By Ljubica Lazarevic
Introduction
With the new Neo4j Kafka streams now available, my fellow Neo4j colleague Tom Geudens and I were keen to try it out. We have many use-cases in mind that leverage the power of graph databases and event-driven architectures. The first one we explore combines the power of Graph Algorithms with a transactional database.
The new Neo4j Kafka streams library is a Neo4j plugin that you can add to each of your Neo4j instances. It enables three types of Apache Kafka mechanisms:
- Producer: based on the topics set up in the Neo4j configuration file. Outputs to said topics will happen when specified node or relationship types change
- Consumer: based on the topics set up in the Neo4j configuration file. When events for said topics are picked up, the specified Cypher query for each topic will be executed
- Procedure: a direct call in Cypher to publish a given payload to a specified topic
You can get a more detailed overview of how each of these might look like here.
Overview of the situation
Graph algorithms provide powerful analytical abilities. They help us understand the context of our data better by analysing relationships. For example, graph algorithms are used to:
- Understand network dependencies
- Detect communities
- Identify influencers
- Calculate recommendations
- And so forth.
Neo4j offers a set of graph algorithms out of the box via a plugin that can run directly on data within Neo4j. This library of algorithms has been very popularly received. Many times I’ve received feedback that the plugins are as fast or faster than what clients have used before. With such wonderful feedback, why wouldn’t we want to apply these optimised and performant algorithms on a Neo4j database?
Getting the full advantage of any analytical process needs resources. To get a nice, performant experience, we want to provide as much CPU and memory as we can afford.
Now, we could run this kind of work on our transactional cluster. But in this typical architecture, we’re going to run into some challenges. For example, if one machine is big, the other machines in the cluster should be matching. This could mean that the set up architecture is expensive.
The other challenge we face is that our cluster is supposed to be managing transactions — day-to-day queries such as processing requests. We don’t want to weigh it down with crunching through various iterations and permutations of a model. Ideally, we want to offload this along with associated analytical work.
If we know that the heavy querying that is going to take place is read-only, then it’s an easy solution. We can spin up read replicas to manage the load. This keeps the cluster focussed on what it’s supposed to be doing, supporting an operational, transactional system.
But how do we handle write backs to the operational graph as part of the analytical processing? We want those results, such as recommendations, as soon as they are available.
Read replicas are as the name suggests — they are for read-only applications. They will not be involved in either elections of leaders in the cluster, nor in writing. Using Neo4j-streams, we can stream the results back from the read replica back to the cluster for consumption.
The big advantages of approaching it this way include:
- We have our high availability/disaster recovery afforded to us from the cluster.
- The data is going to be identical on both the read replica and the cluster. We don’t have to worry about updating the read replica because the cluster is going to take care of that for us.
- The id’s for nodes and relationships will be identical on both the servers of the cluster, and the read replica. This makes updating really easy.
- We can provision resources as necessary to the read replica, which is likely to be very different from the cluster.
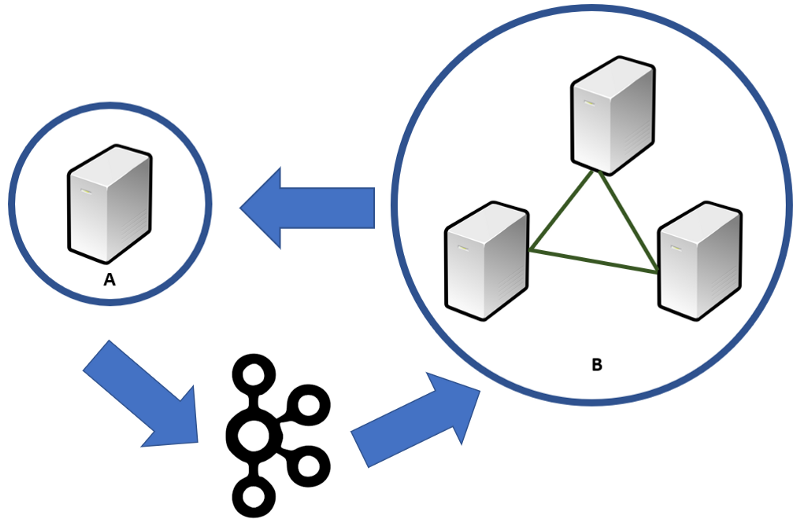
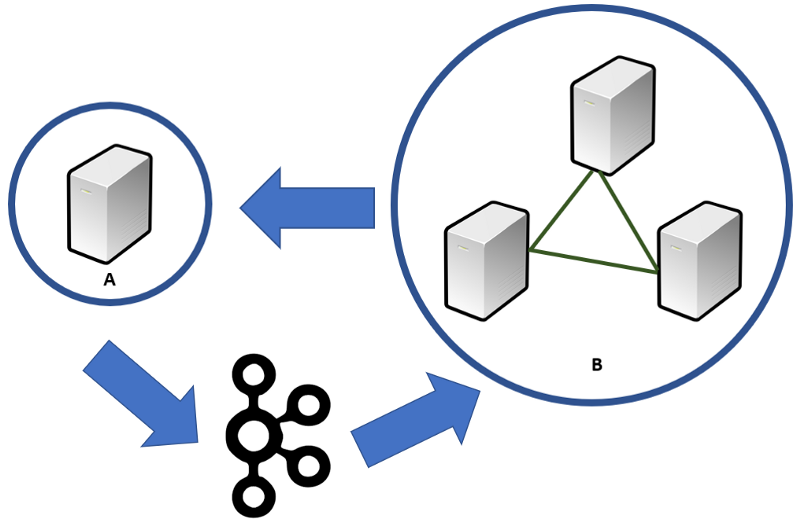
Our architecture will look like the figure below. A is our read replica, and B is our causal cluster. A will receive transactional information from B. Any results calculated by A will be streamed back to B via Kafka messages.
So with our updated pattern, let’s continue with our simple example.
The Example Data Set
We’re going to use the Movie Database data set available from the :play movie-guide guide in Neo4j Browser. For this example we are going to use four Neo4j instances:
- The analytics instance — this is going to be our read replica, and on this instance we’re going to run PageRank on all Person nodes in the data set. We will call the
streams.publish()procedure to post the output to our Kafka topic. - The operational instances — this is going be our three-server causal cluster which is going to be listening for any changes to the person node. We will update as changes come in.
For Kafka, we’ll follow the instructions from the quick start guide up until step 2. Before we get Kafka up and running, we will need to set up the consumer elements in the Neo4j configuration files. We also will set up the cluster itself. Please note that at the moment neo4j-streams only works with Neo4j version 3.4.x.
To set up the three server clusters and a read replica, we will follow the instructions provided in the Neo4j operations manual. Follow the instructions for the cores, and also for one read replica.
Additionally, we’re going to need to add the following to neo4j.config for the causal cluster servers:
#************# Kafka Config — Consumer#************kafka.zookeeper.connect=localhost:2181kafka.bootstrap.servers=localhost:9092kafka.group.id=neo4j-core1streams.sink.enabled=truestreams.sink.topic.cypher.neorr=WITH event.payload as payload MATCH (p:Person) WHERE ID(p)=payload[0] SET p.pagerank = payload[1]
Note that we want to change kafka.group.id to neo4j-core2 and neo4j-core3 respectively.
For the read replica, we’ll need to add the following to neo4j.config:
#************# Kafka Config - Procedure#************kafka.zookeeper.connect=localhost:2181kafka.bootstrap.servers=localhost:9092kafka.group.id=neo4j-read1
You will need ti download and save the neo4j-streams jar into the plugins folder. Also you need to add the graph algorithm library, via Neo4j Desktop, or manually.
With these changes to the respective config files set and saved and plugins installed, we will start everything up, in the following order:
- Apache Zookeeper
- Apache Kafka
- The three instances for the Neo4j causal cluster
- The read replica
Once all of the Neo4j instances are up and running and the cluster has discovered all of the members, we can now run the following query on the read replica:
CALL algo.pageRank.stream('MATCH (p:Person) RETURN id(p) AS id','MATCH (p1:Person)-->()<--(p2:Person) RETURN distinct id(p1) AS source, id(p2) AS target',{graph:'cypher'}) YIELD nodeId, scoreWITH [nodeId,score] AS resCALL streams.publish('neorr',res)RETURN COUNT(*)
This Cypher query will call the PageRank algorithm with the specified configuration. Once the algorithm is complete, we will stream the returned node id’s and the PageRank score to the specified topic.
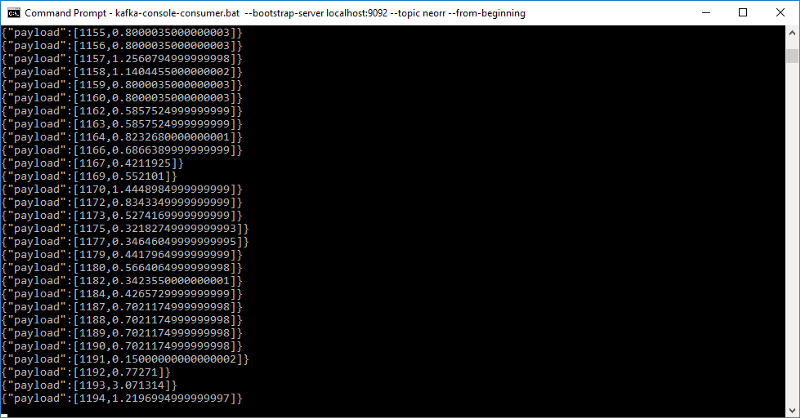
We can have a look at what the neorr topic looks like by running Step 5 of the Apache Kafka quick start guide (replacing test with neorr):
Summary
In this post we’ve demonstrated:
- Separating transactional and analytical data concerns
- Painlessly flowing analytical results back back for real-time consumption
Whilst we’ve used a simple example, you can see how complex analytical work can be carried out, supporting an event-driven architecture.