
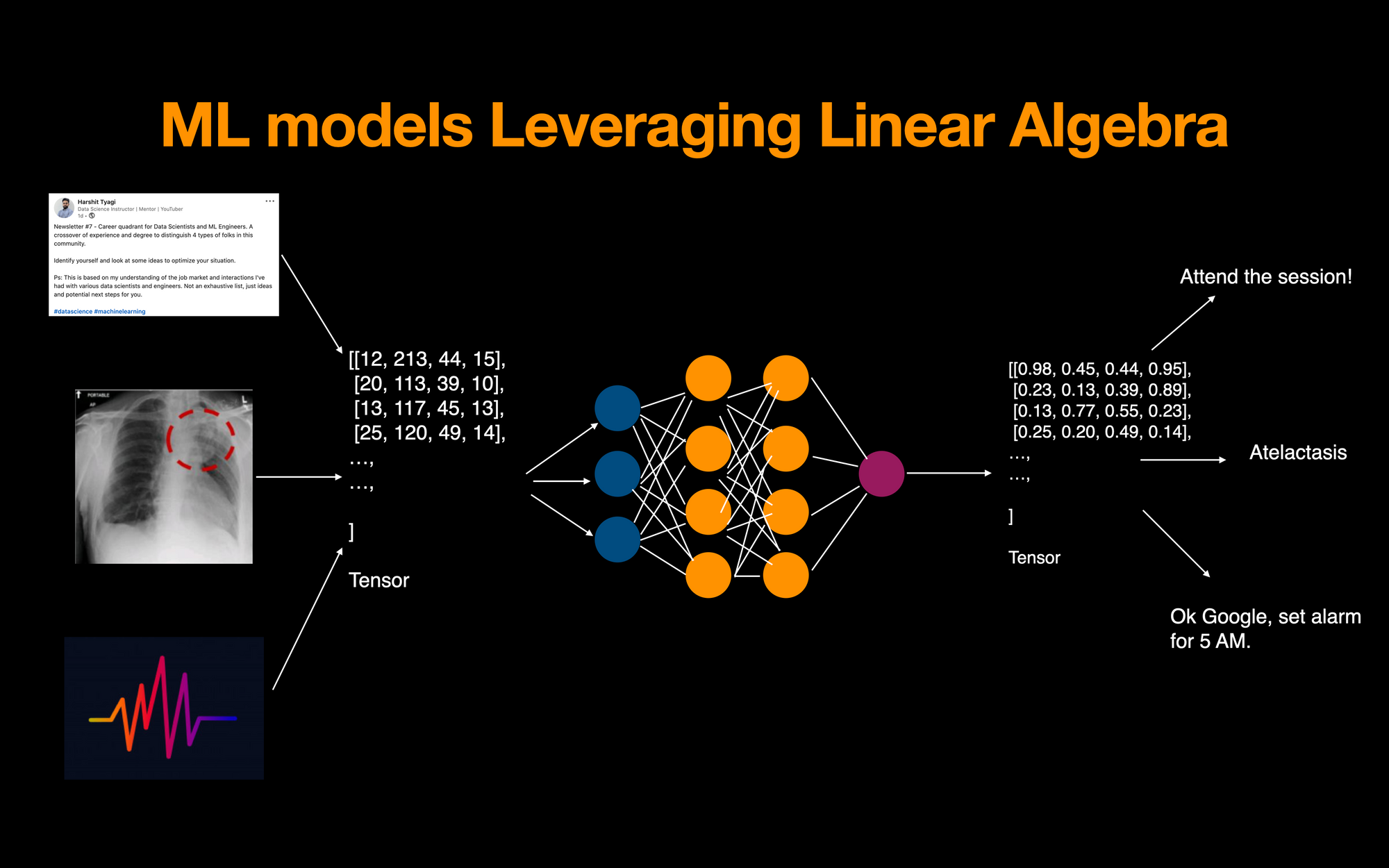
Machines or computers only understand numbers. And these numbers need to be represented and processed in a way that lets machines solve problems by learning from the data instead of learning from predefined instructions (as in the case of programming).
All types of programming use mathematics at some level. Machine learning involves programming data to learn the function that best describes the data.
The problem (or process) of finding the best parameters of a function using data is called model training in ML.
Therefore, in a nutshell, machine learning is programming to optimize for the best possible solution – and we need math to understand how that problem is solved.
The first step towards learning Math for ML is to learn linear algebra.
Linear Algebra is the mathematical foundation that solves the problem of representing data as well as computations in machine learning models.
It is the math of arrays — technically referred to as vectors, matrices and tensors.
Common Areas of Application — Linear Algebra in Action

Source: [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
In the ML context, all major phases of developing a model have linear algebra running behind the scenes.
Important areas of application that are enabled by linear algebra are:
data and learned model representation
word embeddings
dimensionality reduction
Data Representation
**** The fuel of ML models, that is data, needs to be converted into arrays before you can feed it into your models. The computations performed on these arrays include operations like matrix multiplication (dot product). This further returns the output that is also represented as a transformed matrix/tensor of numbers.
Word embeddings
Don’t worry about the terminology here – it is just about representing large-dimensional data (think of a huge number of variables in your data) with a smaller dimensional vector.
Natural Language Processing (NLP) deals with textual data. Dealing with text means comprehending the meaning of a large corpus of words. Each word represents a different meaning which might be similar to another word. Vector embeddings in linear algebra allow us to represent these words more efficiently.
Eigenvectors (SVD)
Finally, concepts like eigenvectors allow us to reduce the number of features or dimensions of the data while keeping the essence of all of them using something called principal component analysis.
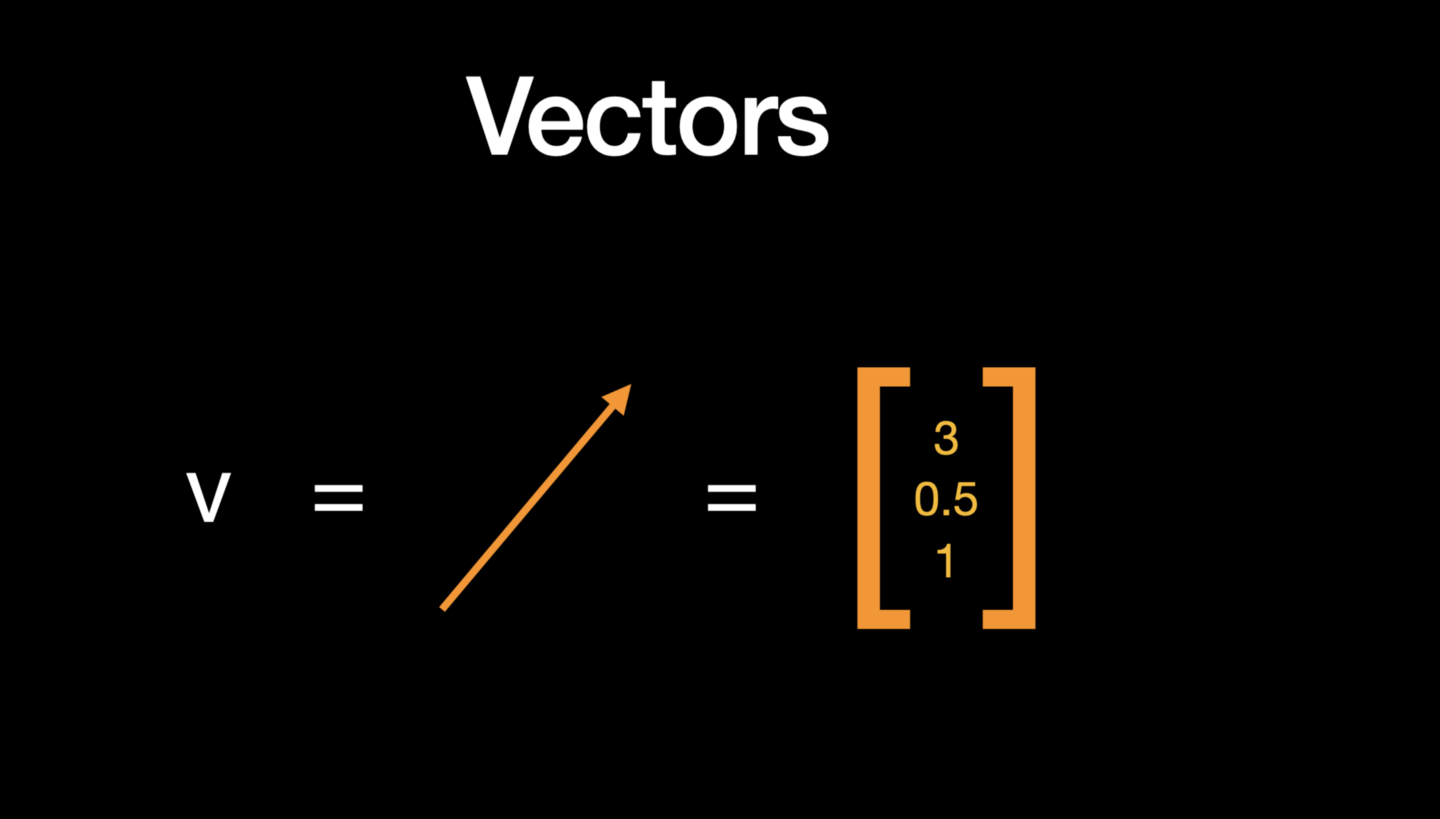
From Data to Vectors
Source: [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
Linear algebra basically deals with vectors and matrices (different shapes of arrays) and operations on these arrays. In NumPy, vectors are basically a 1-dimensional array of numbers but geometrically, they have both magnitude and direction.
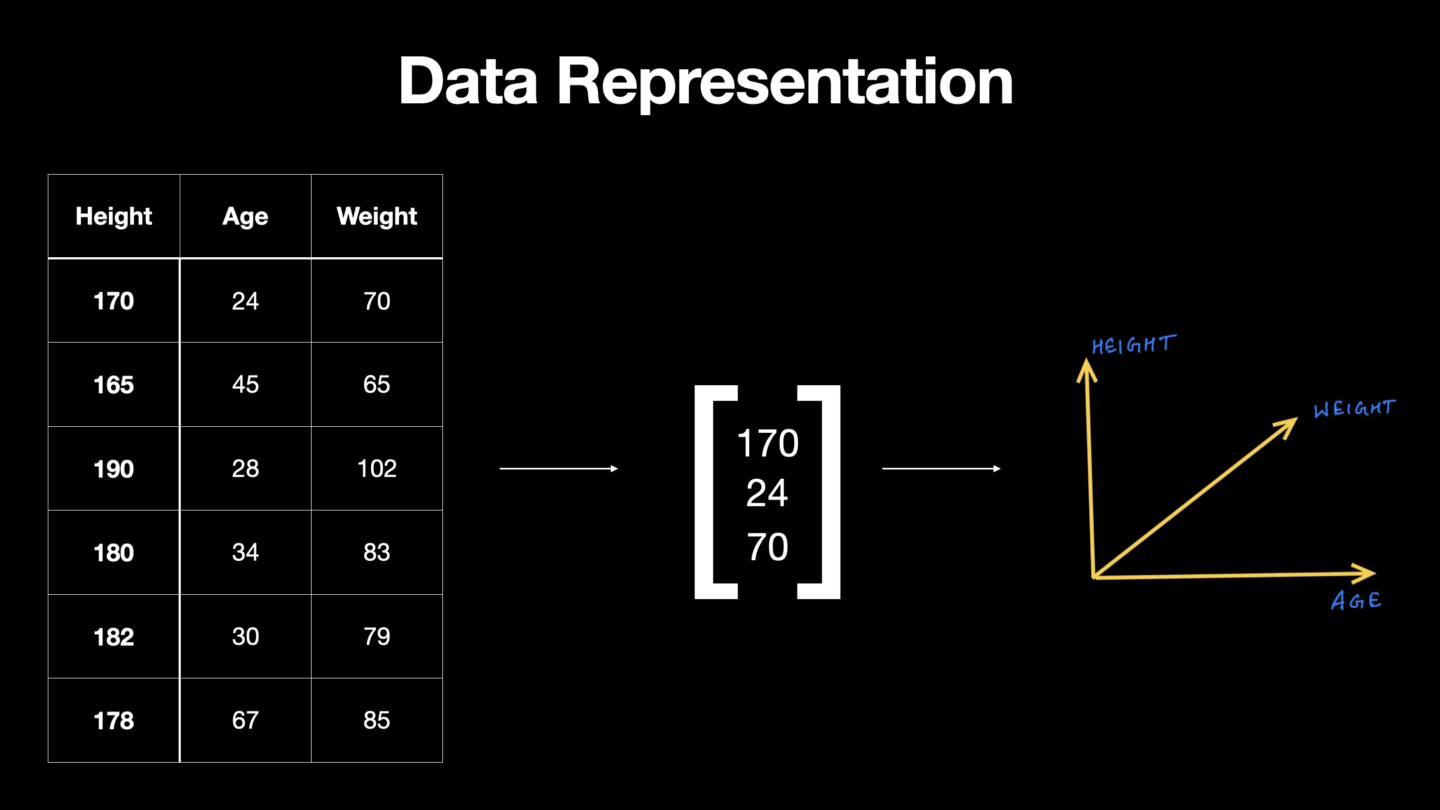
Source: [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
Our data can be represented using a vector. In the figure above, one row in this data is represented by a feature vector which has 3 elements or components representing 3 different dimensions. N-entries in a vector makes it n-dimensional vector space and in this case, we can see 3-dimensions.
Deep Learning — Tensors Flowing Through a Neural Network
We can see linear algebra in action across all the major applications today. Examples include sentiment analysis on a LinkedIn or a Twitter post (embeddings), detecting a type of lung infection from X-ray images (computer vision), or any speech to text bot (NLP).
All of these data types are represented by numbers in tensors. We run vectorized operations to learn patterns from them using a neural network. It then outputs a processed tensor which in turn is decoded to produce the final inference of the model.
Each phase performs mathematical operations on those data arrays.
Dimensionality Reduction — Vector Space Transformation

Source: [https://www.wiplane.com/p/foundations-for-data-science-ml](https://www.wiplane.com/p/foundations-for-data-science-ml" rel="nofollow noopener noopener noopener noopener)
When it comes to embeddings, you can basically think of an n-dimensional vector being replaced with another vector that belongs to a lower-dimensional space. This is more meaningful and it's the one that overcomes computational complexities.
For example, here is a 3-dimensional vector that is replaced by a 2-dimensional space. But you can extrapolate it to a real-world scenario where you have a very large number dimensions.
Reducing dimensions doesn’t mean dropping features from the data. Instead, it's about finding new features that are linear functions of the original features and preserving the variance of the original features.
Finding these new variables (features) translates to finding the principal components (PCs). This then converges to solving eigenvectors and eigenvalues problems.
Recommendation Engines — Making use of embeddings
You can think of Embedding as a 2D plane being embedded in a 3D space and that’s where this term comes from. You can think of the ground you are standing on as a 2D plane that is embedded into this space in which you live.
Just to give you a real-world use case to relate to all of this discussion on vector embeddings, all applications that are giving you personalized recommendations are using vector embedding in some form.

For example, the above is a graphic from Google’s course on recommendation systems where we are given this data on different users and their preferred movies. Some users are kids and others are adults, some movies were are all-time classics while others are more artistic. Some movies are targeted towards a younger audience while movies like memento are preferred by adults.
Now, we not only need to represent this information in numbers but also need to find new smaller dimensional vector representations that capture all these features well.

A very quick way to understand how we can pull off this task is by understanding something called Matrix Factorization which allows us to break a large matrix down into smaller matrices.
Ignore the numbers and colors for now and just try to understand how we have broken down one big matrix into two smaller ones.
For example, here this matrix of 4X5, 4 rows, and 5 features, was broken down into two matrices, one that's 4X2 and the other that's 2X5. We basically have new smaller dimensional vectors for users and movies.
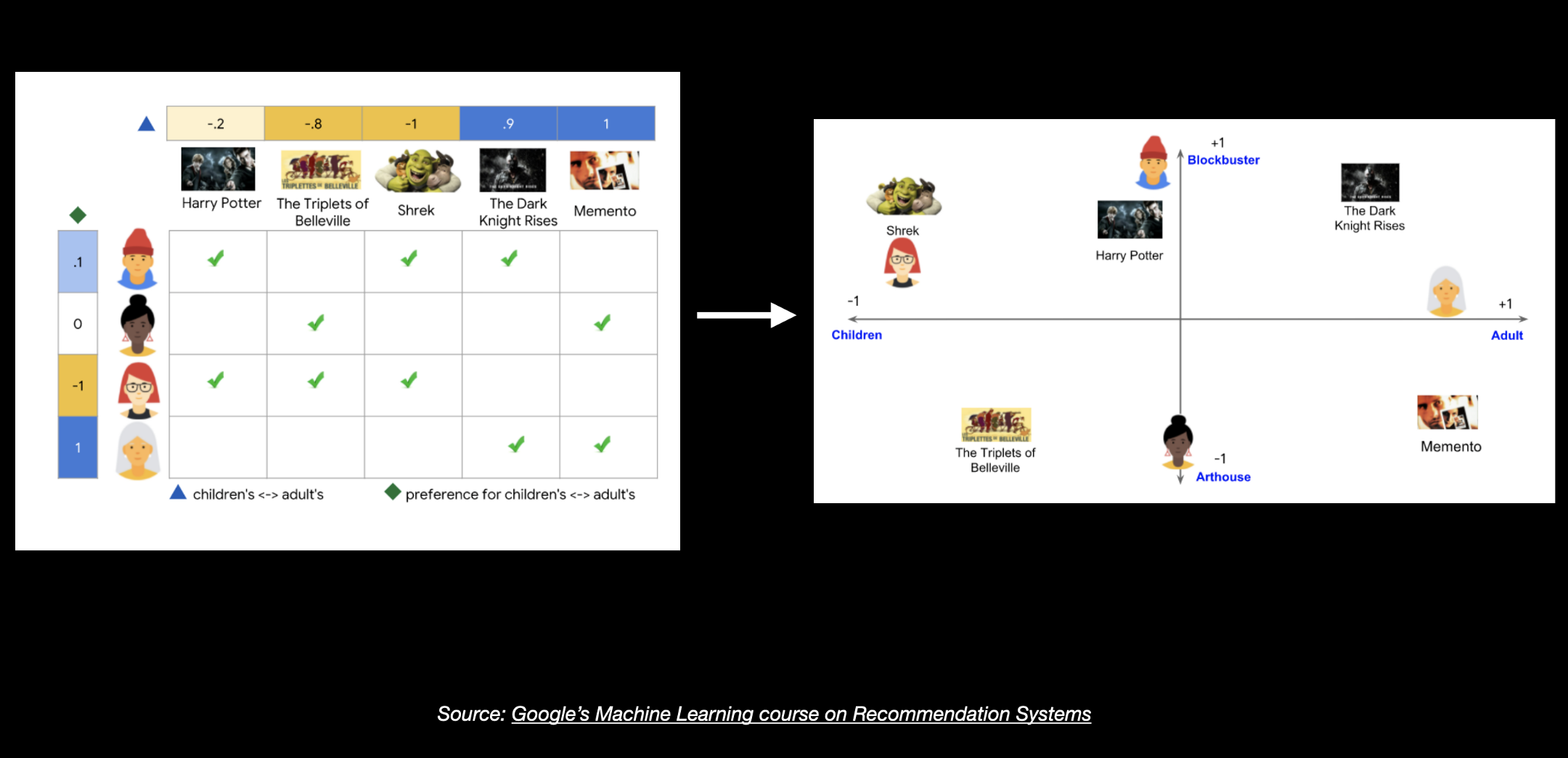
And this allows us to plot this on a 2D vector space. Here you’ll see that user #1 and the movie Harry Potter are closer and user #3 and the movie Shrek are closer.
The concept of a dot product (matrix multiplication) of vectors tells us more about the similarity of two vectors. And it has applications in correlation/covariance calculation, linear regression, logistic regression, PCA, convolutions, PageRank and numerous other algorithms.
Industries where Linear Algebra is used heavily
By now, I hope you are convinced that Linear algebra is driving the ML initiatives in a host of areas today. If not, here is a list to name a few:
Statistics
Chemical Physics
Genomics
Word Embeddings — neural networks/deep learning
Robotics
Image Processing
Quantum Physics
How much Linear Algebra should you know to get started with ML / DL?
Now, the important question is how you can learn to program these concepts of linear algebra. The answer is you don’t have to reinvent the wheel, you just need to understand the basics of vector algebra computationally and you then learn to program those concepts using NumPy.
NumPy is a scientific computation package that gives us access to all the underlying concepts of linear algebra. It is fast as it runs compiled C code and it has a large number of mathematical and scientific functions that we can use.
Recommended resources
Playlist on Linear Algebra by 3Blue1Brown **** — very engaging visualizations that explains the essence of linear algebra and its applications. Might be a little too hard for beginners.
Book on Deep Learning by Ian Goodfellow & Yoshua Bengio — a fantastic resource for learning ML and applied math. Give it a read, few folks may find it too technical and notation-heavy, to begin with.
Foundations of Data Science & ML — I have created a course that gives you enough understanding of Programming, Math (Basic Algebra, Linear Algebra & Calculus) and Statistics. A complete package for first steps to learning DS/ML.
👉 You can use the code **FREECODECAMP10** to get 10% off.
Check out the course outline here: