
By Preethi Kasireddy
If you’re just getting into web development, chances are you think you know how the web works — at least on a basic level.
…But then you try to explain how a basic website works and draw a blank. What does an IP address mean again? How does the “client-server” model work, exactly?
Development frameworks are powerful these days. So powerful, in fact, that it’s easy for us newcomers to lose track of the basics of how the web, y’know, works.
I know I did. No shame admitting it: the web is complicated, and it’s only when you start engineering in the backend that you realize how important those fundamentals are. (If you want to make web apps that actually work, anyway.)
So I’ve taken it upon myself to write a four-part field guide to the intimidating basics that everybody should have a handle on, whether you’re just diving into a career in web development or just interested in learning:
Part 1: How the web works
Part 2: Structure of a Web Application
Part 3: HTTP and REST
Part 4: Code examples of client-server interactions
A basic web search
Let’s start somewhere we’ve all been before: Type “www.github.com” into your browser’s address bar and see the page load.
Simple as that transaction might seem, there’s a ton of magic happening under the hood. Let’s dive right into it.
Defining parts of the web
Understanding the web is intimidating because there’s a lot of jargon. Unfortunately, some of that jargon is critical to understanding the rest of this post.
Here are the most important terms to understand if you want to grok the secrets of the World Wide Web:
Client: An application, such as Chrome or Firefox, that runs on a computer and is connected to the internet. Its primary role is to take user interactions and translate them into requests to another computer called a web server. Although we typically use a browser to access the web, you can think of your whole computer as the “Client” piece of the client-server model. Every client computer has a unique address called an IP address that other computers can use to identify it.
Server: A machine that is connected to the internet and also has an IP address. A server waits for requests from other machines (e.g. a client) and responds to them. Unlike your computer (i.e. the client) which also has an IP address, the server has special server software installed and running which tells it how to respond to incoming requests from your browser. The primary function of a web server is to store, process and deliver web pages to clients. There are many types of servers, including web servers, database servers, file servers, application servers, and more. (In this post, we’re talking about web servers.)
IP address: Internet Protocol Address. A numerical identifier for a device (computer, server, printer, router, etc.) on a TCP/IP network. Every computer on the internet has an IP address that it uses to identify and communicate with other computers. IP addresses have four sets of numbers separated by decimal points (e.g. 244.155.65.2). This is called the “logical address”. In order to locate a device in the network, the logical IP address is converted to a physical address by the TCP/IP protocol software. This physical address (i.e. MAC address) is built into your hardware.
ISP: Internet Service Provider. ISP is the middle man between the client and servers. For the typical homeowner, the ISP is usually a “cable company.” When your browser gets a request from you to go to www.github.com, it doesn’t know where to look for www.github.com. So it’s the ISP’s job to do a DNS (Domain Name System) lookup to ask what IP address the site you’re trying to visit is configured to.
DNS: Domain Name System. A distributed database which keeps track of computer’s domain names and their corresponding IP addresses on the Internet. Don’t worry about how a “distributed database” works for now: just know that DNS exists so users can enter www.github.com instead of an IP address.
Domain Name: Used to identify one or more IP addresses. Users use the domain name (e.g. www.github.com)) to get to a website on the internet. When you type the domain name into your browser, the DNS uses it to look up the corresponding IP address for that given website.
TCP/IP: Transmission Control Protocol/Internet Protocol. The most widely used communications protocol. A “protocol” is simply a standard set of rules for doing something. TCP/IP is used as a standard for transmitting data over networks.
Port Number: A 16-bit integer that identifies a specific port on a server and is always associated with an IP address. It serves as a way to identify a specific process on a server that network requests could be forwarded to.
Host: A computer connected to a network — it can be a client, server or any other type of device. Each host has a unique IP address. For a website like www.google.com, a host could be the web server that serves the pages for the website. There’s often some mix up between a host and server but note they are two different things. Servers are a type of host — they are a specific machine. On the other hand, a host could refer to an entire organization that provides a hosting service to maintain multiple web servers. You can run a server from a host in that sense.
HTTP: Hyper-text Transfer Protocol. The protocol that web browsers and web servers use to communicate with each other over the Internet.
URL: Uniform Resource Locators. URLs identify a particular web resource. A simple example is https://github.com/someone. The URL specifies the protocol (“https”), host name (github.com) and file name (someone’s profile page). A user can obtained the web resource identified by this URL via HTTP from a network host whose domain name is github.com. (tongue twister much?!)
The journey from code to webpage
Alright, now that we have the essential definitions out of the way, let’s walk through that Github search to see how we go from a URL typed into an address bar to a running web page:
1) You type a URL into your browser
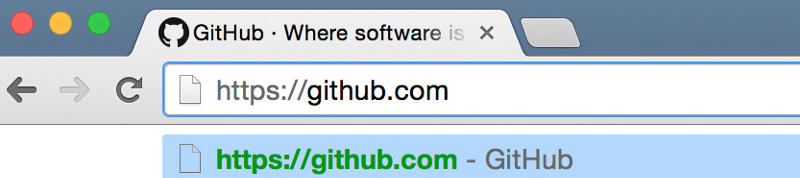
2) The browser parses the information contained in the URL. This includes the protocol (“https”), the domain name (“github.com”) and the resource (“/”). In this case, there isn’t anything after the “.com” to indicate a specific resource, so the browser knows to retrieve just the main (index) page

3) The browser communicates with your ISP to do a DNS lookup of the IP address for the web server that hosts www.github.com. The DNS service will first contact a Root Name Server, which looks at https://www.github.com and replies with the IP address of a name server for the “.com” top-level domain. This address is sent back to your DNS service. The DNS service does another outreach to the “.com” name server and asks it for the address of https://www.github.com.
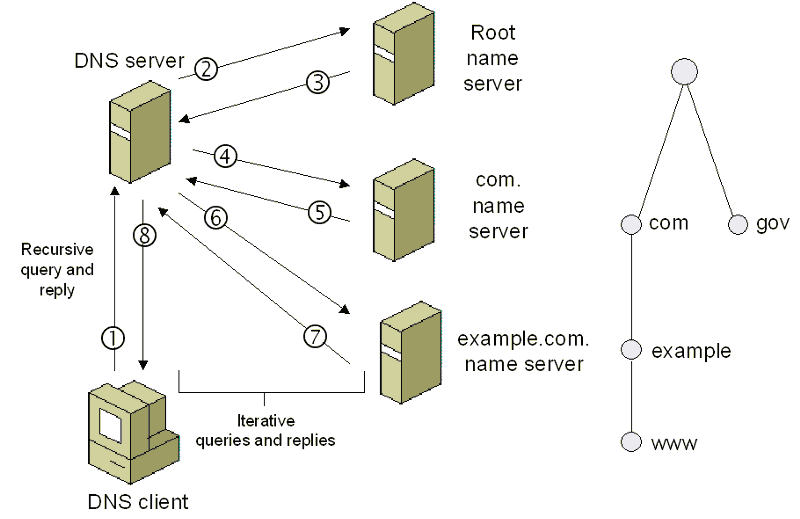
source: https://technet.microsoft.com/en-us/library/bb962069.aspx
4) Once the ISP receives the IP address of the destination server, it sends it to your web browser

6) Your web browser sends an HTTP request to the web server for the main HTML web page of www.github.com.
 GET request from Client
GET request from Client
7) The web server receives the request and looks for that HTML page. If the page exists, the web server prepares the response and sends it back to your browser. If the server cannot find the requested page, it will send an HTTP 404 error message, which stands for “Page Not Found”.
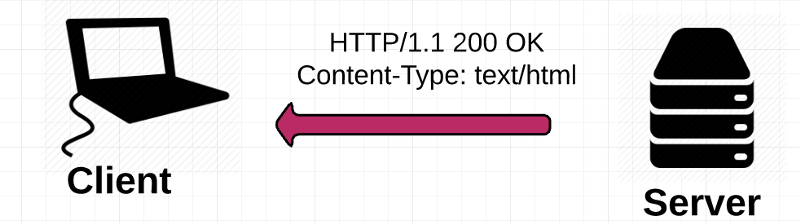 Server response
Server response
8) Your web browser takes the HTML page it receives and then parses through it doing a full head to toe scan looking for other assets that are listed, such as images, CSS files, JavaScript files, etc.
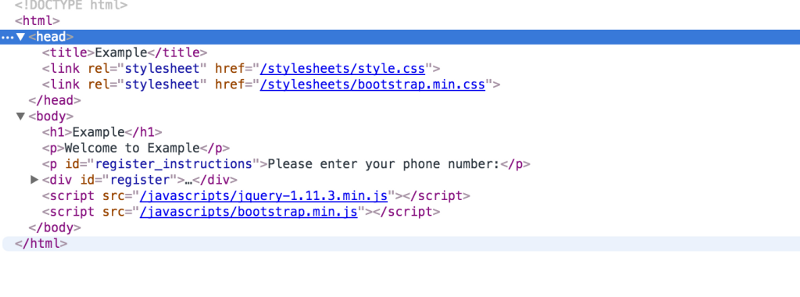 index.html page
index.html page
9) For each asset listed, the browser repeats the entire process above, making additional HTTP requests to the server for each resource.
10) Once the browser has finished loading all other assets that were listed in the HTML page, the page will finally be loaded in the browser window and the connection will be closed
 Github
Github
Crossing the Internet abyss
One thing worth noting is how information gets transmitted when you make a request for information. When you make a request, that information is broken up into many tiny chunks called packets. Each packet is tagged with a TCP header, which include the source and destination port numbers, and an IP header which includes the source and destination IP addresses to give it its identity. The packet is then transmitted through ethernet, WiFi or Cellular network and is allowed to travel on any route and take as many hops as it needs to get to the final destination.
(We don’t actually care how the packets get there — all that matters is that they get to the destination safe and sound!) Once the packets reach the destination, they are reassembled again and delivered as one piece.
So how do all the packets know how to get to their destination without getting lost?
The answer is TCP/IP.
TCP/IP is a two-part system, functioning as the Internet’s fundamental “control system”. IP stands for Internet Protocol; its job is to send and route packets to other computers using the IP headers (i.e. the IP addresses) on each packet. The second part, Transmission Control Protocol (TCP), is responsible for breaking the message or file into smaller packets, routing packets to the correct application on the destination computer using the TCP headers, resending the packets if they get lost on the way, and reassembling the packets in the correct order once they’ve reached the other end.
Painting the final picture
But wait — the job isn’t done yet! Now that your browser has the resources comprising the website (HTML, CSS, JavaScript, images, etc), it has to go through several steps to present the resources to you as a human-readable webpage.
Your browser has a rendering engine that’s responsible for displaying the content. The rendering engine receives the content of the resources in small chunks. Then there’s an HTML parsing algorithm that tells the browser how to parse the resources.
Once parsed, it generates a tree structure of the DOM elements. DOM stands for Document Object Model and it is a convention for how to represent objects located in an HTML document. These objects — or “nodes” — of every document can be manipulated using scripting languages like JavaScript.
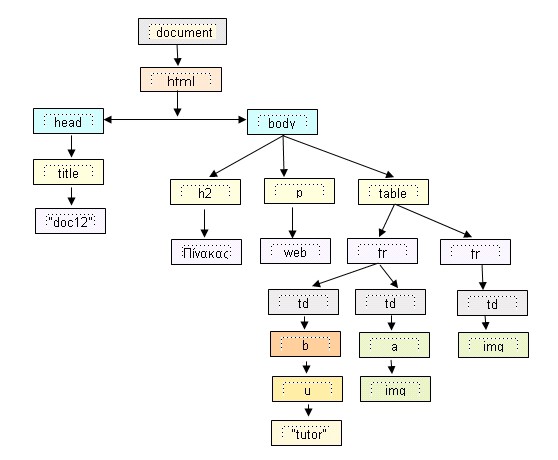 A DOM tree
A DOM tree
Once the DOM tree is built, the stylesheets are parsed to understand how to style each node. Using this information, the browser traverses down DOM nodes and calculates the CSS style, position, coordinates, etc for each node.
Once the browser has the DOM nodes and their styles, it’s finally is ready to paint the page to your screen accordingly. The result: everything you’ve ever looked at on the Internet.
The web is complex, but you just finished the hard part
So that’s the web in a nutshell. Lost? We all are, but if you’ve read this far you’ve already finished the hard part. I’ve obviously skipped over some details in the interest of showing you the big picture here; but if you can wrap your head around the basic sequence of events outlined above, filling in the details will be a piece of cake.
Check out Part 2, where we’ll tackle the structure of a basic web application. :)