
By Vaibhav Gupta
In this tutorial, I’ll be using python to scrape data from the Google Summer of Code (GSoC) archive about the participating organizations from the year 2009.
My Motivation Behind This Project
While I was scrolling through the huge list of organisations that participated in GSoC’18, I realised that exploring an organisation is a repetitive task - choose one, explore its projects, check that if it has participated in previous years or not. But, there are 200+ organizations, and going through them all would take a whole lot of time. So, being a lazy person, I decided to use python to ease my work
Requirements
- Python (I’ll be using python3.6, because f-strings are awesome ?)
- Pipenv (for virtual environment)
- requests (for fetching the web page)
- Beautiful Soup 4 (for extracting data from the web pages)
Building Our Script
These are the web pages which we are going to scrape:
Coding Part
 _[GIF from Giphy](https://giphy.com/gifs/nascar-owen-wilson-daytona-500-xTiN0GMUaOI726QYZa" rel="noopener" target="blank" title=")
_[GIF from Giphy](https://giphy.com/gifs/nascar-owen-wilson-daytona-500-xTiN0GMUaOI726QYZa" rel="noopener" target="blank" title=")
Step 1: Setting up the virtual environment and installing the dependencies
virtualenv can be used to create a virtual environment, but I would recommend using Pipenv because it minimizes the work and supports Pipfile and Pipfile.lock.
Make a new folder and enter the following series of commands in the terminal:
pip install pipenv
Then create a virtual environment and install all the dependencies with just a single command (Pipenv rocks ?):
pipenv install requests beautifulsoup4 --three
The above command will perform the following tasks:
- Create a virtual environment (for python3).
- Install requests and beautifulsoup4.
- Create
PipfileandPipfile.lockin the same folder.
Now, activate the virtual environment:
pipenv shell
Notice the name of the folder before $ upon activation like this:
(gsoc19) $
Step 2: Scraping data for the years 2009–2015
Open any code editor and make a new python file (I will name it 2009–2015.py). The webpage contains the links for the list of organizations of each year. First, write a utility function in a separate file utils.py which will GET any webpage for us and will raise an Exception if there’s a connection error.
Now, get the link of the web page which contains the list of organizations for each year.
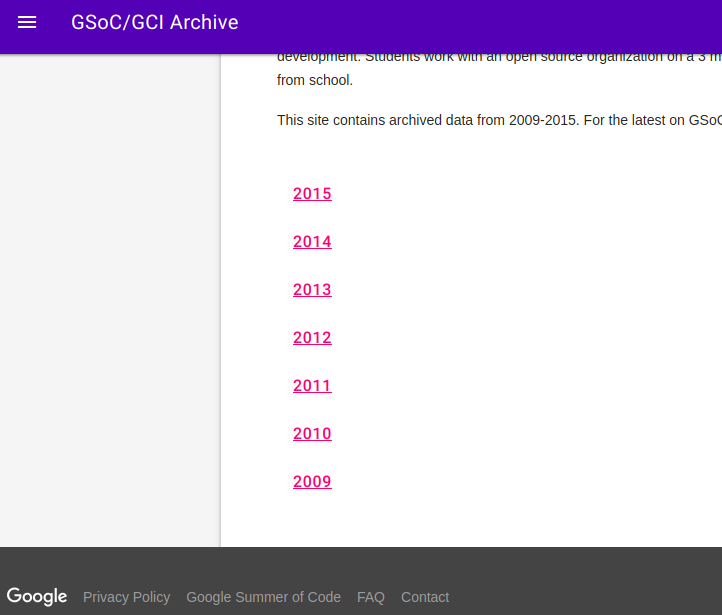 Webpage preview
Webpage preview
For that, create a function get_year_with_link. Before writing the function, we need to inspect this webpage a little. Right-click on any year and click on Inspect.
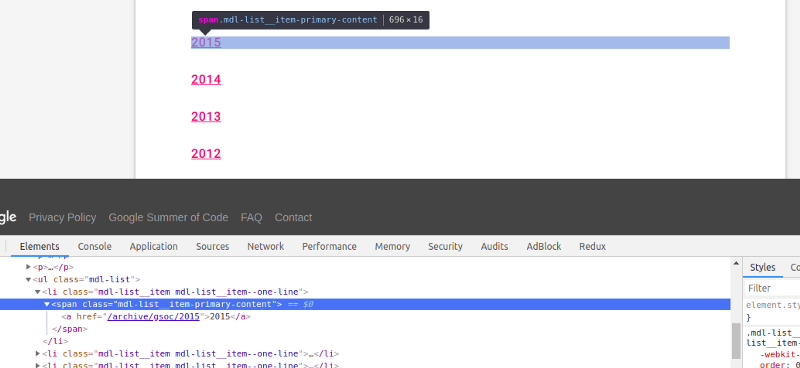
Note that there’s a <ul> tag, and inside it, there are
contains a <span> tag with class mdl-list__item-primary-content, inside of which is our link and year. Also, notice that this pattern is the same for each year. We want to grab that data.The tasks performed by this function are in this order:
- Get the
MAIN_PAGE, raise an exception if there’s a connection error. - If the response code is
200 OK, parse the fetched webpage with BeautifulSoup. And if the response code is something else, exit the program. - Find all the
<li> tags withclass mdl-list__item mdl-list__item — one-line and store the returned list in years_li. - Initialize an empty
years_dictdictionary. - Start iterating over the
years_lilist. - Get the year text (2009, 2010, 2011,…), remove all
\n, and store it in theyear. - Get the relative link of each year (/archive/gsoc/2015, /archive/gsoc/2016,…) and store it in the
relative_link. - Convert the
relative_linkinto the full link by combining it with theHOME_PAGElink and store it infull_link. - Add this data to the
year_dictdictionary with the year as key andfull_linkas its value. - Repeat this for all years.
This will give us a dictionary with years as keys and their links as values in this format:
{ ... '2009': 'https://www.google-melange.com/archive/gsoc/2009', '2010': 'https://www.google-melange.com/archive/gsoc/2010', ...}
Now, we want to visit these links and get the name of every organization with their links from these pages. Right-click on any org name and click on Inspect.
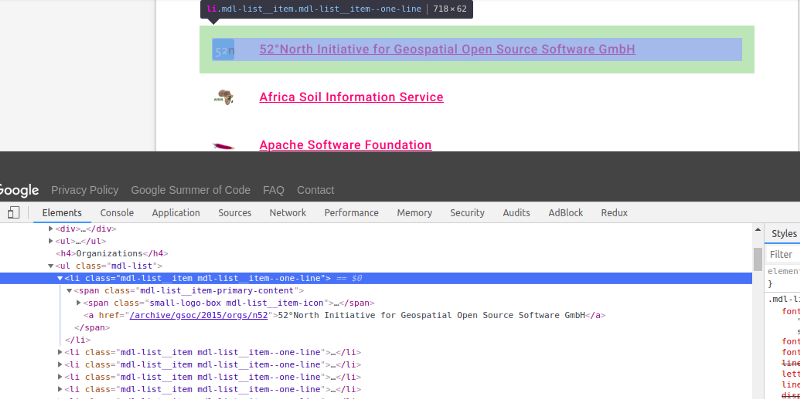
Note that there’s a <ul> tag with class mdl-list, which has
with class mdl-list__item mdl-list__item — one-line. Inside of each there’s an tag which has the link and the organization’s name. We want to grab that. For that, let’s create another function get_organizations_list_with_links, which takes the links of web pages which contains the organizations' list for each year (which we scraped in get_year_with_link).The tasks performed by this function are in this order:
- Get the org list page, (https://www.google-melange.com/archive/gsoc/2015, https://www.google-melange.com/archive/gsoc/2016, ….), raise an exception if there’s a connection error.
- If the response code is
200 OK, parse the fetched webpage with BeautifulSoup. And if the response code is something else, exit the program. - Find all the
<li> tags withclass mdl-list__item mdl-list__item — one-line and store the returned list in orgs_li. - Initialize an empty
orgs_dictdictionary. - Start iterating over the
orgs_lilist. - Get the org name, remove all
\n, and store it in theorg_name. - Get the relative link of each org (/archive/gsoc/2015/orgs/n52, /archive/gsoc/2015/orgs/beagleboard,…) and store it in the
relative_link. - Convert the
relative_linkinto the full link by combining it with theHOME_PAGElink and store it infull_link. - Add this data to the
orgs_dictwith theorg_nameas key andfull_linkas its value. - Repeat this for all the organizations for a particular year.
This will give us a dictionary with organizations’ names as keys and their links as values, like this:
{ ... 'ASCEND': 'https://www.google-melange.com/archive/gsoc/2015/orgs/ascend',
'Apache Software Foundation': 'https://www.google-melange.com/archive/gsoc/2015/orgs/apache', ...}
Moving ahead, we want to visit these links and get the title, description, and link of each project of each org for each year (?). Right-click on any project’s title and click on Inspect.
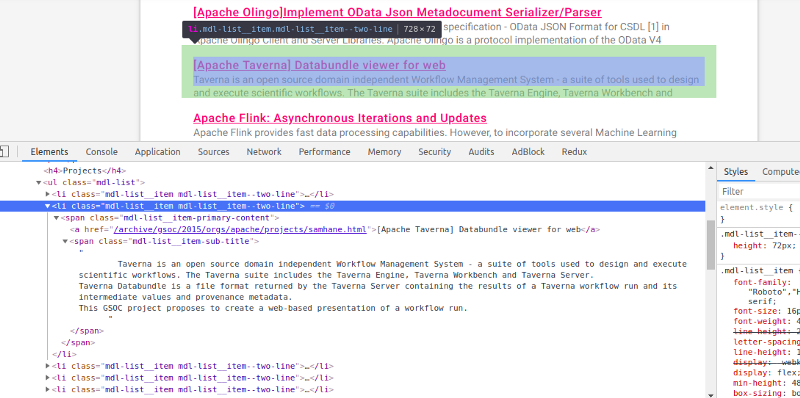
Again, the same pattern. There’s a <ul> tag with class mdl-list which contains the
with class mdl-list__item mdl-list__item — two-line, inside of which there’s an which contains an tag containing our project’s name. Also, there’s an <span> tag with class mdl-list__item-sub-title containing the project’s description. For that, create a function get_org_projects_info to get this task done.The tasks performed by this function are in this order:
- Get the org’s description page, (https://www.google-melange.com/archive/gsoc/2015/orgs/ascend, https://www.google-melange.com/archive/gsoc/2015/orgs/apache, ….), raise an exception if there’s a connection error.
- If the response code is
200 OK, parse the fetched webpage with BeautifulSoup. And if the response code is something else, exit the program. - Find all the
<li> tags with class equal to mdl-list__item mdl-list__item — two-line and store the returned list in projects_li. - Initialize an empty
projects_infolist. - Start iterating over the
projects_lilist. - Initialize an empty dictionary
proj_infoin each loop. - Get the project’s title, remove all
\n, and store it in theproj_title. - Get the relative link of each project (https://www.google-melange.com/archive/gsoc/2015/orgs/apache/projects/djkevincr.html, ….) and store it in the
proj_relative_link. - Convert the
proj_relative_linkinto the full link by combining it with theHOME_PAGElink and store it inproj_full_link. - Store the project’s title, description and link in the
proj_infodictionary and append this dictionary to theprojects_infolist.
This will give us a list containing dictionaries with the project’s data.
[ ... { 'title': 'Project Title 1', 'description': 'Project Description 1', 'link': 'http://project-1-link.com/', }, { 'title': 'Project Title 2', 'description': 'Project Description 2', 'link': 'http://project-2-link.com/', } ...]
Step 3: Implementing the main function
Let’s see the code first:
The tasks performed by this function are in this order:
- We want to have a
final_dictdictionary so that we can save it as.jsonfile. - Then, we call our function
get_year_with_link(), which will return a dictionary with years as keys and links to the list of organizations as values and store it inyear_with_link. - We iterate over the dictionary
year_with_link. - For each year, we call the function
get_organizations_list_with_links()with the link for it as the parameter, which will return a dictionary with organizations’ name as keys and links to the webpage containing information about them as values. We store the returning value infinal_dict, withyearas keys. - Then we iterate over each org for each year.
- For each org, we call the function
get_org_projects_info()with the link for the org as parameter, which will return a list of dictionaries containing each projects’ information. - We store that data in the
final_dict. - After the loop is over, we will have a
final_dictdictionary as follows:
{ "2009": { "Org 1": [ { "title": "Project - 1", "description": "Project-1-Description", "link": "http://project-1-link.com/" }, { "title": "Project - 2", "description": "Project-2-Description", "link": "http://project-2-link.com/" } ], "Org 2": [ { "title": "Project - 1", "description": "Project-1-Description", "link": "http://project-1-link.com/" }, { "title": "Project - 2", "description": "Project-2-Description", "link": "http://project-2-link.com/" } ] }, "2010": { ... }}
- Then we will save it as a
jsonfile withjson.dumps.? ?
Next Steps
Data for the years 2016–2018 can be scraped in a similar manner. And then python (or any suitable language) can be used to analyze the data. Or, a web app can be made. In fact, I have already made my version of a webapp using Django, Django REST Framework and ReactJS. Here is the link for the same: https://gsoc-data-analyzer.netlify.com/
All the code for this tutorial is available on my github.
Improvements
The running time of the script can be improved by using Multithreading. Currently, it fetches one link at one time, it can be made to fetch multiple links simultaneously.
About Me
Hi there.
I am Vaibhav Gupta, an undergrad student at Indian Institute of Information Technology, Lucknow. I love Python and JS.
See my portfolio or find me on Facebook, LinkedIn or Github.