
By Jonathan Solórzano-Hamilton
You have a shiny new CQRS system, it’s “dev complete,” and you’re about to start integration testing. And the 800-pound gorilla that was sleeping in the corner during your domain discussions wakes up.
Without a single glance at your comprehensive domain diagrams, engaging user stories, UI mock-ups, or well-documented acceptance criteria, it bursts through the dotted-line “context boundary” that was supposed to hold it back.
The gorilla rampages around the building shattering entities, reducing value to rubble, uprooting aggregates, and generally destroying all consensus on the project. Gorilla, thy name is Legacy Integration.

Legacy systems and process integration can sink an otherwise perfectly-executed project. It’s a monster migraine of a problem that only gets taught in the school of hard knocks. It’s also a problem that, as a developer, you will face in your career (if you haven’t already) when you start working with sufficiently established businesses and domains.
Of course, if you’re lucky, you haven’t actually started coding yet — or at least it’s still early in the process-when the gorilla wakes up. Or, if you’re smart, you see the gorilla hiding under the lampshade in the corner and, rubbing the scars of your last encounter, you preempt its inevitable rampage by incorporating it into your architecture right from the start.
Dealing with legacy systems
As the Assistant Director of Architecture at the UCLA Office for Research Information Systems, I’m responsible for bridging a lot of system and data gaps. UCLA has a decades-long pipeline of legacy business processes and systems around research which butt up against any attempt to “disrupt” these traditional approaches with new technology.
Most dauntingly, this pipeline is plugged with the occasional impenetrable iceberg of legacy data that often requires real-time wrangling.

At my office, we’ve been tasked with providing integration into these legacy systems at an increasing pace. We’re also ramping up our bespoke transactional systems to handle small business processes.
For our own systems, we’re generally following the microservice pattern. We’re incorporating more complexity, like domain-driven design (DDD) and event-sourcing, when needed. Our key challenge for these systems is legacy integration into state-persistence systems.
Approaching integration
I’m going to outline our approach in these next few paragraphs. It’s how we’ve tackled one of the problems that arises from bridging from an event-system, particularly a hybrid event system, to one that’s purely state-driven.
One key tenet that implementers often miss is that event sourcing should not be used everywhere. This is according to Greg Young, who is widely credited with introducing the “event sourcing” software architecture pattern.
In our systems, we use event sourcing to meet specifically targeted requirements. Sometimes this results in our applications having state that may reside outside of the event stream. Additionally, some of our event triggers come from unreliable source system state changes. This would demand a lot of post-hoc event correction and “rewind-replay” to fix if we were to depend only on the event stream.
A skeptical solution
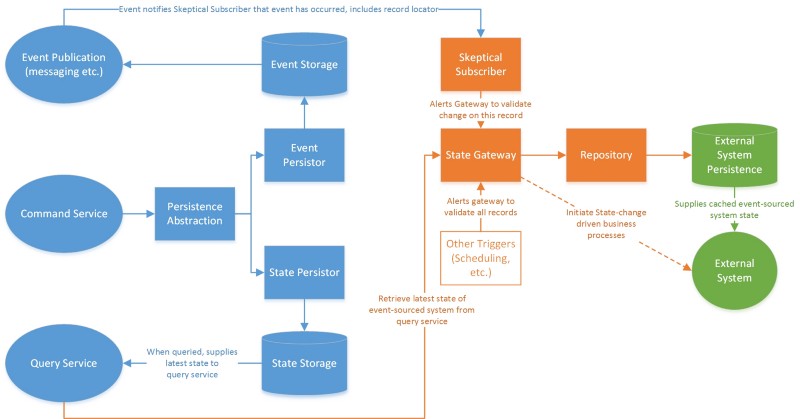
The solution we came up with for this is one I call the “Skeptical Subscriber.” The Skeptical Subscriber addresses the problem of “unreliability” in the event side of the system, at least from the perspective of the legacy state machine. It also addresses systems which may miss event generation due to external legacy data problems:
- The event source may generate events that do not result in state changes relevant to the legacy state machine. From its perspective, these are “false positive” events
- The event source may fail to generate events for changes in state that are relevant to the legacy state machine. From its perspective, these are “missed” or “skipped” events
- Events may not be generated at all due to bugs or errors in the original source of the event. This particularly happens in extract-tranform-load (ETL) streams from legacy data repositories. From any perspective these are genuinely “skipped” events
The Skeptical Subscriber approach addresses these concerns by remaining distrustful of the event stream. It treats the event stream as one possible trigger or notification that the state has changed, but it also accepts other possible triggers. It also distrusts that the notifications of state change are correct.
Once it’s notified that the state may have changed, the subscriber notifies a state gateway that queries the state of the event-sourced system.
This state gateway evaluates the state against the last-known state (as the subscribing system knew it).
If the change is relevant, it then updates the subscribing system state and, if needed, initiates related subscribing system business processes.
Some requirements
In order to use this approach, your subscribing system needs to:
- Already persist, or be able to derive from what it does persist, the state attributes it cares about from the event sourcing system
- Allow you to re-do how you inject state change data
Your event-sourcing system needs to:
- Supply a query service that reliably represents the system state and includes all state attributes required by the subscribing system
- Supply sufficient data in the event stream to locate the relevant records in the query service
- Support a “list” or other batch query from the query service
The Skeptical Subscriber you implement must include:
- A State Gateway that can query the query service for a particular record (event driven) or for a list of records (other trigger, for catching up on “missed” events)
- The State Gateway must include domain comparison logic from the context of the subscribing system that discards records if, as far as the subscribing domain is concerned, they have not changed
- An event subscription implementation to call the gateway per-record from the events
- The ability to update the persistence layer of the subscribing system with the changes (so that it does not re-update the same record next time), such as through a repository
The Skeptical Subscriber may also implement the initiation of business processes in the subscribing system.
If it’s purely state-driven, this may be through persisting new process records to launch the concomitant processes. Otherwise, it can call whatever process API is exposed.
If you do initiate these business processes, you must also implement locking in the gateway so that you do not double-up on process initiation if an event trigger occurs during the ETL process.
Positive results
There are plenty of other challenges associated with legacy systems integration, especially when moving between event-sourced and stateful contexts. This pattern, however, helps us minimize the technical burden associated with event maintenance when consuming legacy (and spotty) data.
Prior to following this pattern, we’d been working in a strictly event-sourced approach. We had lost quick access to the support opportunities afforded by having a directly-editable state. With this pattern, we’ve regained those opportunities. When the legacy system is misbehaving because it doesn’t “like” the events that it’s getting, we have shifted the burden from modifying the event stream in some way to a simple state modification.
We’ve also added a layer of loose coupling to generally insulate the subscribing system from direct exposure to the events. This allows redirection of other subscribing system triggers.
For example, a legacy ETL can serve as an initial state gateway trigger until you’re ready to switch to an event stream. And we’ve done so without over-complicating the CQRS service by implementing the interstitial skeptical subscriber as an independent entity.
Here’s a pro tip for data scientists and the engineers who serve them: if you implement polyglot persistence in the subscribing repository, you can also build out a document store that is already automatically filtered to data changes that reflect a meaningful business process.
Finally, in the event that an event is “skipped” or “missed,” we have an easy on-demand support pathway to follow. We either re-notify the subscriber about that record (if we’re aware of which record missed an event), or we perform a “catch-up” full-system query (if we’re not sure).
We can do this without having to touch the event stream. This means that other subscribing applications won’t be impacted by the support activity.
Final thoughts
It’s not the right fit for every problem (or even for most problems). But it’s a great solution for taking advantage of the loose coupling and other downstream benefits of event sourcing and CQRS, while minimizing support overhead for troubleshooting legacy data streams. This lets our developers spend more of their time writing new applications and increases our value to our consumers.
If you enjoyed this post, please click the button below and give me some claps so more people see it. Thanks!
Jonathan is the Assistant Director of Architecture and Operations at UCLA’s department of Research Information Systems. After obtaining a Physics degree from Stanford University he went on to spend over 10 years working in information systems architecture, data-driven business process improvement, and organizational management. He is also the founder of Peach Pie Apps Workshop, a company that focuses on building data solutions for non-profits.