
By Mariya Yao
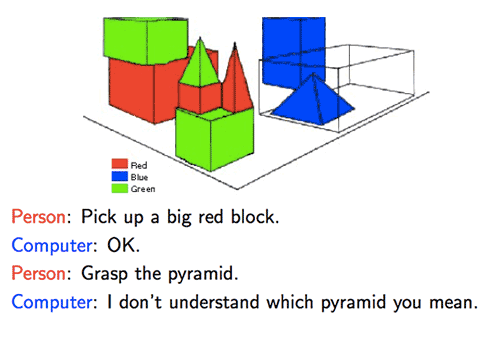
In 1971, Terry Winograd wrote the SHRDLU program while completing his PhD at MIT.
SHRDLU features a world of toy blocks where the computer translates human commands into physical actions, such as “move the red pyramid next to the blue cube.”
To succeed at such tasks, the computer must build up semantic knowledge iteratively, a process Winograd discovered as brittle and limited.
The rise of chatbots and voice activated technologies has renewed fervor in natural language processing (NLP) and natural language understanding (NLU) techniques that can produce satisfying human-computer dialogs.
Unfortunately, academic breakthroughs have not yet translated into improved user experience. Gizmodo writer Darren Orf declared Messenger chatbots “frustrating and useless” and Facebook admitted a 70% failure rate for their highly anticipated conversational assistant, “M.”
Nevertheless, researchers forge ahead with new plans of attack, occasionally revisiting the same tactics and principles Winograd tried in the 70s.
OpenAI recently leveraged reinforcement learning to teach to agents to design their own language by “dropping them into a set of simple worlds, giving them the ability to communicate, and then giving them goals that can be best achieved by communicating with other agents.” The agents independently developed a simple “grounded” language.
MIT Media Lab presents this satisfying clarification on what “grounded” means in the context of language:
“Language is grounded in experience. Unlike dictionaries which define words in terms of other words, humans understand many basic words in terms of associations with sensory-motor experiences. People must interact physically with their world to grasp the essence of words like “red,” “heavy,” and “above.” Abstract words are acquired only in relation to more concretely grounded terms. Grounding is thus a fundamental aspect of spoken language, which enables humans to acquire and to use words and sentences in context.”
The antithesis of grounded language is inferred language. Inferred language derives meaning from words themselves rather than what they represent.
When trained only on large corpuses of text — but not on real-world representations — statistical methods for NLP and NLU lack true understanding of what words mean.
OpenAI points out that such approaches share the weaknesses revealed by John Searle’s famous Chinese Room thought experiment. Equipped with a universal dictionary to map all possible Chinese input sentences to Chinese output sentences, anyone can perform a brute force lookup and produce conversationally acceptable answers without understanding what they’re actually saying.
Why Is Language So Complex?
Percy Liang, a Stanford CS professor and NLP expert, breaks down the various approaches to NLP / NLU into four distinct categories:
- Distributional
- Frame-based
- Model-theoretical
- Interactive learning
First, a brief linguistics lesson before we continue on to define and describe those categories.
There are three levels of linguistic analysis:
- Syntax — what is grammatically correct?
- Semantics — what is the meaning?
- Pragmatics — what is the purpose or goal?
Drawing upon a programming analogy, Liang likens successful syntax to “no compiler errors,” semantics to “no implementation bugs,” and pragmatics to “implemented the right algorithm.”
He highlights that sentences can have the same semantics, yet different syntax, such as “3+2” versus “2+3”. Similarly, they can have identical syntax yet different syntax, for example 3/2 is interpreted differently in Python 2.7 vs Python 3.
Ultimately, pragmatics is key, since language is created from the need to motivate an action in the world. If you implement a complex neural network to model a simple coin flip, you have excellent semantics but poor pragmatics since there are a plethora of easier and more efficient approaches to solve the same problem.
Plenty of other linguistics terms exist which demonstrate the complexity of language. Words take on different meanings when combined with other words, such as “light” versus “light bulb” (that is, multi-word expressions), or used in various sentences such as “I stepped into the light” and “the suitcase was light” (polysemy).
Hyponymy shows how a specific instance is related to a general term (a cat is a mammal) and meronymy denotes that one term is a part of another (a cat has a tail). Such relationships must be understood to perform the task of textual entailment, recognizing when one sentence is logically entailed in another. “You’re reading this article” entails the sentence “you can read.”
Aside from complex lexical relationships, your sentences also involve beliefs, conversational implicatures, and presuppositions. Liang provides excellent examples of each. Superman and Clark Kent are the same person, but Lois Lane believes Superman is a hero while Clark Kent is not.
If you say “Where is the roast beef?” and your conversation partner replies “Well, the dog looks happy”, the conversational implicature is the dog ate the roast beef.
Presuppositions are background assumptions that are true regardless of the truth value of a sentence. “I have stopped eating meat” has the presupposition “I once ate meat” even if you inverted the sentence to “I have not stopped eating meat.”
Adding to the complexity are vagueness, ambiguity, and uncertainty. Uncertainty is when you see a word you don’t know and must guess at the meaning.
If you’re stalking a crush on Facebook and their relationship status says “It’s Complicated”, you already understand vagueness. Richard Socher, Chief Scientist at Salesforce, gave an excellent example of ambiguity at a recent AI conference: “The question ‘can I cut you?’ means very different things if I’m standing next to you in line or if I am holding a knife.”
Now that you’re more enlightened about the myriad challenges of language, let’s return to Liang’s four categories of approaches to semantic analysis in NLP and NLU.
#1: Distributional Approaches
Distributional approaches include the large-scale statistical tactics of machine learning and deep learning. These methods typically turn content into word vectors for mathematical analysis and perform quite well at tasks such as part-of-speech tagging (is this a noun or a verb?), dependency parsing (does this part of a sentence modify another part?), and semantic relatedness (are these different words used in similar ways?). These NLP tasks don’t rely on understanding the meaning of words, but rather on the relationship between words themselves.
Such systems are broad, flexible, and scalable. They can be applied widely to different types of text without the need for hand-engineered features or expert-encoded domain knowledge. The downside is that they lack true understanding of real-world semantics and pragmatics. Comparing words to other words, or words to sentences, or sentences to sentences can all result in different outcomes.
Semantic similarity, for example, does not mean synonymy. A nearest neighbor calculation may even deem antonyms as related:

Advanced modern neural network models, such as the end-to-end attentional memory networks pioneered by Facebook or the joint multi-task model invented by Salesforce can handle simple question and answering tasks, but are still in early pilot stages for consumer and enterprise use cases.
Thus far, Facebook has only publicly shown that a neural network trained on an absurdly simplified version of The Lord of The Rings can figure out where the elusive One Ring is located.

Although distributional methods achieve breadth, they cannot handle depth. Complex and nuanced questions that rely linguistic sophistication and contextual world knowledge have yet to be answered satisfactorily.
#2: Frame-Based Approach
“A frame is a data-structure for representing a stereotyped situation,” explains Marvin Minsky in his seminal 1974 paper called “A Framework For Representing Knowledge.” Think of frames as a canonical representation for which specifics can be interchanged.
Liang provides the example of a commercial transaction as a frame. In such situations, you typically have a seller, a buyers, goods being exchanged, and an exchange price.
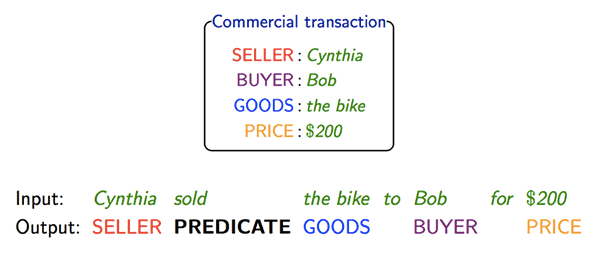
Sentences that are syntactically different but semantically identical — such as “Cynthia sold Bob the bike for $200” and “Bob bought the bike for $200 from Cynthia” — can be fit into the same frame. Parsing then entails first identifying the frame being used, then populating the specific frame parameters — i.e. Cynthia, $200.
The obvious downside of frames is that they require supervision. In some domains, an expert must create them, which limits the scope of frame-based approaches. Frames are also necessarily incomplete. Sentences such as “Cynthia visited the bike shop yesterday” and “Cynthia bought the cheapest bike” cannot be adequately analyzed with the frame we defined above.
#3: Model-Theoretical Approach
The third category of semantic analysis falls under the model-theoretical approach. To understand this approach, we’ll introduce two important linguistic concepts: “model theory” and “compositionality”.
Model theory refers to the idea that sentences refer to the world, as in the case with grounded language (i.e. the block is blue). In compositionality, meanings of the parts of a sentence can be combined to deduce the whole meaning.
Liang compares this approach to turning language into computer programs. To determine the answer to the query “what is the largest city in Europe by population”, you first have to identify the concepts of “city” and “Europe” and funnel down your search space to cities contained in Europe. Then you would need to sort the population numbers for each city you’ve shortlisted so far and return the maximum of this value.

To execute the sentence “Remind me to buy milk after my last meeting on Monday” requires similar composition breakdown and recombination.

Models vary from needing heavy-handed supervision by experts to light supervision from average humans on Mechanical Turk. The advantages of model-based methods include full-world representation, rich semantics, and end-to-end processing, which enable such approaches to answer difficult and nuanced search queries.
The major con is that the applications are heavily limited in scope due to the need for hand-engineered features. Applications of model-theoretic approaches to NLU generally start from the easiest, most contained use cases and advance from there.
The holy grail of NLU is both breadth and depth, but in practice you need to trade off between them. Distributional methods have scale and breadth, but shallow understanding. Model-theoretical methods are labor-intensive and narrow in scope. Frame-based methods lie in between.
#4: Interactive Learning Approaches
Paul Grice, a British philosopher of language, described language as a cooperative game between speaker and listener. Liang is inclined to agree. He believes that a viable approach to tackling both breadth and depth in language learning is to employ interactive, interactive environments where humans teach computers gradually. In such approaches, the pragmatic needs of language inform the development.
To test this theory, Liang developed SHRDLRN as a modern-day version of Winograd’s SHRDLU. In this interactive language game, a human must instruct a computer to move blocks from a starting orientation to an end orientation. The challenge is that the computer starts with no concept of language. Step by step, the human says a sentence and then visually indicates to the computer what the result of the execution should look like.
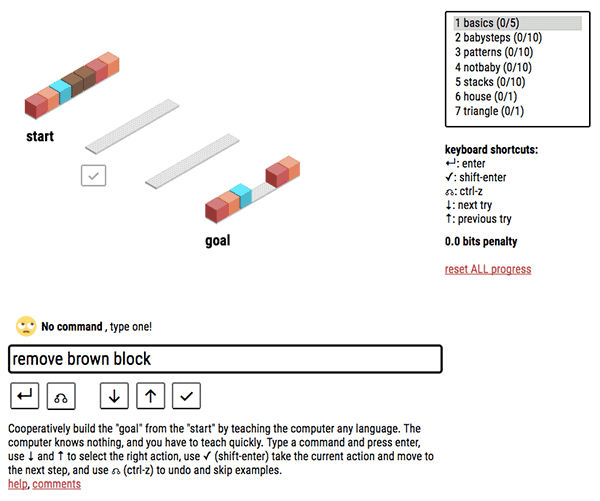
If a human plays well, he or she adopts consistent language that enables the computer to rapidly build a model of the game environment and map words to colors or positions. The surprising result is that any language will do, even individually invented shorthand notation, as long as you are consistent.

The worst players who take the longest to train the computer often employ inconsistent terminology or illogical steps.

Liang’s bet is that such approaches would enable computers to solve NLP and NLU problems end-to-end without explicit models. “Language is intrinsically interactive,” he adds. “How do we represent knowledge, context, memory? Maybe we shouldn’t be focused on creating better models, but rather better environments for interactive learning.”
Language is both logical and emotional. We use words to describe both math and poetry. Accommodating the wide range of our expressions in NLP and NLU applications may entail combining the approaches outlined above, ranging from the distributional / breadth-focused methods to model-based systems to interactive learning environments.
We may also need to re-think our approaches entirely, using interactive human-computer based cooperative learning rather than researcher-driven models.
If you have a spare hour and a half, I highly recommend you watch Percy Liang’s entire talk which this summary article was based on:
A special thanks to Melissa Fabros for recommending Percy’s talk, Matthew Kleinsmith for highlighting the MIT Media Lab definition of “grounded” language, and Jeremy Howard and Rachel Thomas of fast.ai for facilitating our connection and conversation.
If you enjoyed my article, join the TOPBOTS community and get the best bot news and exclusive industry content.