by Garrett Vargas
How To Design a Serverless Async API

I recently ran a workshop to teach developers how to create an Alexa skill. The workshop material centered around a project to return car rental search results. Because I wanted to focus the learning on developing the conversational flow and not the mechanics of doing a car search, I decided to encapsulate the search logic behind an API. In addition, since the car search request can take 10 or more seconds to complete, I wanted the call to be asynchronous so we could build a conversation like:
“Find a Car in New York next weekend”
“What size car would you like for your trip in New York next weekend?”
“A small car”
“Is there a specific company you’d like to rent from?”
“No”
“OK, I found a compact car from Enterprise for $100…”
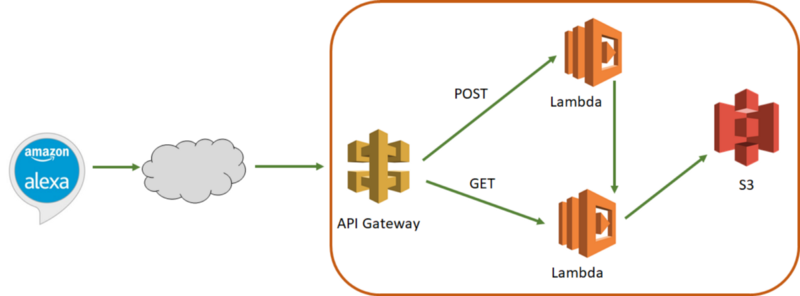
The implementation of the asynchronous API was a pretty interesting project in and of itself, and in this blog post I’m going to tell you how I did this in a serverless way using API Gateway, Lambda functions, and S3.
S3 Bucket
The S3 bucket in this architecture serves as a cache that stores search results to be retrieved later. Callers of the API are given a token when they start a search, and the basic design is to use that token as part of the S3 object name to allow you to retrieve the contents on a subsequent call. To prevent the bucket from filling up with search results, you can set an expiration policy that is appropriate for the lifecycle of your API results (i.e. how long do you want the asynchronous results to stay alive?).
Note that the expiration policy can only be set in day increments, so even if you have results that should be considered stale after 30 minutes, with this approach you’ll still have the object in storage for at least a day.
You can associate a timestamp with the object and check it in your code to make sure that the result is ignored if it is more than a certain age, but the object itself will persist for at least a day.
To set up your bucket, take the following steps in the AWS Management Console:
- Click Create Bucket from S3
- Enter the name of the bucket and make note of which region you create it in (you’ll need to make sure your Lambda functions and API Gateway are all set up in this same region). Note that S3 bucket names are globally unique, which means a name like “test” will likely be taken. You’ll need to pick something that no other user has created before, so something that incorporates your name or the current date would be a good starting point
- You can keep the bucket with the default permissions and no versioning — you’ll explicitly grant your Lambda function permission to this bucket, so don’t expose it publicly to the world (in fact, that would be a bad idea!)
- Once the bucket is created, click on it and go to the Management tab
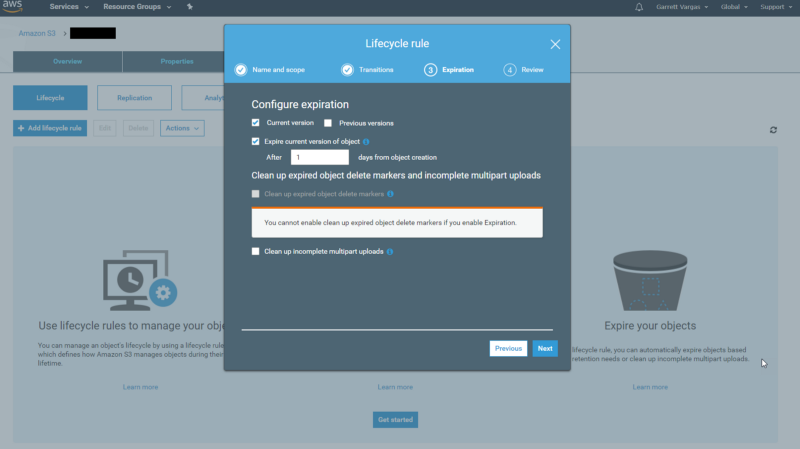
- Enter a lifecycle by clicking Add Lifecycle Rule
- Enter a name and skip through the Transitions screen to end up on the Expiration screen
- Since we didn’t add versioning to our S3 bucket, you only need to configure an expiration rule for the Current Version as illustrated below
Lambda Functions
I had the basic idea to use a Lambda function to perform a search, return a token to the caller, and write the results into an S3 bucket. The results could then be retrieved by a subsequent call, passing in the token and any additional filtering information (for example, “small car” in the example above).
However, I quickly realized that my Lambda function would return after I validated the input parameters and called back with a token, which meant that I wasn’t able to keep it alive to write the search results out to S3.
What I needed was a way to continue code execution after I had the token so I could return to the API caller. To do this, I created two Lambda functions, one to validate the parameters, and the other to perform the search and lookup the cached results.
The first function validates the parameters, and once it has done so, it invokes the second Lambda function asynchronously to kick off the search, then returns with a generated token back to the caller while the second Lambda function churns away. The token that my generateToken function used in my workshop was just a timestamp since I didn’t have scalability considerations, but it could also be a UUID or other generated ID.
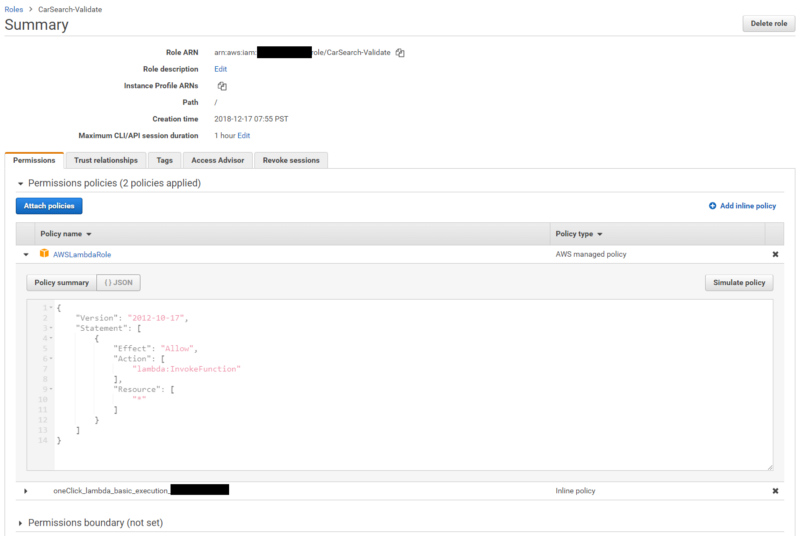
Because this Lambda function invokes another Lambda function, you’ll need to give it the appropriate permissions to make this call. You do this by creating the appropriate IAM role following these steps:
- In your Lambda function, under Execution role, select Create a Custom Role in the dropdown
- This will launch IAM in a new tab
- Select Create a new IAM Role from the dropdown for IAM Role and provide it with a name
- In the full list of IAM roles, select this new role and click Attach Policies
- Filter for the AWSLambdaRole policy and add it to this role. Optionally, you can modify the JSON to give it access only to the second Lambda function after you create it in the following step, by referring to its ARN in the Resource field
The second Lambda function has two responsibilities — to perform the search and save the results into an S3 bucket, and to retrieve the results from an S3 bucket when called with a valid token. I could have separated this logic and created three Lambda functions, but I felt that it was a better design to have the logic that accessed the cache and knew how to encode/decode the object in one place.
Because API Gateway allows you to map query parameters, you’ll find it easy to differentiate between the cases when this function is being called to perform a new search and when it is being asked to retrieve a search result (I’ll demonstrate how to do that later). Note that this function calls a lengthy internal doSearch function which writes results to S3 based on token provided from the previous function.
Because this Lambda function makes a call to read and write from S3, you’ll have to set the appropriate permissions for this Lambda function — which will be different than the first one. Follow the same set of steps to create an IAM role, only this time rather than the AWSLambdaRole policy, you’ll want to associate the AmazonS3FullAccess policy — again optionally providing the ARN of the specific S3 bucket that you want to provide full access to.
API Gateway
With the Lambda functions out of the way, the next step is to create an API Gateway around these functions so that a user has a REST API to call into. Remember, the flow I wanted to build from a client perspective was:
- POST call to the API with the desired search parameters
- Get a token back as a response
- Ask the user some additional questions to help narrow the results
- GET call to the API with the token and additional filter criteria to get the actual result set
API Gateway makes it easy and convenient to access your Lambda functions as desired.
The first step is to create your new API. In the AWS Management Console, you can navigate to API Gateway and click Create API to create a new API. Once you’ve given it a name, you need to create the methods that you want to use in accessing the API. In my case, that meant selecting POST and GET as new methods from the Actions drop down menu.
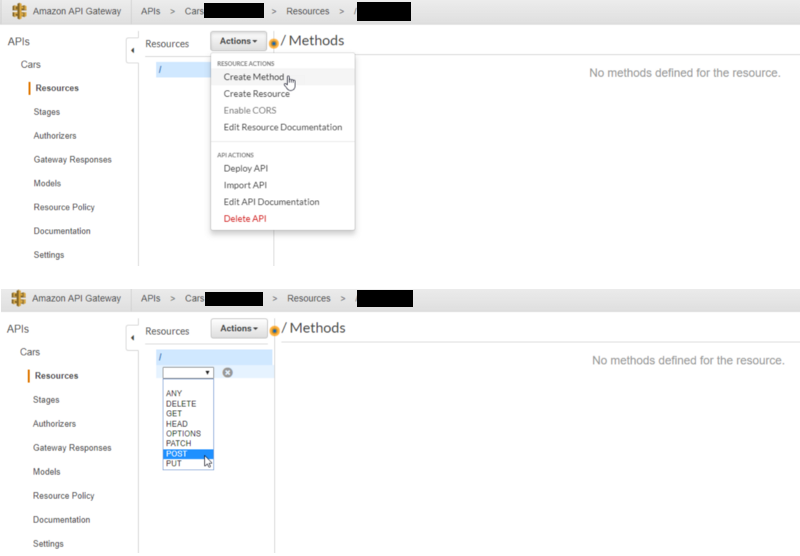
Let’s start with the POST. Once you’ve selected the POST method, you’ll be asked the Integration Type you’d like to use. Select Lambda Function, and then fill in the details with the first Lambda function you created to validate parameters and kick off the search. You don’t need to point API Gateway to the second Lambda function that does the search — that is done by by the validation function for you.
After you set these parameters, you’ll see the full API flow, along with a TEST sidebar that will allow you to pass a test payload to your API to see if it executes properly.
For the GET call, do similar, though in this case you’re going to call the second Lambda function passing in a token so it knows to retrieve the results from your S3 cache. Also, in this case you won’t have a JSON payload to pass on — rather the expectation is that the customer supplies query parameters in the URL. API Gateway allows you to do this transformation easily via a Mapping Template.
The basic steps are as follows:
- Add a GET method under the Actions drop down menu
- Set Integration Type to Lambda Function
- Enter in the details of the second Lambda function
- Once created, click on the Integration Request step of your GET method execution
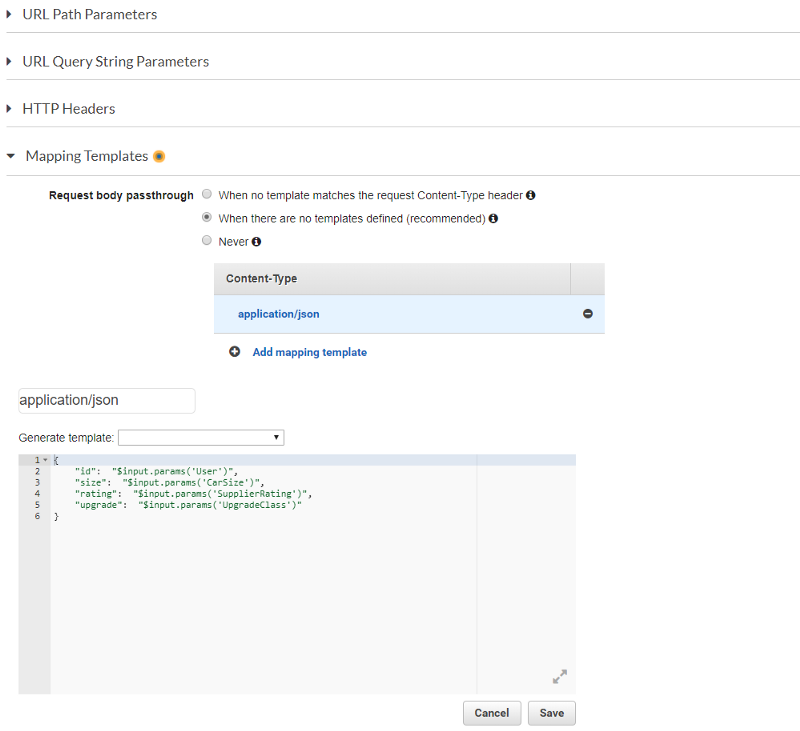
- Expand the Mapping Templates section and click Add mapping template
- Type application/json into the edit box and click the check to confirm
- Enter in the mapping from query parameters to JSON request — you’ll do this with keys of the form
"field": “$input.params('queryparam')"This will map the query param namedqueryparamto a field namedfield
The nice thing here is that you don’t have to have the same name for the query parameters exposed to your client as for internal usage in your Lambda function. For example, in my case I expect parameters of User, CarSize, SupplierRating, and UpgradeClass but I map these to id, size, rating, and upgrade respectively for internal use.
Build and Deploy
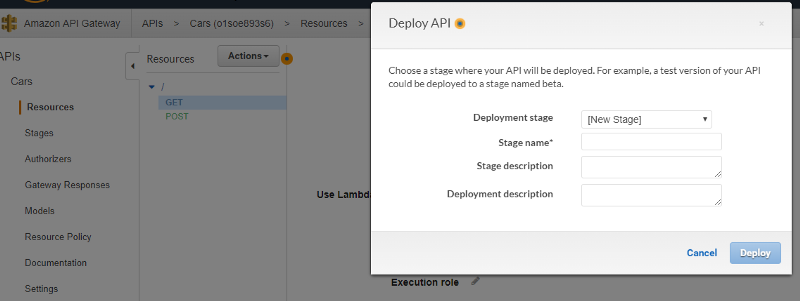
Now that you’ve integrated your Lambda function into API Gateway, you’re ready to build and deploy. Under the Actions menu, select Deploy API. API Gateway will ask you for a Deployment Stage; choose [New Stage] to create a new stage, and provide it a name like Beta. After you deploy the API, API Gateway will tell you the URL to use to invoke your API. You use the same URL for both the POST and GET functions. Pretty easy, isn’t it?
Wrap Up
What I described here is the foundation for an asynchronous serverless API. There are a lot of edge cases and error handling that I glossed over, as well as techniques within API Gateway to harden the API that I didn’t address such as validating that all required parameters are set before invoking the Lambda function or requiring an access token as opposed to creating a wide-open API.
In addition, this use case was for a small workshop environment. You’d have to look at your own use case to understand the scale you need and whether this approach would work for you. You’d want to pay particular attention to the concurrent execution settings for your Lambda function. If the underlying call you are trying to make takes a minute to run for example, even with a limit of 1000 concurrent executions you’d only be able to make 16 calls per second, which may not prove sufficient for a full production workload.
Caveats aside, for the right use cases this approach can be a simple and powerful way to create an async API without having to stand up dedicated servers or a caching solution.