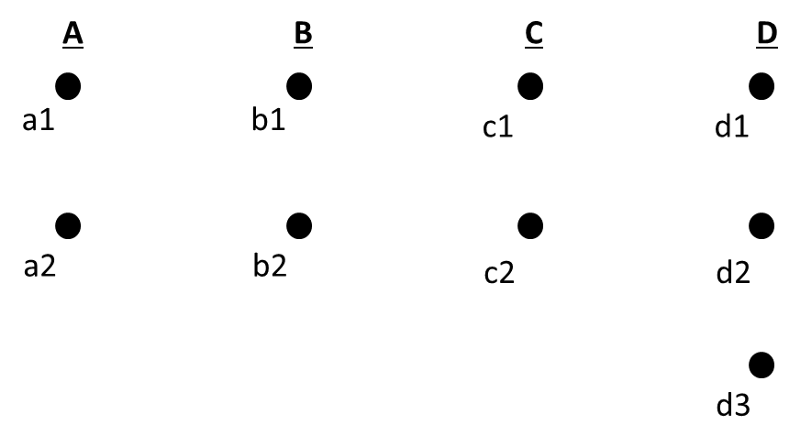
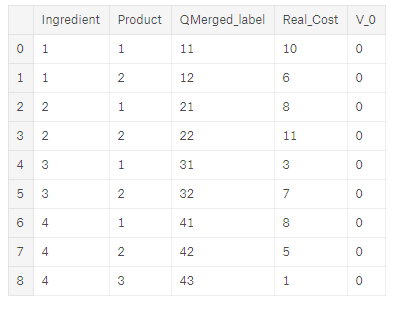
Sample Data
For this demonstration, I have created some sample data for a meal where we have 4 ingredients and 9 products, as shown in the diagram below.
We need to select one product for each ingredient in the meal.
This means we have 2 x 2 x 2 x 3 = 24 possible selections of products for the 4 ingredients.
I have also included the real cost for each product and V_0.
V_0 is simply the initial quality of each product to meet our requirements and we set this to 0 for each.
First, we import the required packages and data.
Applying the Model in Theory
For now, I will not introduce any individual rewards for the products. Instead, I will simply focus on whether the combination of products selected is below our budget or not. This outcome is defined as the Terminal Reward of our problem.
For example, say we have a budget of £30, then the choice:
a1→b1→c1→d1
Then the real cost of this selection is:
£10+£8+£3+£8 = £29 < £30
And therefore, our terminal reward is:
R_T=+1
Whereas,
a2→b2→c2→d1
Then the real cost of this selection is:
£6+£11+£7+£8 = £32 > £30
And therefore, our terminal reward is:
R_T=−1
For now, we are simply telling our model whether the choice is good or bad and will observe what this does to the results.
Model Learning
So how does our model actually learn? In short, we get our model to try out lots of combinations of products and at the end of each tell it whether its choice was good or bad. Over time, it will recognise that some products generally lead to getting a good outcome while others do not.
What we end up creating are values for how good each product is, denoted V(a). We have already introduced the initial V(a) for each product, but how do we reach go from these initial values to actually being able to make a decision?
For this, we need an Update Rule. This tells the model, after each time it has presented its choice of products and we have told it whether it’s selection is good or bad, how to add this to our initial values.
Our update rule is as follows:
This may look unusual at first but in words we are simply updating the value of any action, V(a), by an amount that is either a little more if the outcome was good or a little less if the outcome was bad.
G is the Return and is simply to total reward obtained. Currently in our example, this is simply the terminal reward (+1 or -1 accordingly). We will reintroduce this later when we include individual product rewards.
Alpha, αα, is the Learning Rate and we will demonstrate how this effects the results more later but just for now, the simple explanation is: “The learning rate determines to what extent newly acquired information overrides old information. A factor of 0 makes the agent learn nothing, while a factor of 1 makes the agent consider only the most recent information.” (https://en.wikipedia.org/wiki/Q-learning)
Small Demo of Updating Values
So how do we actually use this with our model?
Let us start with a table that has each product and its initial V_0(a):
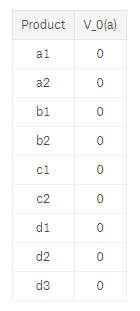
We now pick a random selection of products, each combination is known as an episode. We also set α=0.5α=0.5 for now just for simplicity in the calculations.
For example:

Therefore, all actions that lead to this positive outcome are updated as well to produced the following table with V1(a):
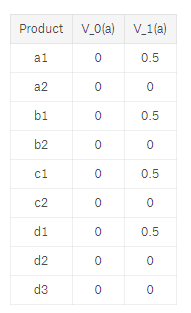
So let us try again by picking another random episode:

Therefore, we can add V2(a) to our table:

Action Selection
You may have noticed in the demo, I have simply randomly selected the products in each episode. We could do this, but using a completely random selection process may mean that some actions are not selected often enough to know whether they are good or bad.
Similarly, if we went another way and decided to select the products greedily, i.e. to ones that currently have the best value, we may miss one that is in fact better but was never given a chance. For example, if we chose the best actions from V2(a) we would get a2, b1, c1 and d2 or d3 which both provide a positive terminal reward therefore, if we used a purely greedy selection process, we would never consider any other products as these continue to provide a positive outcome.
Instead, we implement epsilon-greedy action selection where we randomly select products with probability ϵ, and greedily select products with probability 1−ϵ1−ϵ where:
This means that we are going reach the optimal choice of products quickly, as we continue to test whether the ‘good’ products are in fact optimal. But it also leaves room for us to also explore other products occasionally, just to make sure they aren’t as good as our current choice.
Building and Applying our Model
We are now ready to build a simple model as shown in the MCModelv1 function below.
Although this seems complex, I have done nothing more than apply the methods previously discussed in such a way that we can vary the inputs and still obtain results. Admittedly, this was my first attempt at doing this and so my coding may not be perfectly written but should be sufficient for our requirements.
To calculate the terminal reward, we currently use the following condition to check if the total cost is less or more than our budget:

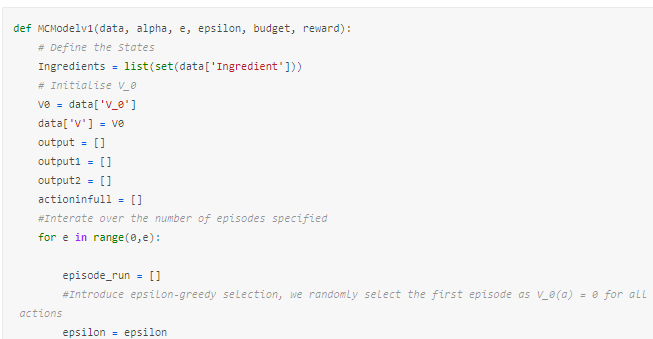
The full code for the model is too large to fit here nicely, but can be found at the linked Kaggle page.
We now run our model with some sample variables:
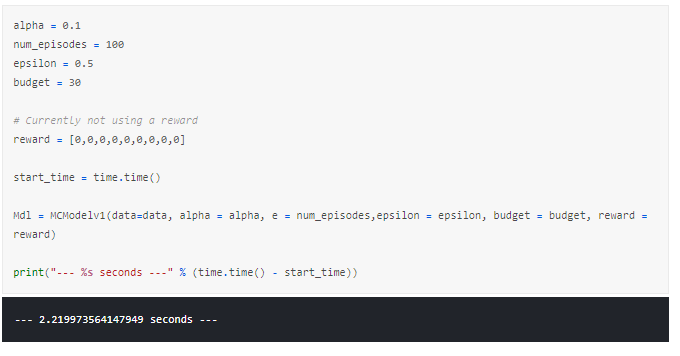
In our function, we have 6 outputs from the model:
- Mdl[0]: Returns the Sum of all V(a) for each episode
- Mdl[1]: Returns to Sum of V(a) for the cheapest products, possible to define due to the simplicity of our sample data
- Mdl[2]: Returns the Sum of V(a) for the non-cheapest products
- Mdl[3]: Returns the optimal actions of the final episode
- Mdl[4]: Returns the data table with the final V(a) added for each product
- Mdl[5]: Shows the optimal action at each episode
There is a lot to take away from these, so let us go through each and establish what we can learn to improve our model.
Optimal actions of final episode
First, let’s see what the model suggests we should select. In this run it suggests actions, or products, that have a total cost below budget which is good.
However, there is still more that we can check to help us understand what is going on.
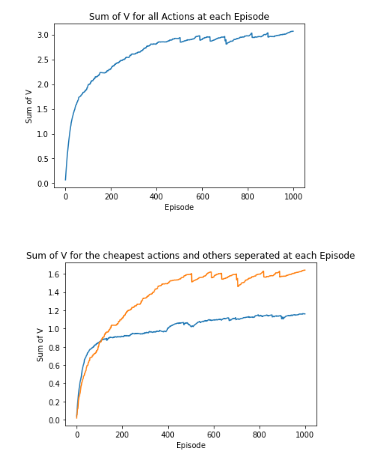
First, we can plot the total V for all actions, and we see that this is converging, which is ideal. We want our model to converge so that as we try more episodes we are ‘zoning-in’ on the optimal choice of products. The reason the output converges is because we are reducing the amount it learns each time by a factor of αα, in this case 0.5. We will show later what happens if we vary this or don’t apply this at all.
We have also plotted the sum of V for the products we know are cheapest, based on being able to assess the small sample size, and the others separately. Again, both are converging positively although the cheaper products appear to have slightly higher values.
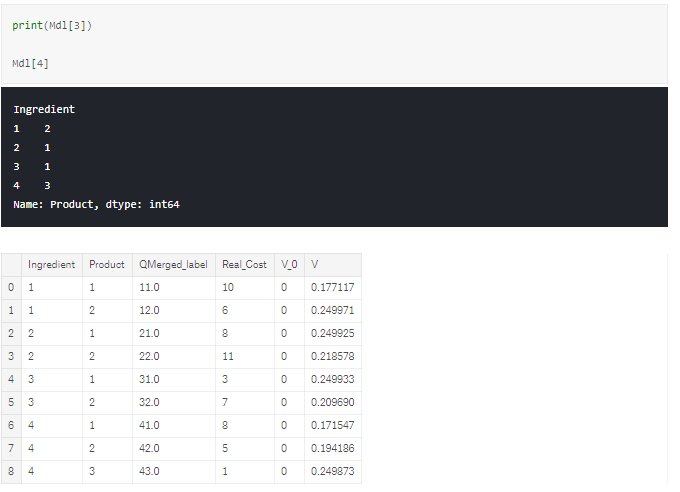
So why is this happening and why did the model suggest the actions it did?
To understand that, we need to dissect the suggestions made by the model at each episode and how this relates to our return.
Below, we have taken the optimal action for each state. We can see that the suggested actions do vary greatly between episodes and the model appears to decide which is wants to suggest very quickly.
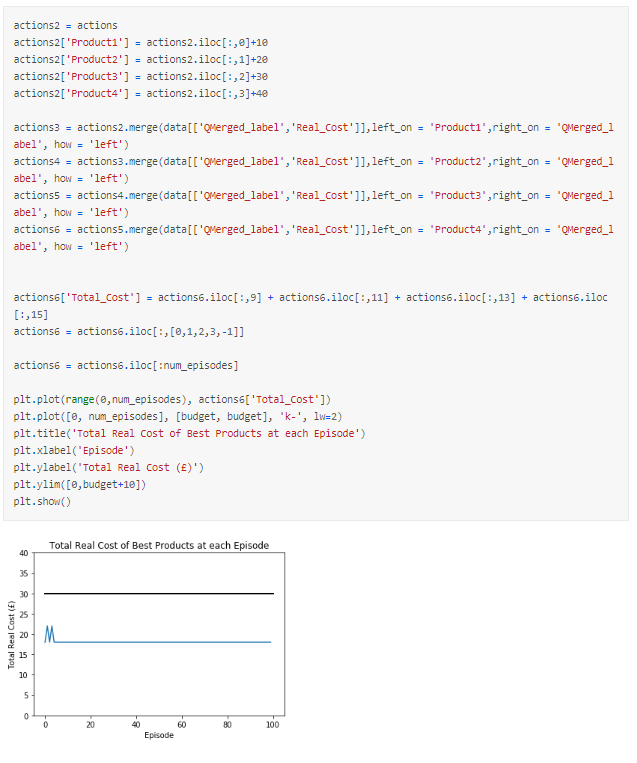
Therefore, I have plotted the total cost of the suggested actions at each episode and we can see the actions vary initially then smooth out and the resulting total cost is below our budget. This helps us understand what is going on greatly.
So far, all we have told the model is to provide a selection that is below budget and it has. It has simply found a answer that is below the budget as required.
So what is the next step? Before I introduce rewards I want to demonstrate what happens if I vary some of the parameters and what we can do if we decide to change what we want our model to suggest.

Effect of Changing Parameters and How to Change Model’s Aim
We have a few parameters that can be changed:
- The Budget
- Our learning rate, α
- Out action selection parameter, ϵ
Varying Budget
First, let us observe what happens if we make our budget either impossibly low or high.
A small budget means we only obtain a negative reward means that we will force our V to converge negatively whereas a budget that is too high will cause our V to converge positively as all actions are continually positive.
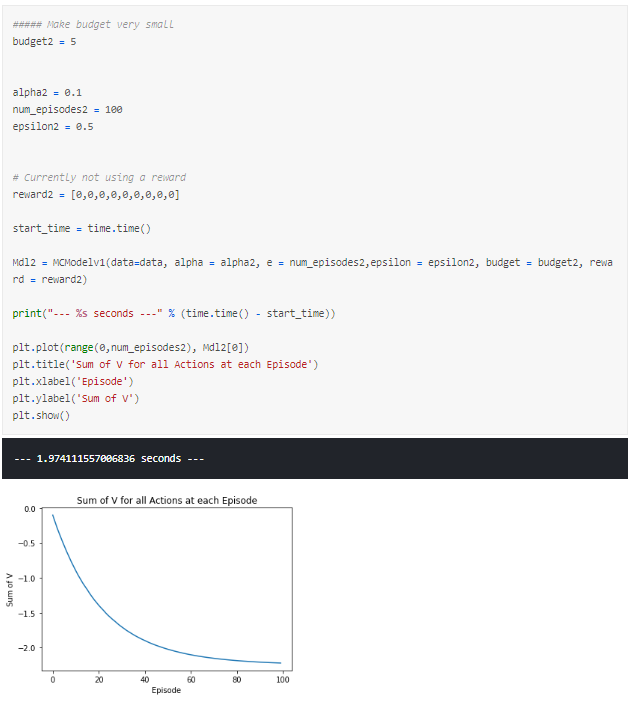
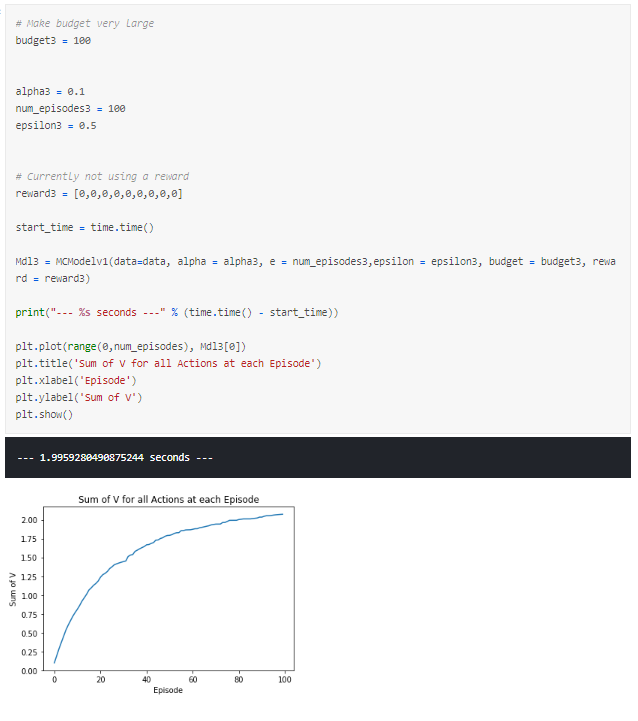
The latter seems like what we had in our first run, a lot of the episodes lead to positive outcomes and so many combinations of products are possible and there is little distinction between the cheapest products from the rest.
If instead we consider a budget that is reasonably low given the prices of the products, we can see a trend where the cheapest products look to be converging positively and the more expensive products converging negatively. However, the smoothness of these is far from ideal, both appear to be oscillating greatly between each episode.
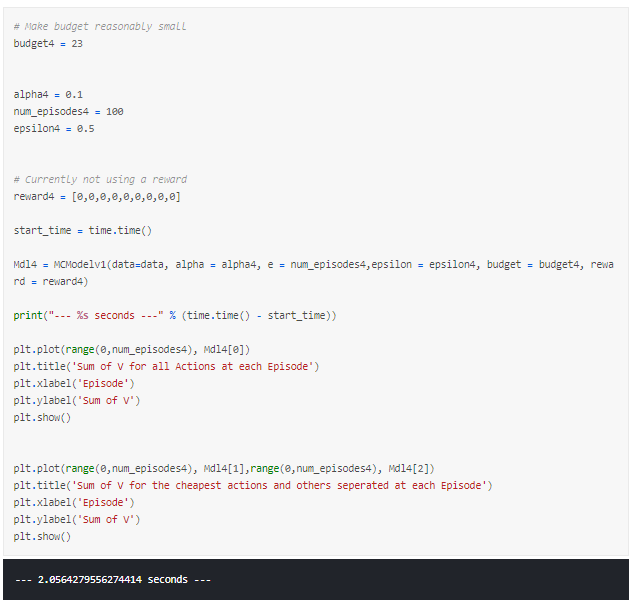
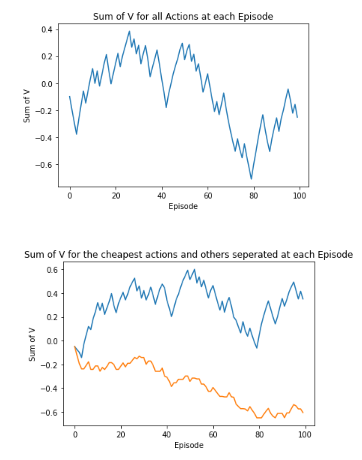
So what can we do the reduce the ‘spikiness’ of the outputs? This leads us onto our next parameter, alpha.
Varying Alpha
A good explanation of what is going on with our output due to alpha is described by stack overflow user VishalTheBeast:
“Learning rate tells the magnitude of step that is taken towards the solution.
It should not be too big a number as it may continuously oscillate around the minima and it should not be too small of a number else it will take a lot of time and iterations to reach the minima.
The reason why decay is advised in learning rate is because initially when we are at a totally random point in solution space we need to take big leaps towards the solution and later when we come close to it, we make small jumps and hence small improvements to finally reach the minima.
Analogy can be made as: in the game of golf when the ball is far away from the hole, the player hits it very hard to get as close as possible to the hole. Later when he reaches the flagged area, he choses a different stick to get accurate short shot.
So it’s not that he won’t be able to put the ball in the hole without choosing the short shot stick, he may send the ball ahead of the target two or three times. But it would be best if he plays optimally and uses the right amount of power to reach the hole. Same is for decayed learning rate.” — source
To better demonstrate the effect of varying our alpha, I will be using an animated plot created using Plot.ly.
I have written a more detailed guide on how to do this here.
In our first animation, we vary alpha between 1 and 0.1. This enables us to see that as we reduce alpha our output smooths somewhat but it still pretty rough.
However, even though the results are smoothing out, they are no longer converging in 100 episodes and, furthermore, they output seems to alternate between each alpha. This is due to a combination of small alphas requiring more episodes to learn and out action selection parameter epsilon being 0.5. Essentially, the output is still being decided by randomness half of the time and so out results are not converging within the 100 episode frame.
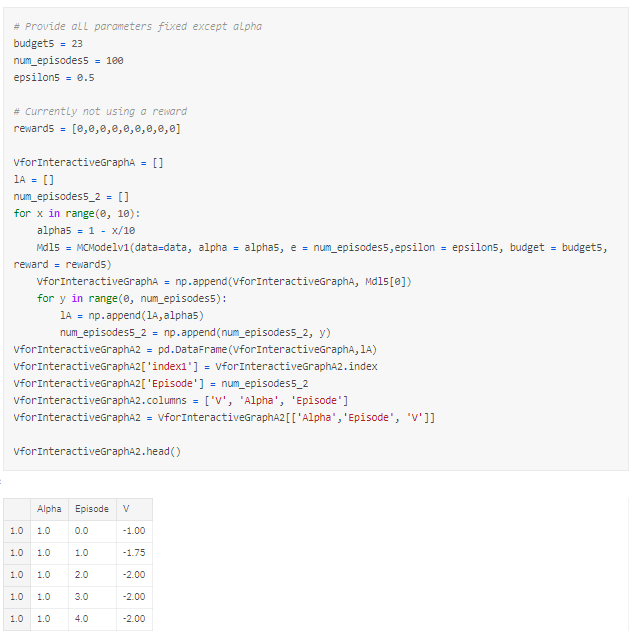
Running this through our animated plots produces something similar to the following:
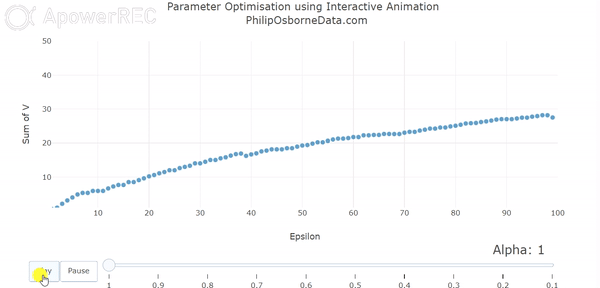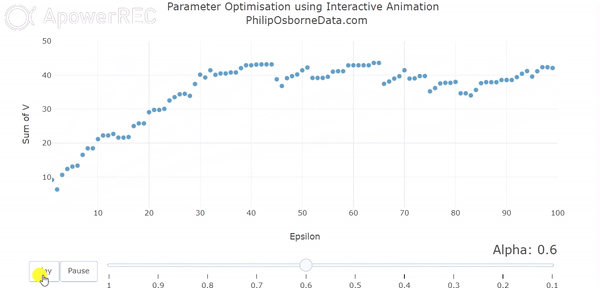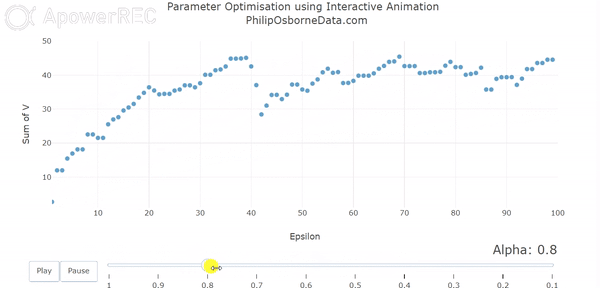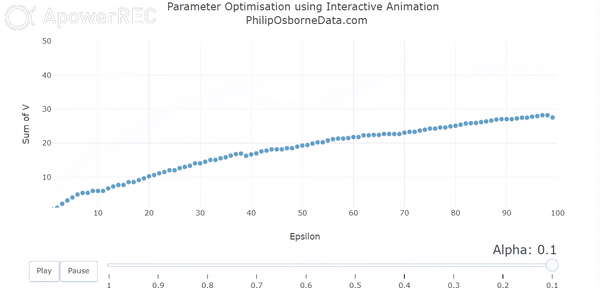
Varying Epsilon
With the previous results in mind, we now fix alpha to be 0.05 and vary epsilon between 1 and 0 to show the effect of completely randomly selecting actions to selecting actions greedily.
The graphs below show three snapshots from varying epsilon, but the animated version can be viewed in the Kaggle kernel.
We see that having a high epsilon creates very sporadic results. Therefore we should select something reasonably small like 0.2. Although have epsilon equal to 0 looks good because of how smooth the curve is, as we mentioned earlier, this may lead us to a choice very quickly but may not be the best. We want some randomness so the model can explore other actions if needed.
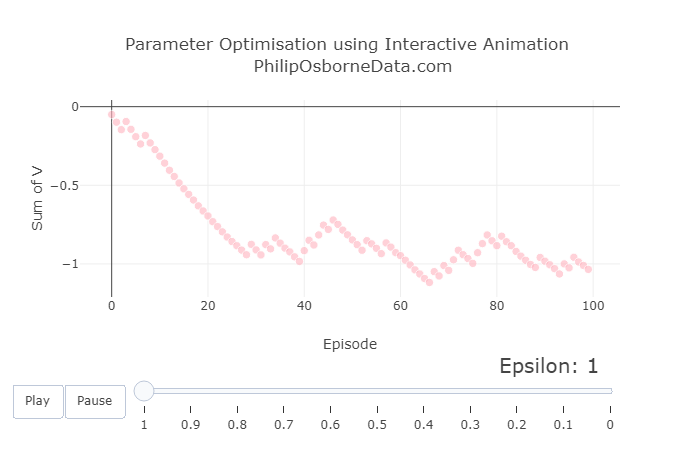
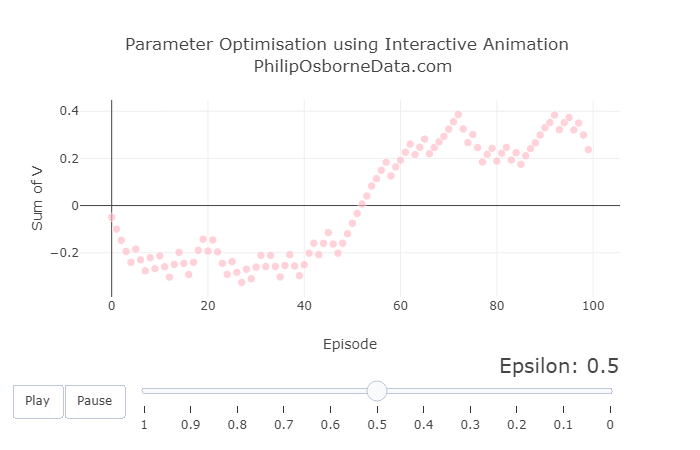
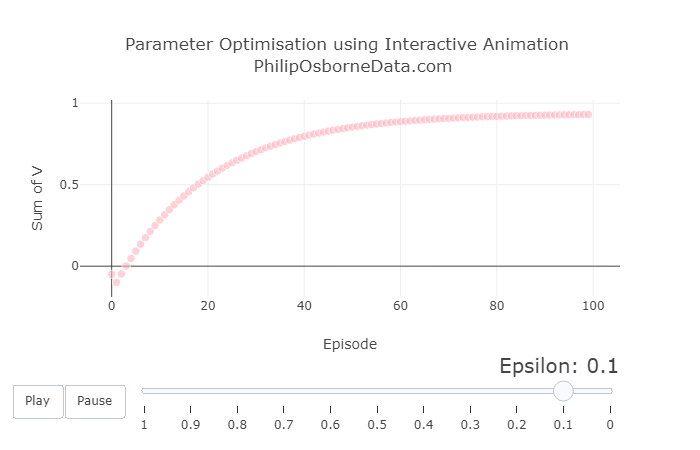
Increasing the Number of Episodes
Lastly, we can increase the number of episodes. I refrained from doing this sooner because we were running 10 models in a loop to output our animated graphs and this would have caused the time taken to run the model to explode.
We noted that a low alpha would require more episodes to learn so we can run our model for 1000 episodes.
However, we still notice that the output is oscillating, but, as mentioned before, this is due to our aim being simply to recommend a combination that is below budget. What this shows is that the model can’t find the single best combination when there are many that fit below our budget.
Therefore, what happens if we change our aim slightly so that we can use the model to find the cheapest combination of products?
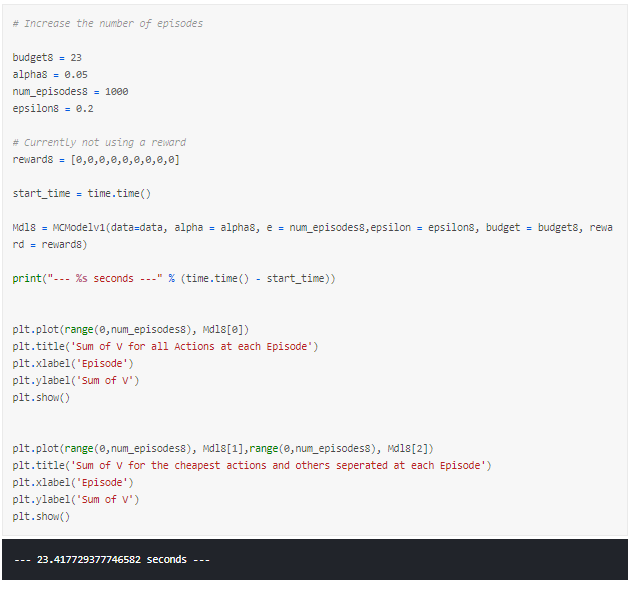
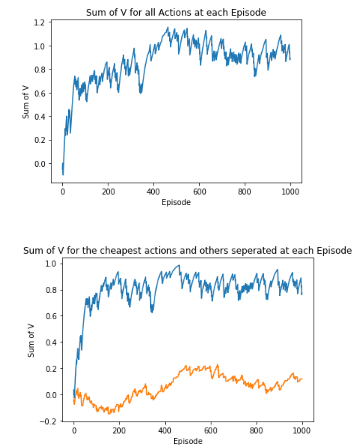
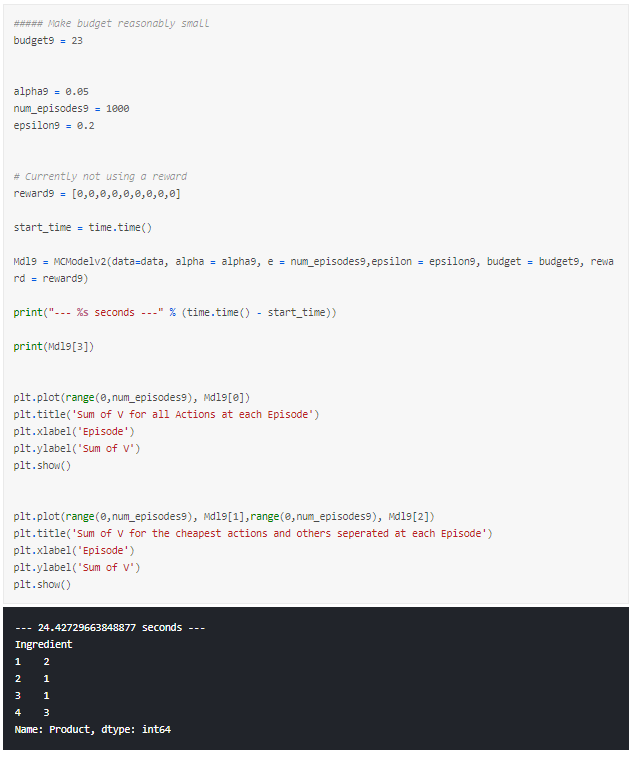
Changing our Model’s Aim to Find the Cheapest Combination of Products
This aim of this it to more clearly separate the cheapest products from the rest, and it nearly always provides us with the cheapest combination of products.
To do this, all we need do is adapt our model slightly to provide a terminal reward that is relative to how far below or above budget this combination in the episode is.
This can done by changing the calculation for return to:

We now see that the separation between the cheapest products and the others is emphasised.
This really demonstrates the flexibility of reinforcement learning and how easy it can be to adapt the model based on your aims.
Introducing Preferences
So far, we have not included any personal preferences towards products. If we wanted to include this, we can simply introduce rewards for each product whilst still having a terminal reward that encourages the model to be below budget.
This can done by changing the calculation for return to:

So why is our return calculation now like this?
Well firstly, we still want our combination to be below budget so we provide the positive and negative rewards for being above and below budget respectively.
Next, we want to account for the reward of each product. For our purposes, we define the rewards to be a value between 0 and 1. MC return is formally calculated using the following:
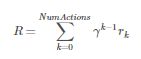
γ is the discount factor and this tells us how much we value later steps compared to earlier steps. In our case, all actions are equally as important to reaching the desired outcome of being below budget so we set γ=1.
However, to ensure that we reach the primary goal of being below budget, we take the average of the sum of the rewards for each action so that this will always be less than 1 or -1 respectively.
Again, the full model can be found in the Kaggle kernel but is too large to link here.
Introducing Preferences using Rewards
Say we decided we wanted product a1 and b2, we could add a reward to each. Let us see what happens if we do this in the output and graphs below. We have changed out budget slightly as a1 and b2 add up to £21 which means there is no way to select two more products that would put it below a budget of £23.
Applying a very high reward forces the model to pick a1 and b2 then work around to find products that will put it under our budget.
I have kept in the comparison between the cheapest products and the rest to show that the model now is not valuing the cheapest once more. Instead we get the output a1, b2, c1 and d3 which has a total cost of £25. This is both below our budget and includes our preferred products.
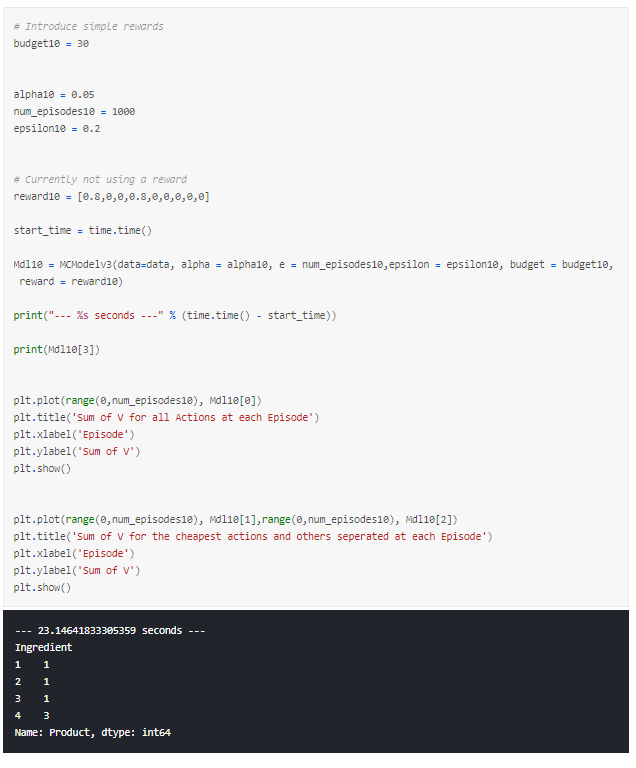
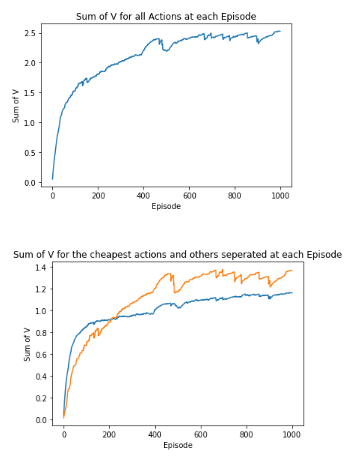
Let’s try one more reward signal. This time, I give some reward to each but want it to provide the best combination from my rewards that still keeps us below budget.
We have the following rewards:
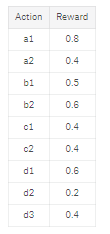
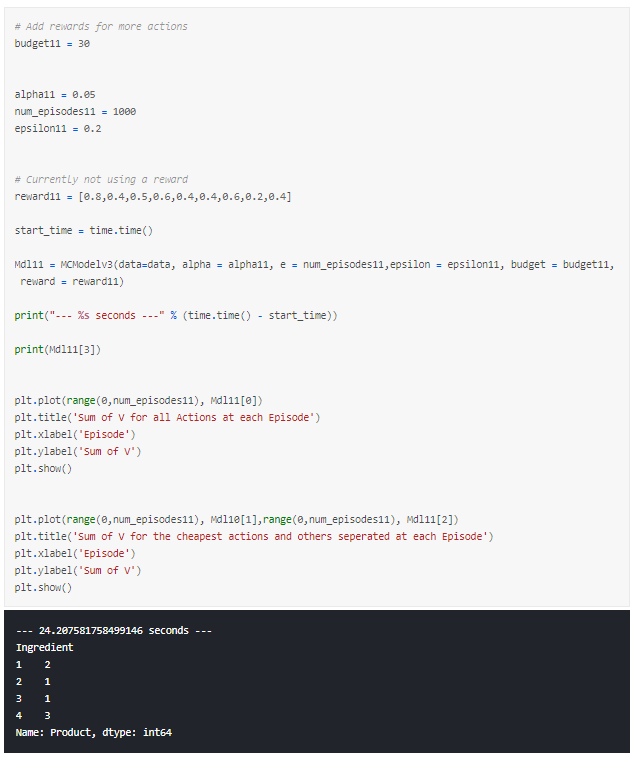
Running this model a few times shows that it would:
- Often select a1 as this has a much higher reward
- Would always pick c1, as the rewards are the same but it is cheaper
- Had a hard time selecting between b1 and b2 as the rewards are 0.5 and 0.6 but the costs are £8 and £11 respectively
- Would typically select d3 as being significantly cheaper than d1 even though reward is slightly less
Conclusion
We have managed to build a Monte Carlo Reinforcement Learning model to:
- recommend products below a budget,
- recommend the cheapest products, and
- recommend the best products based on a preference that is still below a budget.
Along the way, we have demonstrated the effect of changing parameters in reinforcement learning and how understanding these enables us to reach a desired result.
There is much more that we could do, in my mind, the end goal would be to apply to a real recipe and products from a supermarket where the increased number of ingredients and products need to be accounted for.
I created this sample data and problem to better my understanding of Reinforcement Learning and hope that you find it useful.
Thanks for reading!
Sterling Osborne