

I’m sure you’ve heard of the incredible artificial intelligence applications out there — from programs that can beat the world’s best Go players to self-driving cars.
The problem is that most people get caught up on the AI hype, mixing technical discussions with philosophical ones.
If you’re looking to cut through the AI hype and work with practically implemented data models, train towards a data engineer or machine learning engineer position.
Don’t look for interesting AI applications within AI articles. Look for them in data engineering or machine learning tutorials.
These are the steps I took to build this fun little scraper I built to analyze gender diversity in different coding bootcamps. It’s the path I took to do research for Springboard’s new AI/ML online bootcamp with job guarantee.
Here’s a step-by-step guide to getting into the machine learning space with a critical set of resources attached to each one.
1. Start brushing up on your Python and software development practices
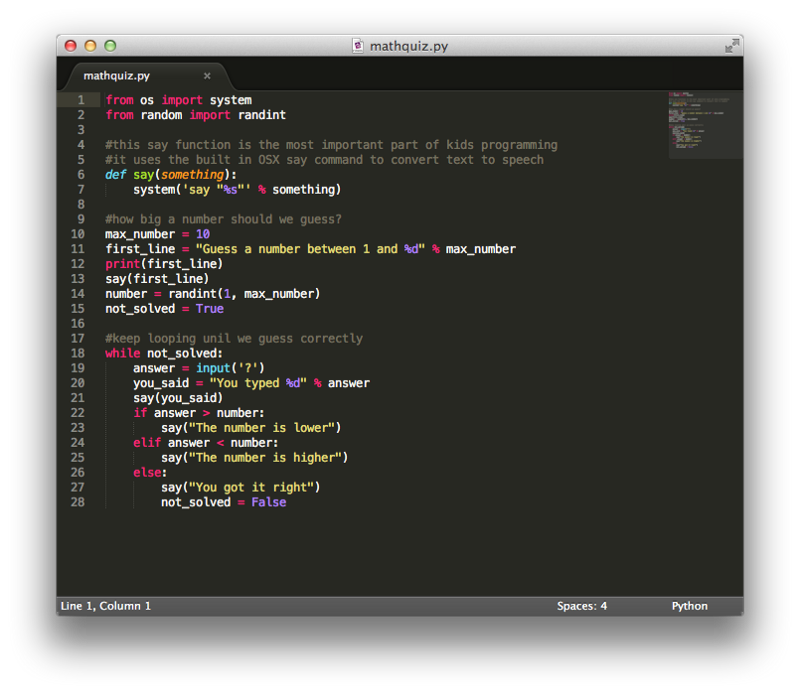
You’ll want to start off by embracing Python, the language of choice for most machine learning engineers.
The handy scripting language is the tool of choice for most data engineers and data scientists. Most tools for data have been built in Python or have built API access for easy Python access.
Thankfully, Python’s syntax is relatively easy to pick up. The language has tons of documentation and training resources. It also includes support for all sorts of programming paradigms from functional programming to object-oriented programming.
The one thing that might be a bit hard to pick up is the tabbing and spacing required to organize and activate your code. In Python, the whitespace really matters.
As a machine learning engineer, you’d be working in a team to build complex, often mission-critical applications. So, now is a good time to refresh on software engineering best practices as well.
Learn to use collaborative tools such as Github. Get into the habit of writing thorough unit tests for your code using testing frameworks such as nose. Test your APIs using tools such as Postman. Use CI systems such as Jenkins to make sure your code doesn’t break. Develop good code review skills to work better with your future technical colleagues.
One thing to read: What is the best Python IDE for data science? Take a quick read-through so you can understand what toolset you want to work in to implement Python on datasets.
I use the Jupyter Notebook myself, since it comes pre-installed with most of the important data science libraries you’ll use. It comes with an easy, clean interactive interface that allows you to edit your code on the fly.
Jupyter Notebook also comes with extensions that allow you to easily share your results with the world at large. The files generated are also super easy to work with on Github.
One thing to do: Pandas Cookbook allows you to fork into live examples of the Pandas framework, one of the most powerful data manipulation libraries. You can quickly work through an example of how to play with a dataset through it.
2. Look into machine learning frameworks and theory
Once you’re playing around with Python and practicing with it, it’s time to start looking at machine learning theory.
You’ll learn what algorithms to use. Having a baseline knowledge of the theory behind machine learning will let you implement models with ease.
One thing to read: A Tour of The Top Ten Algorithms For Machine Learning Newbies will help you get started with the basics. You’ll learn that there isn’t a “free lunch”. There is no algorithm that will give you the optimal result for each setting, so you’ll have to dive into each algorithm.
One thing to do: Play around with the interactive Free Machine Learning in Python Course — develop your Python skills and start implementing algorithms.
3. Start working with datasets and experimenting
You’ve got the tools and theory under your belt. You should think about doing little mini-projects that can help you refine your skills.
One thing to read: Take a look at 19 Free Public Data Sets for Your First Data Science Project and start looking at where you can find different datasets on the web to play around with.
One thing to do: Kaggle Datasets will let you work with lots of publicly available datasets. What’s cool about this collection is you can see how popular certain datasets are. You can also see what other projects have been built with the same dataset.
4. Scale your data skills with Hadoop or Spark

Now that you’re practicing on smaller datasets, you’ll want to learn how to work with Hadoop or Spark. Data engineers work with streaming, real-time production-level data at the terabyte and sometimes petabyte scale. Skill up by learning your way through a big data framework.
One thing to read: This short article How do Hadoop and Spark Stack Up? will help you walk through both Hadoop and Spark and how they compare and contrast with one another.
One thing to do: If you want to start working with a big data framework right away, Spark Jupyter notebooks hosted on Databricks offers a tutorial-level introduction to the framework, and gets you to practice with production-level code examples.
5. Work with a deep learning framework like TensorFlow

You’re done exploring machine learning algorithms and working with the different big data tools out there.
Now it’s time to take on the sort of powerful reinforcement learning that has been the focus of new advances. Learn the TensorFlow framework and you’ll be on the cutting edge of machine learning work.
One thing to read: Read What is TensorFlow? and understand what’s going on below-the-hood when it comes to this powerful deep learning framework.
One thing to do: TensorFlow and Deep Learning without a PhD is an interactive course built by Google that combines theory placed into slides with practical labs with code.
6. Start working with big production-level datasets

Now that you’ve worked with deep learning frameworks, you can start working towards large production-level datasets.
As a machine learning engineer, you’ll be making complex engineering decisions on managing large amounts of data and deploying your systems.
That would include collecting data from APIs and web scraping, SQL + NoSQL databases and when you’d use them, use of pipeline frameworks such as Luigi or Airflow.
When you deploy your applications, you might use container-based systems such as Docker for scalability and reliability, and tools such as Flask to create APIs for your application.
One thing to read: 7 Ways to Handle Large Data Files for Machine Learning is a nice theoretical exercise into how you would handle big datasets, and can serve as a handy checklist of tactics to use.
One thing to do: Publicly Available Big Data Sets is a list of places where you can get very large datasets — ready to practice your newfound data engineering skills on.
7. Practice, practice, practice, build towards a portfolio and then a job

Finally, you’ve gotten to a point where you can build working machine learning models. The next step to advance your machine learning career is to find a job with a company that holds those large datasets so you can apply your skills every day to a cutting-edge machine learning problem.
One thing to read: 41 Essential Machine Learning Interview Questions (with answers) will help you practice the knowledge you need to ace a machine learning interview.
One thing to do: Go out and find meetups that are dedicated to machine learning or data engineering on Meetup — it’s a great way to meet peers in the space and potential hiring managers.
Hopefully, this tutorial has helped cut through the hype around AI to something practical and tailored that you can use. If you feel like you need a little bit more, the company I work with, Springboard, offers a career track bootcamp dedicated to AI and machine learning with a job guarantee, and 1:1 mentorship from machine learning experts.