By Alex Nadalin
How beautiful is {}?
It lets you store values by key, and retrieve them in a very cost-efficient manner (O(1), more on this later).
In this post I want to implement a very basic hash table, and have a look at its inner workings to explain one of the most ingenious ideas in computer science.
The problem
Imagine you’re building a new programming language: you start by having pretty simple types (strings, integers, floats, …) and then proceed to implement very basic data structures. First you come up with the array ([]), then comes the hash table (otherwise known as dictionary, associative array, hashmap, map, and…the list goes on).
Ever wondered how they work? How they’re so damn fast?
Well, let’s say that JavaScript did not have have {} or new Map(), and let’s implement our very own DumbMap!
A note on complexity
Before we get the ball rolling, we need to understand how complexity of a function works: Wikipedia has a good refresher on computational complexity, but I’ll add a brief explanation for the lazy ones.
Complexity measures how many steps are required by our function — the fewer steps, the faster the execution (also known as “running time”).
Let’s take a look at the following snippet:
function fn(n, m) { return n * m}
The computational complexity (from now simply “complexity”) of fn is O(1), meaning that it’s constant (you can read O(1) as “the cost is one”): no matter what arguments you pass, the platform that runs this code only has to do one operation (multiply n into m). Again, since it’s one operation, the cost is referred as O(1).
Complexity is measured by assuming arguments of your function could have very large values. Let’s look at this example:
function fn(n, m) { let s = 0
for (i = 0; i < 3; i++) { s += n * m }
return s}
You would think its complexity is O(3), right?
Again, since complexity is measured in the context of very large arguments, we tend to “drop” constants and consider O(3) the same as O(1). So, even in this case, we would say that the complexity of fn is O(1). No matter what the value of n and m are, you always end up doing three operations — which, again, is a constant cost (therefore O(1)).
Now this example is a little bit different:
function fn(n, m) { let s = []
for (i = 0; i < n; i++) { s.push(m) }
return s}
As you see, we’re looping as many times as the value of n, which could be in the millions. In this case, we define the complexity of this function as O(n), as you will need to do as many operations as the value of one of your arguments.
Other examples?
function fn(n, m) { let s = []
for (i = 0; i < 2 * n; i++) { s.push(m) }
return s}
This examples loops 2 * n times, meaning the complexity should be O(2n). Since we mentioned that constants are “ignored” when calculating the complexity of a function, this example is also classified as O(n).
One more?
function fn(n, m) { let s = []
for (i = 0; i < n; i++) { for (i = 0; i < n; i++) { s.push(m) } }
return s}
Here we are looping over n and looping again inside the main loop, meaning the complexity is “squared” (n * n): if n is 2, we will run s.push(m) 4 times, if 3 we will run it 9 times, and so on.
In this case, the complexity of the function is referred as O(n²).
One last example?
function fn(n, m) { let s = []
for (i = 0; i < n; i++) { s.push(n) }
for (i = 0; i < m; i++) { s.push(m) }
return s}
In this case we don’t have nested loops, but we loop twice over two different arguments: the complexity is defined as O(n+m). Crystal clear.
Now that you’ve just gotten a brief introduction (or refresher) on complexity, it’s very easy to understand that a function with complexity O(1) is going to perform much better than one with O(n).
Hash tables have a O(1) complexity: in layman’s terms, they’re superfast. Let’s move on.
(I’m kinda lying on hash tables always having O(1)complexity, but just read on ;))
Let’s build a (dumb) hash table
Our hash table has 2 simple methods — set(x, y) and get(x). Let’s start writing some code:
And let’s implement a very simple, inefficient way to store these key-value pairs and retrieve them later on. We first start by storing them in an internal array (remember, we can’t use {} since we are implementing {} — mind blown!):
Then it’s simply a matter of getting the right element from the list:
Our full example:
Our DumbMap is amazing! It works right out of the box, but how will it perform when we add a large amount of key-value pairs?
Let’s try a simple benchmark. We will first try to find a non-existing element in a hash table with very few elements, and then try the same in one with a large quantity of elements:
The results? Not so encouraging:
with very few records in the map: 0.118mswith lots of records in the map: 14.412ms
In our implementation, we need to loop through all the elements inside this.list in order to find one with the matching key. The cost is O(n), and it’s quite terrible.
Make it fast(er)
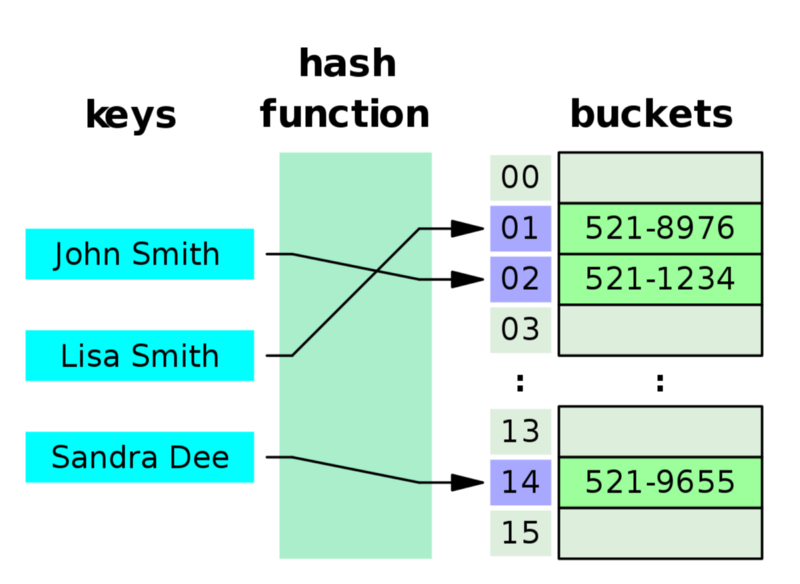
We need to find a way to avoid looping through our list: time to put hash back into the hash table.
Ever wondered why this data structure is called a hash table? That’s because a hashing function is used on the keys that you set and get. We will use this function to turn our key into an integer i, and store our value at index i of our internal list. Since accessing an element, by its index, from a list has a constant cost (O(1)), then the hash table will also have a cost of O(1).
Let’s try this out:
Here we are using the string-hash module, which simply converts a string to a numeric hash. We use it to store and fetch elements at index hash(key) of our list. The results?
with lots of records in the map: 0.013ms
W — O — W. This is what I’m talking about!
We don’t have to loop through all elements in the list, and retrieving elements from DumbMap is super fast!
Let me put this as straightforwardly as possible: hashing is what makes hash tables extremely efficient. No magic. Nothing more. Nada. Just a simple, clever, ingenious idea.
The cost of picking the right hashing function
Of course, picking a fast hashing function is very important. If our hash(key) runs in a few seconds, our function will be quite slow regardless of its complexity.
At the same time, it’s very important to make sure that our hashing function doesn’t produce a lot of collisions, as they would be detrimental to the complexity of our hash table.
Confused? Let’s take a closer look at collisions.
Collisions
You might think “Ah, a good hashing function never generates collisions!”: well, come back to the real world and think again. Google was able to produce collisions for the SHA-1 hashing algorithm, and it’s just a matter of time, or computational power, before a hashing function cracks and returns the same hash for 2 different inputs. Always assume your hashing function generates collisions, and implement the right defense against such cases.
Case in point, let’s try to use a hash() function that generates a lot of collisions:
This function uses an array of 10 elements to store values, meaning that elements are likely to be replaced — a nasty bug in our DumbMap:
In order to resolve the issue, we can simply store multiple key-value pairs at the same index. So let’s amend our hash table:
As you might notice, here we fall back to our original implementation: store a list of key-value pairs and loop through each of them. This is going to be quite slow when there are a lot of collisions for a particular index of the list.
Let’s benchmark this using our own hash() function that generates indexes from 1 to 10:
with lots of records in the map: 11.919ms
and by using the hash function from string-hash, which generates random indexes:
with lots of records in the map: 0.014ms
Whoa! There’s the cost of picking the right hashing function — fast enough that it doesn’t slow our execution down on its own, and good enough that it doesn’t produce a lot of collisions.
Generally O(1)
Remember my words?
Hashtables have a
O(1)complexity
Well, I lied: the complexity of a hash table depends on the hashing function you pick. The more collisions you generate, the more the complexity tends toward O(n).
A hashing function such as:
function hash(key) { return 0}
would mean that our hash table has a complexity of O(n).
This is why, in general, computational complexity has three measures: best, average, and worst-case scenarios. Hashtables have a O(1) complexity in best and average case scenarios, but fall to O(n)in their worst-case scenario.
Remember: a good hashing function is the key to an efficient hash table — nothing more, nothing less.
More on collisions…
The technique we used to fix DumbMap in case of collisions is called separate chaining: we store all the key-pairs that generate collisions in a list and loop through them.
Another popular technique is open addressing:
- at each index of our list we store one and one only key-value pair
- when trying to store a pair at index
x, if there’s already a key-value pair, try to store our new pair atx + 1 - if
x + 1is taken, tryx + 2and so on… - when retrieving an element, hash the key and see if the element at that position (
x) matches our key - if not, try to access the element at position
x + 1 - rinse and repeat until you get to the end of the list, or when you find an empty index — that means our element is not in the hash table
Smart, simple, elegant and usually very efficient!
FAQs (or TL;DR)
Does a hash table hash the values we’re storing?
No, keys are hashed so that they can be turned into an integer i, and both keys and values are stored at position i in a list.
Do the hashing functions used by hash tables generate collisions?
Absolutely — so hash tables are implemented with defense strategies to avoid nasty bugs.
Do hash tables use a list or a linked list internally?
It depends, both can work. In our examples, we use the JavaScript array ([]) that can be dynamically resized:
> a = []
> a[3] = 1
> a[ <3 empty items>, 1 ]
Why did you pick JavaScript for the examples? JS arrays ARE hash tables!
For example:
> a = [][]
> a["some"] = "thing"'thing'
> a[ some: 'thing' ]
> typeof a'object'
I know, damn JavaScript.
JavaScript is “universal” and probably the easiest language to understand when looking at some sample code. JS might not be the best language, but I hope these examples are clear enough.
Is your example a really good implementation of a hash table? Is it really THAT simple?
No, not at all.
Have a look at “implementing a hash table in JavaScript” by Matt Zeunert, as it will give you a bit more context. There’s a lot more to learn, so I would also suggest that you check out:
- Paul Kube’s course on hash tables
- Implementing our Own Hash Table with Separate Chaining in Java
- Algorithms, 4th Edition — Hash tables
- Designing a fast hash table
In the end…
Hash tables are a very clever idea we use on a regular basis: no matter whether you create a dictionary in Python, an associative array in PHP or a Map in JavaScript. They all share the same concepts and beautifully work to let us store and retrieve element by an identifier, at a (most likely) constant cost.
Hope you enjoyed this article, and feel free to share your feedback with me.
A special thanks goes to Joe who helped me by reviewing this article.
Adios!