
By Andrea Santurbano
This article is the second part of the Leveraging Neo4j Streams series (Part 1 is here). I’ll show how to bring Neo4j into your Apache Kafka flow by using the Sink module of the Neo4j Streams project in combination with Apache Spark’s Structured Streaming Apis.

In order to show how to integrate them, simplify the integration, and let you test the whole project yourself, I’ll use Apache Zeppelin — a notebook runner that simply allows you to natively interact with Neo4j.
Leveraging Neo4j Streams
The Neo4j Streams project is composed of three main pillars:
- The Change Data Capture that allows you to stream database changes over Kafka topics
- The Sink (the subject of the first article) that allows consuming data streams from Kafka topics
- A set of procedures that allows you to Produce/Consume data to/from Kafka Topics
The Neo4j Streams Sink
This module allows Neo4j to consume data from a Kafka topic. It does it in a “smart” way: by allowing you to define your custom queries. What you need to do is write in your neo4j.conf something like this:
streams.sink.topic.cypher.<TOPIC>=<CYPHER_QUERY>
So if you define a query just like this:
streams.sink.topic.my-topic=MERGE (n:Person{id: event.id}) \
ON CREATE SET n += event.properties
And for events like this:
{id:"alice@example.com",properties:{name:"Alice",age:32}}
Under the hood the Sink module will execute a query like this:
UNWIND {batch} AS event
MERGE (n:Label {id: event.id})
ON CREATE SET n += event.properties
The batch parameter is a set of Kafka events that are gathered from the SINK and processed in a single transaction in order to maximize the execution efficiency.
So continuing with the example above, a possible full representation could be:
WITH [{id:"alice@example.com",properties:{name:"Alice",age:32}},
{id:"bob@example.com",properties:{name:"Bob",age:42}}] AS batch
UNWIND batch AS event
MERGE (n:Person {id: event.id})
ON CREATE SET n += event.properties
This gives to the developer the power to define their own business rules because you can choose to update, add to, remove, or adapt your graph data based on the events you get.
A simple use case: Ingest data from Open Data APIs
Imagine your data pipeline needs to read data from an Open Data API, enrich it with some other internal source, and in the end persist it into Neo4j. In this case, the best solution for doing this is using Apache Spark. This easily allows managing different data sources with the same Dataset abstraction.
Set-Up the Environment
Going to the following Github repo, you’ll find the whole code necessary in order to replicate what I’m presenting in this article. What you will need to start is Docker, and then you can simply spin up the stack by entering the directory and executing the following command from the terminal:
$ docker-compose up
This will start up the whole environment that comprises:
- Neo4j + Neo4j Streams module + APOC procedures
- Apache Kafka
- Apache Spark
- Apache Zeppelin
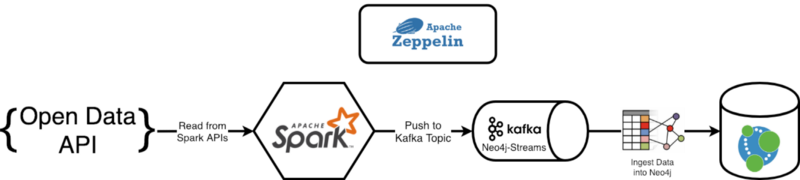
By going into Apache Zeppelin @ http://localhost:8080 you’ll find in the directory Medium/Part 2 one notebook “From Open Data to Sink” which is the subject of this article.
The Open Data API
We’ll choose the Italian Ministry of Health dataset of Pharmacy stores.
Define the Sink Query
If you go into the [d](http://localhost:8080)ocker-compose.yml file you’ll find a new property that corresponds to the Sink query definition:
NEO4J_streams_sink_topic_cypher_pharma: "
MERGE (p:Pharmacy{fiscalId: event.FISCAL_ID}) ON CREATE SET p.name = event.NAME
MERGE (t:PharmacyType{type: event.TYPE_NAME})
MERGE (a:Address{name: event.ADDRESS + ', ' + event.CITY})
ON CREATE SET a.latitude = event.LATITUDE,
a.longitude = event.LONGITUDE,
a.code = event.POSTAL_CODE,
a.point = event.POINT
MERGE (c:City{name: event.CITY})
MERGE (p)-[:IS_TYPE]-(t)
MERGE (p)-[:HAS_ADDRESS]-(a)
MERGE (a)-[:IS_LOCATED_IN]->(c)"
The NEO4J_streams_sink_topic_cypher_pharma property defines that all the data that comes from a topic named pharma will be consumed with the corresponding query.
The graph model that results from the query above is:
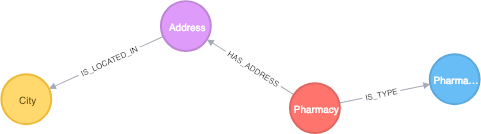
The Notebook — From Open Data to Sink
The first step is download the CSV from the Open Data Portal and load it into a Spark Dataframe:
val fileUrl = z.input("File Url").toString
val url = new java.net.URL(fileUrl)
val localFilePath = s"/zeppelin/spark-warehouse/${url.getPath.split("/").last}"
val src = scala.io.Source.fromURL(fileUrl)("ISO-8859-1")
val out = new java.io.FileWriter(localFilePath)
out.write(src.mkString)
out.close
val csvDF = (spark.read
.format("csv")
.option("delimiter", ";")
.option("header", "true")
.load(localFilePath))
Now let’s explore the structure of the csvDF:
root
|-- CODICEIDENTIFICATIVOFARMACIA: string (nullable = true)
|-- CODFARMACIAASSEGNATODAASL: string (nullable = true)
|-- INDIRIZZO: string (nullable = true)
|-- DESCRIZIONEFARMACIA: string (nullable = true)
|-- PARTITAIVA: string (nullable = true)
|-- CAP: string (nullable = true)
|-- CODICECOMUNEISTAT: string (nullable = true)
|-- DESCRIZIONECOMUNE: string (nullable = true)
|-- FRAZIONE: string (nullable = true)
|-- CODICEPROVINCIAISTAT: string (nullable = true)
|-- SIGLAPROVINCIA: string (nullable = true)
|-- DESCRIZIONEPROVINCIA: string (nullable = true)
|-- CODICEREGIONE: string (nullable = true)
|-- DESCRIZIONEREGIONE: string (nullable = true)
|-- DATAINIZIOVALIDITA: string (nullable = true)
|-- DATAFINEVALIDITA: string (nullable = true)
|-- DESCRIZIONETIPOLOGIA: string (nullable = true)
|-- CODICETIPOLOGIA: string (nullable = true)
|-- LATITUDINE: string (nullable = true)
|-- LONGITUDINE: string (nullable = true)
|-- LOCALIZE: string (nullable = true)
We want to focus on two fields:
- CODICEIDENTIFICATIVOFARMACIA: it “should” be the unique identifier given by the Italian Ministry of Health to a Pharmacy Store
- DATAFINEVALIDITA: it indicates if the Pharmacy Store is still active (if it has no value it is active, otherwise it is closed)
We now save the Dataframe into a Spark temp view called OPEN_DATA:
csvDF.createOrReplaceTempView("open_data")
Let’s now overwrite the OPEN_DATA temp view by filtering the dataset for valid records and renaming some fields:
%sql
CREATE OR REPLACE TEMP VIEW OPEN_DATA AS
SELECT CODICEIDENTIFICATIVOFARMACIA AS PHARMA_ID,
INDIRIZZO AS ADDRESS,
DESCRIZIONEFARMACIA AS NAME,
PARTITAIVA AS FISCAL_ID,
CAP AS POSTAL_CODE,
DESCRIZIONECOMUNE AS CITY,
DESCRIZIONEPROVINCIA AS PROVINCE,
DATAFINEVALIDITA,
DESCRIZIONETIPOLOGIA AS TYPE_NAME,
CODICETIPOLOGIA AS TYPE,
REPLACE(LATITUDINE, ‘,’, ‘.’) AS LATITUDE,
REPLACE(LONGITUDINE, ‘,’, ‘.’) AS LONGITUDE,
REPLACE(LATITUDINE, ‘,’, ‘.’) || ‘,’ || REPLACE(LONGITUDINE, ‘,’, ‘.’) AS POINT
FROM OPEN_DATA
WHERE DATAFINEVALIDITA <> ‘-’
AND CODICEIDENTIFICATIVOFARMACIA <> ‘-’
Let’s now create the OPEN_DATA_KAFKA_STAGE temp view that must contain two columns:
- VALUE: JSON that represents the data that we want to send to the Kafka topic
- KEY: a key that identifies the row
You may notice that this is exactly the minimum requirement for a ProducerRecord:
%sql
CREATE OR REPLACE TEMP VIEW OPEN_DATA_KAFKA_STAGE AS
SELECT TO_JSON(
STRUCT(PHARMA_ID,
ADDRESS,
NAME,
FISCAL_ID,
POSTAL_CODE,
CITY,
PROVINCE,
TYPE_NAME,
TYPE,
LATITUDE,
LONGITUDE,
POINT)
) AS VALUE,
PHARMA_ID AS KEY
FROM OPEN_DATA
Let’s now send the data to the pharma topic via spark:
(spark.table("OPEN_DATA_KAFKA_STAGE").selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.write
.format("kafka")
.option("kafka.enable.auto.commit", "true")
.option("kafka.bootstrap.servers", "broker:9093")
.option("topic", "pharma")
.save())
The data streamed to the pharma topic via the spark job will now be consumed from the Neo4j Streams Sink module thanks to the Cypher template that we defined at the beginning of the article.
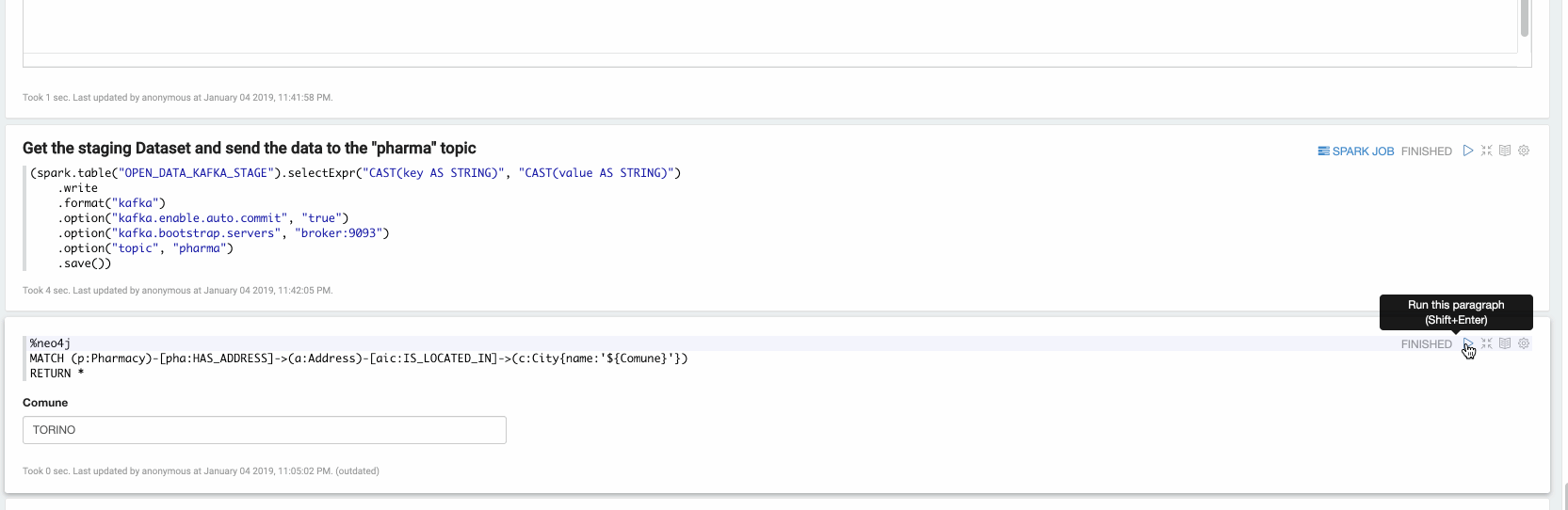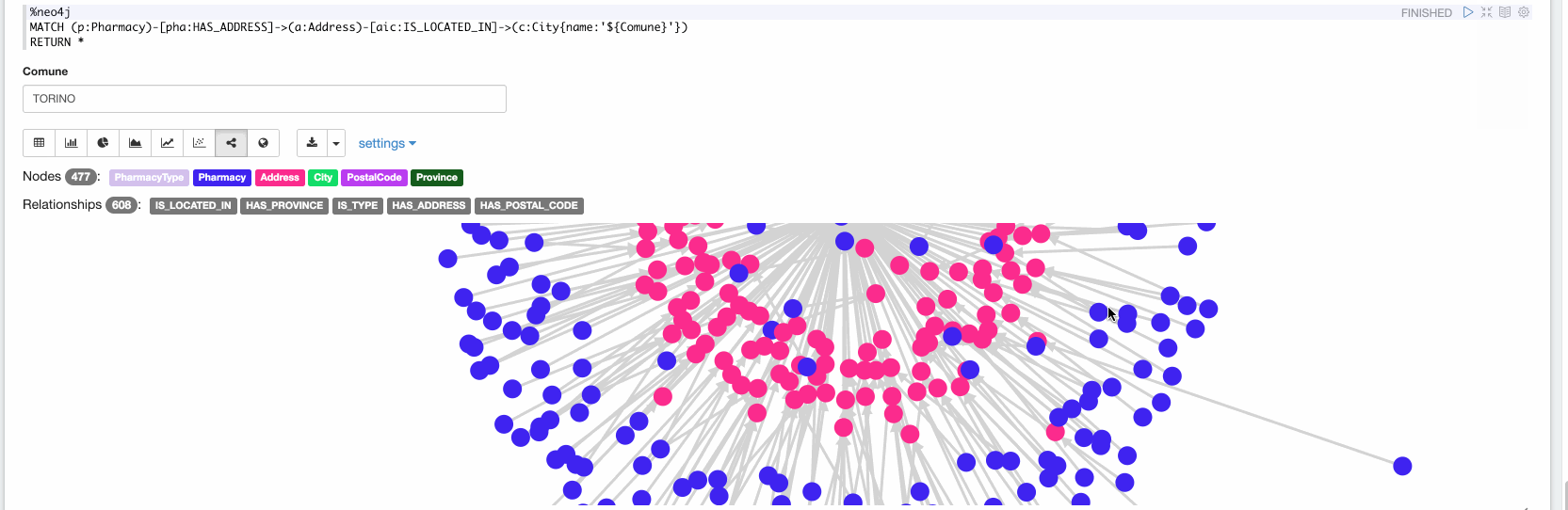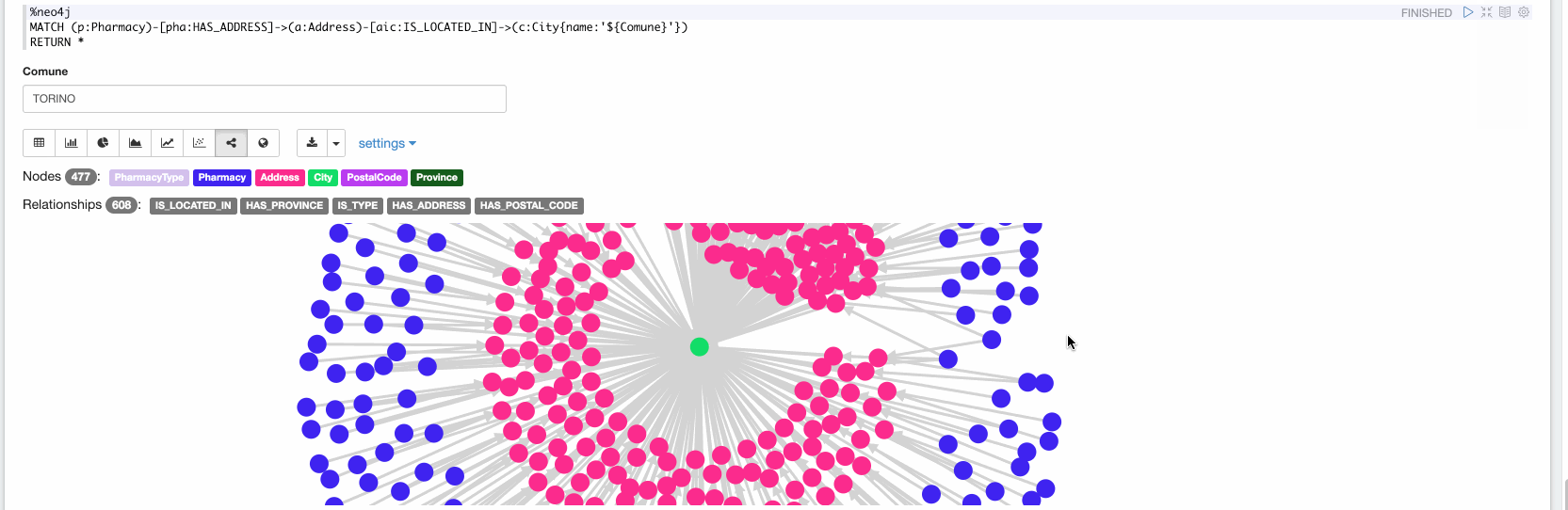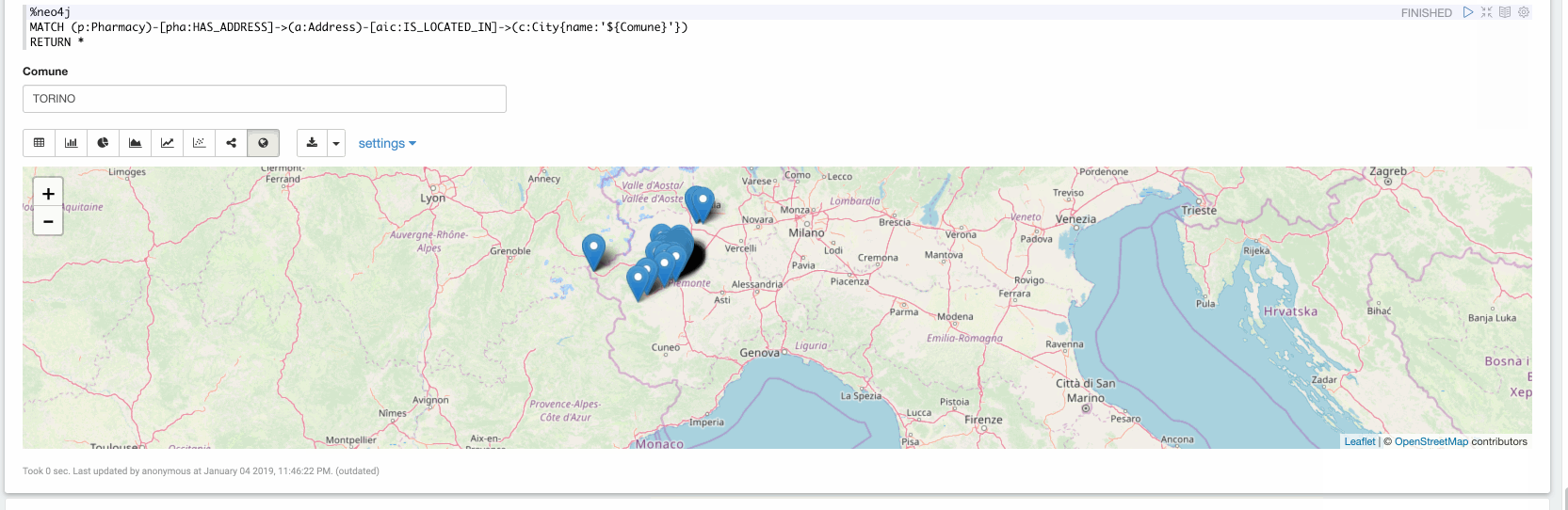
Now in the final paragraph, we can explore the ingested data. In the following video we are exploring all the Pharmacy stores located in Turin:
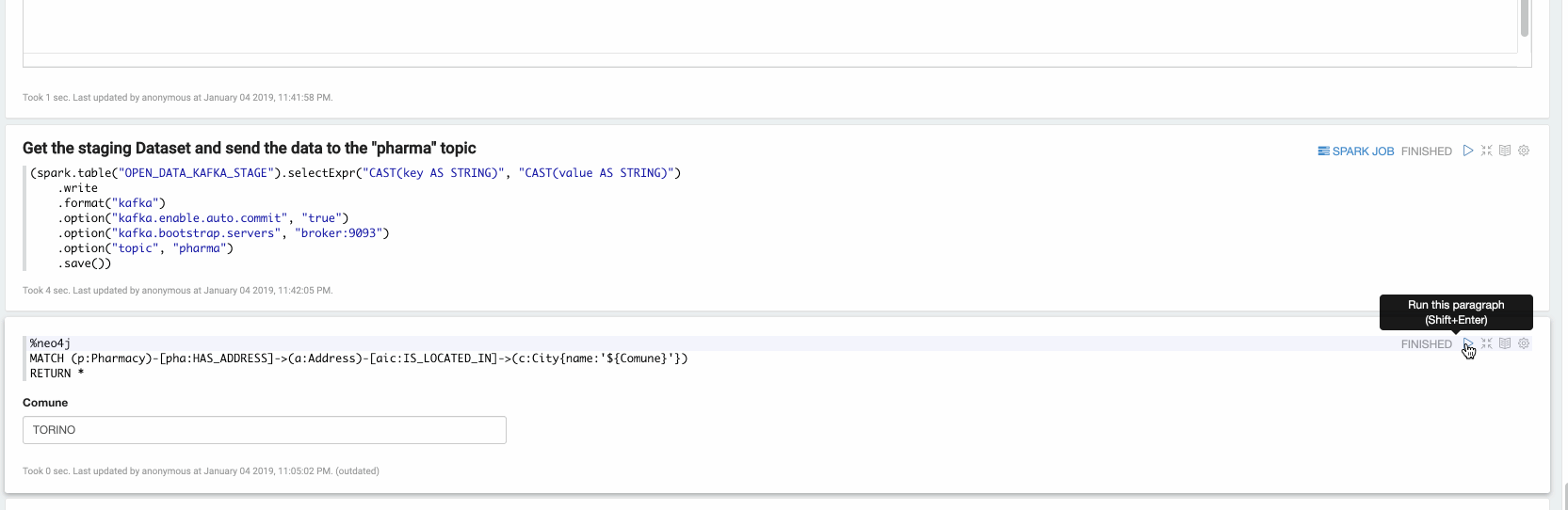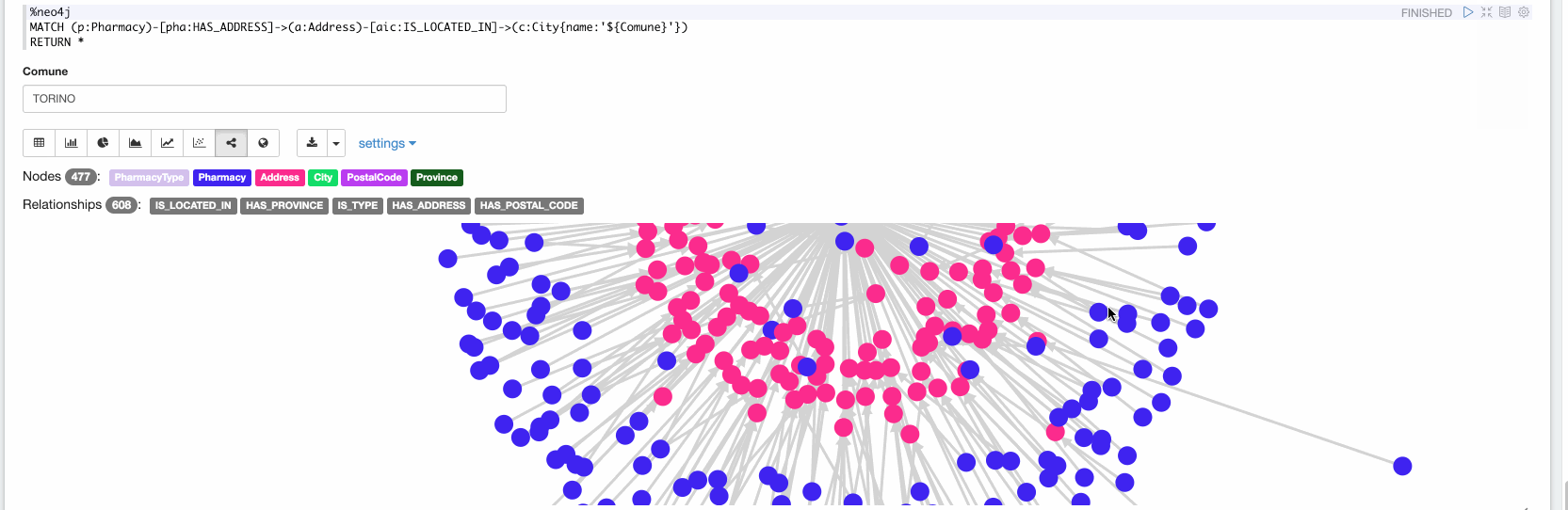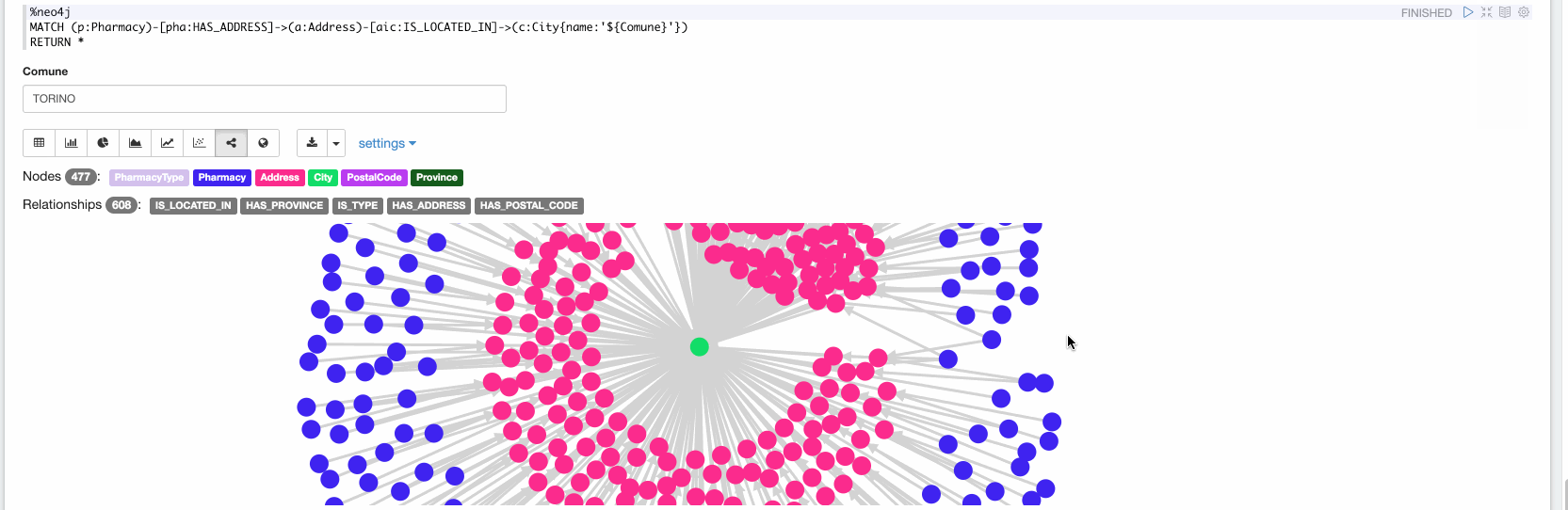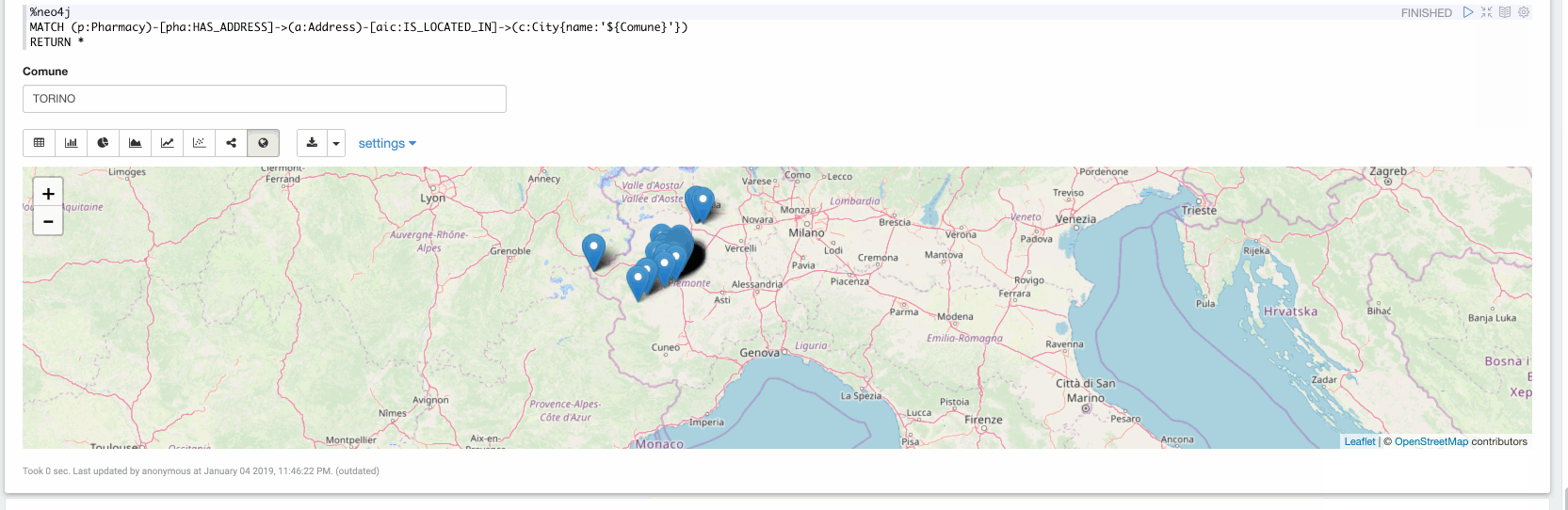
Wrapping up
In this second article (please check the first one if you haven’t already) we have seen how to use the SINK module in order to transform Apache Kafka events into arbitrary Graph Structures. You can do it in a very simple way by using the Apache Spark APIs.
In Part 3 we’ll discover how to use the Streams procedure in order to produce/consume data directly via Cypher queries, so please stay tuned!
If you have already tested the Neo4j-Streams module or tested it via this notebook please fill out our feedback survey.
If you run into any issues or have thoughts about improving our work, please raise a GitHub issue.