
By Colt McAnlis
The JPG file format was one of the most technologically impressive advancements to image compression to come on the scene in 1992. Since then, it’s been a dominant force in representation of photo quality images on the internet. And for good reason. Much of the technology behind how JPG works is exceptionally complex, and requires a firm understanding of how the human eye adjusts to the perception of colors and edges.
And since I’m into that kinda stuff (and you are too, if you’re reading this), I wanted to break down how JPG encoding works, so we can better understand how to make smaller JPG files.
THE GIST
The JPG compression scheme is broken down into several phases. The image below describes them at a high level, and we’ll walk through each phase below.

Colorspace Conversion
One of the key principles of lossy data compression, is that human sensors are not as accurate as computing systems. Scientifically, the human eye only has the physical ability to distinguish about 10 million different colors. However, there’s lots of things that can influence how the human eye perceives a color; perfectly highlighted with color illusions, or the fact that this dress broke the internet. The gist is that the human eye can be nicely manipulated with respect to the colors that it perceives.
Quantization is a form of this effect in lossy image compression, however JPG takes a different approach to this : color models. A color space is a specific organization of colors, and its color model represents the mathematical formula for how those colors are represented (e.g. triples in RGB, or quadruples in CMYK).
What’s powerful about this process is that you can convert from one color model, to another , meaning you can change the mathematical representation of a given color, with a completely different set of numerical values.
For example, below is a specific color, and it’s representation in RGB and CMYK color models, they are the same color to the human eye, but can be represented with a different set of numerical values.

JPG converts from RGB to Y,Cb,Cr color model; Which comprises of Luminance (Y), Chroma Blue (Cb) and Chroma Red (Cr). The reason for this, is that psycho-visual experiments (aka how the brain works with info the eye sees) demonstrate that the human eye is more sensitive to luminance than chrominance, which means that we may neglect larger changes in the chrominance without affecting our perception of the image. As such, we can make aggressive changes to the CbCr channels before the human eye notices.

Downsampling
One of the interesting results of the YCbCr color space, is that the resulting Cb/Cr channels have less fine-grained details; they contain less information than the Y channel does.
As a result, the JPG algorithm resizes the Cb and Cr channels to be about ¼ their original size (note, there’s some nuance in how this is done that I’m not covering here…), which is called downsampling.
What’s important to note here is that downsampling is a lossy compression process ( you won’t be able to recover the exact source colors, but only a close approximation), but it’s overall impact on the visual components of the human visual cortex is minimal. Luma(Y) is where the interesting stuff is and since we’re only downsampling the CbCr channels, the impact on the visual system is low.

Image divided into 8x8 blocks of pixels
From here on out, JPG does all operations on 8x8 blocks of pixels. This is done because we generally expect that there’s not a lot of variance over the 8x8 blocks, even in very complex photos, there tends to be some self similarity in local areas; this similarity is what we’ll take advantage of during our compression later.
It’s worth noting that at this point, we’re introducing one of the first common “artifacts” of JPG encoding. “Color bleeding” is where colors along sharp edges can “bleed” onto the other side. This is because the chrominance channels, which express the color of pixels, have had each block of 4 pixels averaged into a single color, and some of these blocks cross the sharp edge.
Discrete Cosine Transform
Up to this point, things have been pretty tame. Colorspaces, downsampling, and blocking is simple stuff in the world of image compression. But now… now the real math shows up.
The key component of the DCT transform, is that it assumes that any numeric signal can be recreated using a combination of cosine functions.
For example, if we have this graph below:
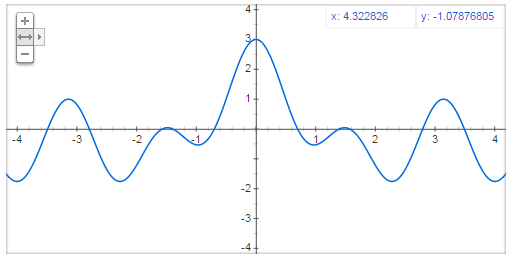
You can see that it’s actually a sum of cos(x)+cos(2x)+cos(4x)

Perhaps a better display of this, is the actual decoding of an image, given a series of cosine functions over a 2D space. To show this off, I present one of the most amazing GIFs on the internet: encoding of a 8x8 block of pixels using cosines in a 2D space:

What you’re watching here is the reconstruction of an image (leftmost panel). Each frame, we take a new basis value (right panel) and multiply it by a weight value (right panel text) to produce the contribution to the image (center panel).
As you can see, by summing various cosine values against a weight, we can reconstruct our original image (pretty well...)
This is the fundamental background for how the Discrete Cosine Transform works. The idea is that any 8x8 block can be represented as a sum of weighted cosine transforms, at various frequencies. The trick with this whole thing, is figuring out what cosine inputs to use, and how they should be weighted together.
Turns out the “what cosines to use” problem is pretty easy; After a lot of testing, a set of cosine values were chosen to produce the best results, they are our basis functions and visualized in the image below.

As far as the “how they should be weighted together” problem, simply (HA!) apply this formula.
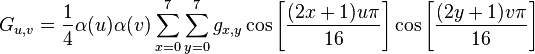
I’ll spare you what all those values mean, you can look them up on the wikipedia page.
The basic result is that for an 8x8 block of pixels in each color channel, applying the above formula and basis functions will generate a new 8x8 matrix, which represents the weights to be used during reconstruction. Here’s a graphic of the process:

This matrix, G, represents the basis weights to use to reconstruct the image (the small decimal value in the lower right side of the animation above). Basically, for each basis, we multiply it by the weight in this matrix, sum the whole thing together, and get our resulting image.
At this point, we’re no longer working in color spaces, but rather directly with the G Matrix (basis weights), all further compression is done on this matrix directly.
The problem here though, is that we’ve now converted byte-aligned integer values into real numbers. Which effectively bloats our information (moving from 1 byte to 1 float (4 bytes)). To solve this, and start producing more significant compression, we move onto the quantization phase.
Quantization
So, we don’t want to compress the floating point data. This would bloat our stream, and not be effective. To that end, we;d like to find a way to convert the weights-matrix back to values in the space of [0,255]. Directly, we could do this by finding the min/max value for the matrix (-415.38, and 77.13, respectively) and the dividing each number in this range to give us a value between [0,1] to which we multiply by 255 to get our final value.
For example : [34.12- -415.38] / [77.13 — -415.38] *255= 232
This works, but the tradeoff is a significant precision reduction. This scaling will produce an uneven distribution of values, the result of which is significant visual loss to the image.
Instead, the JPG takes a different route. Rather than using the range of values in the matrix as it’s scaling value, it instead, uses a precalculated matrix of quantization factors. These QFs don’t need to be part of the stream, rather they can be part of the codec itself.
This example shows a commonly used matrix of quantization factors , one for each basis image,
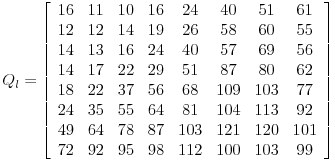
We now use the Q and G matrices, to compute our quantized DCT coefficient matrix:
For example, using the G[0,0]=−415.37 and Q[0,0]=16 values:
Resulting in a final matrix of :

Observe how much simpler the matrix becomes — it now contains a large number of entries that are small or zero, making it much easier to compress.
As a quick aside, we apply this process to Y, CbCr channels independently, and as such we need two different matrices: one for Y, and the other for the C channels:


Quantization compresses the image in two important ways: one, it limits the effective range of the weights, decreasing the number of bits required to represent them. Two, many of the weights become identical or zero, improving compression in the third step, entropy coding.
As such quantization is the primary source of JPEG artifacts. Because the images in the lower-right tend to have the largest quantization divisors, JPEG artifacts will tend to resemble combinations of these images. The matrix of quantization factors can be directly controlled by altering the JPEG’s “quality level”, which scales its values up or down (we’ll cover that in a minute)
Compression
By now, we’re back in the world of integer values, and can move forward with applying a lossless compression stage to our blocks. When looking at our transformed data though, you should notice something interesting :

As you move from the upper left to the bottom right, the frequency of zeros increases. This looks like a prime-suspect for Run Length Encoding. But row-major and column-major orders are not ideal here, since that would interleave these runs of zeros, rather than packing them all together.
Instead, we start with the top-left corner and zig-zag in a diagonal pattern across the matrix, going back and forth until we reach the lower-right corner.
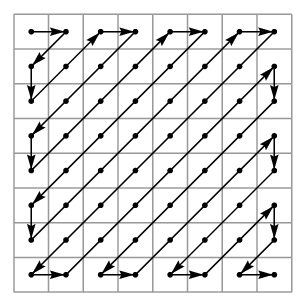
The result of our luma matrix, in this order, becomes :
−26,−3,0,−3,−2,−6,2,−4,1,−3,1,1,5,1,2,−1,1,−1,2,0,0,0,0,0,-1,-1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
Once the data is in this format, the next steps are straightforward : execute RLE on the sequence, and then apply some statistical encoder (Huffman / Arithmetic / ANS) on the results.
And Boom. Your block is now JPG encoded.
Understanding the quality parameter
Now that you understand how JPG files are actually created, it’s worth revisiting the concept of the quality parameter that you normally see when exporting JPG images from Photoshop (or whatnot).
This parameter, which we’ll call q, is an integer from 1 to 100. You should think of q as being a measure of the quality of the image: higher values of q correspond to higher quality images and larger file sizes.
This quality value is used during the quantization phase, to scale the quantization factors appropriately. So that per basis weight, the quantization step now resembles round(Gi,k / alpha*Qi,k)
Where the alpha symbol is created as a result of the quality parameter.
When either alpha or Q[x,y] is increased (remember that large values of alpha correspond to smaller values of the quality parameter q), more information is lost, and the file size decreases.
As such, if you want a smaller file, at the cost of more visual artifacts, you can set a lower quality value during the export phase.

Notice above, in the lowest-quality image, how we see clear signs of the blocking stage, as well as the quantization stage.
Probably most important, is that the quality parameter varies depending on the image. Since each image is unique, and presents different types of visual artifacts, the Q value will be unique as well.
Conclusion
Once you understand how the JPG algorithm works, a few things become apparent:
- Getting the quality value right, per image, is important to find the tradeoff between visual quality and file size.
- Since this process is block-based, artifacts will tend to occur in blockyness, or “ringing”
- Since processed blocks don’t intermingle with each other, JPG generally ignores the opportunity to compress large swaths of similar blocks together. Addressing that concern is something the WebP format is good at doing.
And if you want to play around with all this by yourself, all this madness can be boiled down to a ~1000 line file.
HEY!
Want to know how to make your JPG files smaller?
Want to know how PNG files work, or how to make them smaller?
Want more data compression goodness? Buy my book!