

There are some magical things about the Internet, and one thing in particular is that it works. In spite of so many obstacles, we can deliver our packets over the globe, and do so fast.
Even more specifically, one amazing thing about the Internet is its ability to handle errors.
What do I mean by errors? When a packet or a frame is received by a machine, we say it contains an error if the data that had been sent is not the data that was received. For instance, a single 1 was mistakenly received as a 0 after its transmission.
This can happen due to many different reasons. Perhaps there was some disturbance in the wire where the data was transmitted – say, a child rode her bicycle over the wire. Perhaps there was some collision in the air as many people transmitted at once. Maybe it was a device's error.
Regardless of the specific reason, you still get valid data on the Internet. Without handling errors, you may read the last sentence and instead of errors read errbbb. Weird, isn't it? So how does the Internet handle errors?
There are two main approaches for handling errors – detection, and correction. We shall start by describing detection, and then talk about correction.
What is Error Detection?
When dealing with error detection, we are looking for a boolean result – True, or False. Is the frame/packet valid, or not. That is all. We don’t want to know where the error occurred. If the frame is invalid, we will simply drop it.
So when the receiver receives a frame, they will determine whether an error has occurred. If the frame is valid, they will read it. If the frame contains errors - the receiver will drop it.
 _Error Detection: we only want to know if the frame/packet is valid or not. (Source: Brief)_
_Error Detection: we only want to know if the frame/packet is valid or not. (Source: Brief)_
One method for error detection is using a checksum. A common implementation of a checksum is called CRC – Cyclic Redundancy Check.
In this post we will not trouble ourselves with the mathematical implementation of CRCs in the real world (if you're interested, check out Wikipedia). Rather, we'll simply try to understand the concept. To do so, let’s implement a very simple checksum mechanism ourselves.
Consider a protocol for transmitting 10-digit phone numbers between endpoints. This protocol is extremely simple: each packet includes exactly 10 bytes, each one representing a digit. For example, a packet might include the following digits:
5551234567
 _A packet with a payload of 10 digits (Source: Brief)_
_A packet with a payload of 10 digits (Source: Brief)_
For simplicity's sake, we will omit the headers of the packet and focus solely on the payload.
Now, we will add a checksum. Say that we add all the digits. So in this example, we would calculate 5 + 5 +5 +1+… all the way through 7. We would get 43. This would be our checksum value.
Now, the sender won’t only send the phone number, but also the checksum value right after it. In this example, the sender would send:
 _The packet's data is followed by a checksum. (Source: Brief)_
_The packet's data is followed by a checksum. (Source: Brief)_
Now, as the receiver, you can do the same thing. You will read the phone number, and calculate the checksum. You will add the digits, and get 43.
Since you've received the correct result (that is, your calculation based on the data matches the checksum value sent in the packet), you can assume that the frame is valid.
 _The sender compares their calculated checksum value and the checksum in the packet. If the values match, the packet is assumed to be valid (Source: Brief)_
_The sender compares their calculated checksum value and the checksum in the packet. If the values match, the packet is assumed to be valid (Source: Brief)_
What happens in case of an error? 🤔
Let’s say, for instance, that the digit 2 was replaced by an 8. Now, even though the sender sent the same stream as before ( 555123456743 ), you, as the receiver, see something a bit different:
 _A packet containing an error (Source: Brief)_
_A packet containing an error (Source: Brief)_
Now, you are calculating the checksum, adding all the digits. You get 49. Since this value is different from the checksum value specified in the original frame, 43, the frame is considered to be invalid and you drop it.
 _The sender compares their calculated checksum value and the checksum in the packet. If the values don't match, the packet is assumed to be invalid (Source: Brief)_
_The sender compares their calculated checksum value and the checksum in the packet. If the values don't match, the packet is assumed to be invalid (Source: Brief)_
Are there problems with this method? 🤔
Yes, there are. Consider, for example, what happens if there are two errors – and instead of the original stream ( 555123456743 ), you receive the following:
 _A packet received with two errors, resulting in the stream
_A packet received with two errors, resulting in the stream 456123456743 (Source: Brief)_
What happens when you add the digits?
Even though the digits are not the same as the original packet, the checksum will remain correct, and the frame will be regarded as valid.
 _Despite the errors, the checksum value happens to be correct, resulting in a false assumption that the packet is valid (Source: Brief)_
_Despite the errors, the checksum value happens to be correct, resulting in a false assumption that the packet is valid (Source: Brief)_
Real checksum functions, such as CRCs, are of course much better implemented than the one in our example – but in extremely rare cases, such problems may occur.
Notice that using this kind of method, error detection, we don’t know where the problem occurred, but only whether the frame is valid or not. If the checksum value is invalid, we assume that the frame is invalid and drop it.
What is Error Correction?
As mentioned earlier, detection is not the only way to handle errors. Another approach might be to find the error and correct it. How can we do that?
An extremely simple way would be to transmit the data many times – let’s say, three times. For example, the stream 5551234567 would be transmitted as follows:
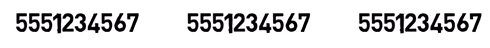 _Sending the same data multiple times (Source: Brief)_
_Sending the same data multiple times (Source: Brief)_
So we basically sent the data three times.
Now, in case of an error in one digit, the receiver can look at the other two digits, and choose the one that appears two times out of three.
So, for instance, if we had a problem and 2 was replaced with an 8, the receiver would get this stream:
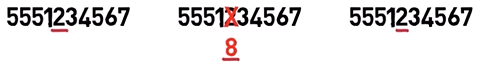 _An error in one of the occurrences of the data (Source: Brief)_
_An error in one of the occurrences of the data (Source: Brief)_
Now, as a receiver, you can say: “I have 2, 8, 2… so it was probably 2 in the original message”.
Is this problematic? Well, in some rare cases, we might get the same error twice. So it is possible, even though unlikely, that two of the original twos have been received as eights.
So while the sender sent this stream:
_Sending the same data multiple times (Source: Brief)_
The first 2 was mistakenly read as an 8, and also the second 2 was received as an 8:
 _Two identical errors; Rare, but possible (Source: Brief)_
_Two identical errors; Rare, but possible (Source: Brief)_
Now, it looks as if the original message included an 8, and not a 2.
What can you do in order to lower the probability of such scenario?
The most simple solution would be to simply send the data even more times. Let’s say, five times. So now we duplicate all the data, and send it 5 times in total…
 _Sending the data five(!) times (Source: Brief)_
_Sending the data five(!) times (Source: Brief)_
Now, say that two errors occurred, and again two of the 2 digits were replaced with 8s.
 _Two identical errors; Rare, but possible (Source: Brief)_
_Two identical errors; Rare, but possible (Source: Brief)_
Clearly, it is very unlikely to get the same error twice, but even in this case, we still get 2 three times, so as the receiver you can tell, with a high probability, that the original message contained a 2, rather than an 8.
What's the Overhead?
Now would be a good time to introduce the term overhead. When we say overhead, we basically mean data or time needed to convey the actual message. Let’s first understand what this term means in general, and then consider it in the context of handling errors.
Let’s say that I have a lesson to teach in my university. My goal is to teach the lesson itself, which is also called the payload in that context – that is, the actual data or message I would like to convey.
In order to teach the lesson, or to convey the payload, I first have to physically get to the university – so I get out of my home, walk to the bus station, wait for the bus, take the bus, get off the bus, walk to the building, wait for the lesson to start – and only then do I actually get to teach the lesson.
This entire process is overhead that I have to pay in order to deliver the payload, in this case – to teach the lesson.
 _Overhead and Payload are two extremely important terms in Computer Networks (Source: Brief)_
_Overhead and Payload are two extremely important terms in Computer Networks (Source: Brief)_
The same applies in computer networks. Our payload is the data, and there is always some overhead associated with sending it.
Back to Handling Errors
In the context here – sending the data three times, as suggested earlier, means that for every byte of payload we have two bytes of overhead. If we send the data five times, then for every byte of payload, we have four bytes of overhead. That’s a LOT!
Consider error detection, on the other hand. In our example protocol for sending phone numbers, how much overhead did we have?
Recall that for every ten-digit phone number, that is ten bytes, we included a two-digit checksum value. In other words, we had two bytes of overhead for ten bytes of payload. It is clear that in our example, error detection yields much smaller overhead in comparison to error correction.
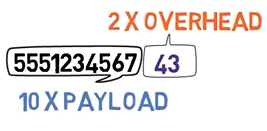 _In the sample protocol, for every ten-digit phone number (ten bytes of payload), we included a two-digit checksum value (two bytes of overhead) (Source: Brief)_
_In the sample protocol, for every ten-digit phone number (ten bytes of payload), we included a two-digit checksum value (two bytes of overhead) (Source: Brief)_
There are better ways to achieve error correction with high accuracy than to simply send the data so many times, but they are more complicated and out of scope for this post. Even with very complicated error correction techniques, they still require lots of overhead when compared to error detection.
Also, notice that except for the bytes sent as overhead in case of error correction, error detection is much simpler.
Error Correction vs Error Detection – Which is Better?
We already concluded that error detection is simpler, and with a smaller payload compared to error correction.
So, when would we prefer error correction?
One case might be when we have a one-way link. That is, a network where we can only transfer data in one direction.
For example, say you have a secret agent that you need to send a message to. The agent knows that they need to look up to the sky at exactly midnight, and they will see a series of flashes indicating the secret message.
The secret agent cannot reply, or their location and identity will be revealed. In addition, you don’t want to send the message over and over again, as not to draw much attention, and to make it harder for someone to intercept the message.
In this case, you definitely want your agent to receive the exact message that you’ve sent. Consider a case where you want to send them the message “do not place the bomb”.
 _A sensitive message for a secret agent (Source: Brief)_
_A sensitive message for a secret agent (Source: Brief)_
Of course, you don’t want to risk the unfortunate scenario of the agent reading the message as “do now place the bomb”, due to an error.
 _An error may change the meaning of the message substantially (Source: Brief)_
_An error may change the meaning of the message substantially (Source: Brief)_
If you use error detection, the agent might be aware that the message they received is invalid in case of an error, but they won’t be able to tell you that they need you to send the message again. As you want the agent to be able to read your message correctly and without sending any data back to us, error correction is preferred.
So, one-way link is one case where we prefer error correction. What about other cases?
Sometimes you just can’t send the data again, perhaps because it has been erased from the memory of your machine. That is, the data is deleted right after it has been sent. In this case, you'd clearly prefer error correction, as sending the data again, as we would do with error detection, is just impossible.
Also, if sending the data again is possible, but extremely expensive, error correction may be preferable.
For example, if you send a message to the moon, say, with a spaceship – it might be really expensive to send it over again in case of an error. Using error correction, you send the data only once and the receiver should be able to deal with it, even if an error occurred.
 _Cases where correction is preferred (Source: Brief)_
_Cases where correction is preferred (Source: Brief)_
In general, we prefer error correction when retransmitting the data is costly or impossible.
When would we prefer error detection?
Well, in case we can retransmit the data, we usually prefer error detection since it comes with very little overhead compared to error correction. Especially, when sending the data is relatively cheap.
For example, on the Internet, if an error occurs when you send a frame, no problem – you can simply send it again!
For example, when I covered the Ethernet protocol in a previous post, I mentioned that Ethernet protocol uses change detection, namely CRC32 – that is, 32 bits (or 4 bytes) of a checksum for every frame.
Note that it doesn’t mean that error detection is simply better. It just better fits the Internet than error correction. As mentioned before, error correction is preferable in other cases.
Wrapping Up
In this tutorial, we discussed various methods for handling errors. We looked at error detection, where we only know whether a frame is valid or not. We also considered error correction, where the receiver can restore the correct value of an erroneous frame. We also introduced the term overhead.
We then understood why we use error detection on the Internet, rather than error correction. Stay tuned for more posts in this series about Computer Networks 💪🏻
About the Author
Omer Rosenbaum is Swimm’s Chief Technology Officer. He's the author of the Brief YouTube Channel. He's also a cyber training expert and founder of Checkpoint Security Academy. He's the author of Computer Networks (in Hebrew). You can find him on Twitter.