
By Andrea Santurbano
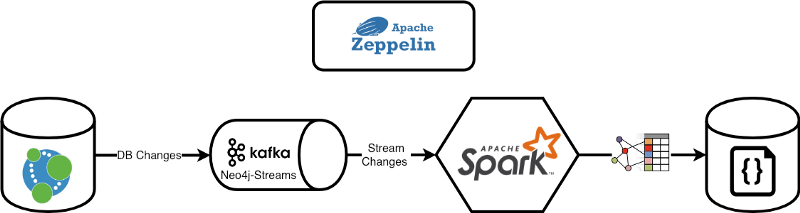
In this article, we’ll show how to create a Just-In-Time Data Warehouse by using Neo4j and the Neo4j Streams module with Apache Spark’s Structured Streaming Apis and Apache Kafka.
In order to show how to integrate them, simplify the integration, and let you test the whole project by hand, I’ll use Apache Zeppelin a notebook runner that simply allows to natively interact with Neo4j.
Leveraging Neo4j Streams
The Neo4j Streams project is composed of three main pillars:
- The Change Data Capture (the subject of this first article) that allows us to stream database changes over Kafka topics
- The Sink that allows consuming data streams from the Kafka topic
- A set of procedures that allows us to Produce/Consume data to/from Kafka Topics
What is a Change Data Capture?
It’s a system that automatically captures changes from a source system (a Database, for instance) and automatically provides these changes to downstream systems for a variety of use cases.
CDC typically forms part of an ETL pipeline. This is an important component for ensuring Data Warehouses (DWH) are kept up to date with any record changes.
Also traditionally CDC applications used to work off of transaction logs, thereby allowing us to replicate databases without having much of a performance impact on its operation.
How does the Neo4j Streams CDC module deal with database changes?
Every transaction inside Neo4j gets captured and transformed in order to stream an atomic element of the transaction.
Let’s suppose we have a simple creation of two nodes and one relationship between them:
CREATE (andrea:Person{name:"Andrea"})-[knows:KNOWS{since:2014}]->(michael:Person{name:"Michael"})
The CDC module will transform this transaction into 3 events (2 node creation, 1 relationship creation).
The Event structure was inspired by the Debezium format and has the following general structure:
{ "meta": { /* transaction meta-data */ }, "payload": { /* the data related to the transaction */ "before": { /* the data before the transaction */}, "after": { /* the data after the transaction */} }}
Node source (andrea):
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 0, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1004", "type": "node", "after": { "labels": ["Person"], "properties": { "name": "Andrea" } } }}
Node target (michael):
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 1, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1006", "type": "node", "after": { "labels": ["Person"], "properties": { "name": "Michael" } } }}
Relationship knows:
{ "meta": { "timestamp": 1532597182604, "username": "neo4j", "tx_id": 1, "tx_event_id": 2, "tx_events_count": 3, "operation": "created", "source": { "hostname": "neo4j.mycompany.com" } }, "payload": { "id": "1007", "type": "relationship", "label": "KNOWS", "start": { "labels": ["Person"], "id": "1005" }, "end": { "labels": ["Person"], "id": "106" }, "after": { "properties": { "since": 2014 } } }}
By default, all the data will be streamed on the neo4j topic. The CDC module allows controlling which nodes are sent to Kafka, and which of their properties you want to send to the topic:
streams.source.topic.nodes.<TOPIC_NAME>=<PATTERN>
With the following example:
streams.source.topic.nodes.products=Product{name, code}
The CDC module will send to the products topic all the nodes that have the label Product. It then sends, to that topic, only the changes about name and code properties. Please go the official documentation for a full description on how label filtering works.
For a more in-depth description of the Neo4j Streams project and how/why we at LARUS and Neo4j built it, check out this article that provides an in-depth description.
Beyond the traditional Data Warehouse
A traditional DWH requires data teams to constantly build multiple costly and time-consuming Extract Transform Load (ETL) pipelines to ultimately derive business insights.
One of the biggest pain points is that, due to its rigid architecture that’s difficult to change, Enterprise Data Warehouses are inherently rigid. That’s because:
- they are based on the Schema-On-Write architecture: first, you define your schema, then you write your data, then you read your data and it comes back in the schema you defined up-front
- they are based on (expensive) batched/scheduled jobs
This results in having to build costly and time-consuming ETL pipelines to access and manipulate the data. And as new data types and sources are introduced, the need to augment your ETL pipelines exacerbates the problem.
Thanks to the combination of the stream data processing with the Neo4j Streams CDC module and the Schema-On-Read approach provided by Apache Spark, we can overcome this rigidity and build a new kind of (flexible) DWH.
A paradigm shift: Just-In-Time Data Warehouse
A JIT-DWH solution is designed to easily handle a wider variety of data from different sources and starts from a different approach about how to deal with and manage data: Schema-On-Read.
Schema-On-Read
Schema-On-Read follows a different sequence: it just loads the data as-is and applies your own lens to the data when you read it back out. With this kind of approach, you can present data in a schema that is adapted best to the queries being issued. You’re not stuck with a one-size-fits-all schema. With schema-on-read, you can present the data back in a schema that is most relevant to the task at hand.
Set-Up the Environment
Going to the following Github repo you’ll find everything you need in order to replicate what I’m presenting in this article. What you will need to start is Docker. Then you can simply spin-up the stack by entering into the directory and from the Terminal, executing the following command:
$ docker-compose up
This will start-up the whole environment that comprises:
- Neo4j + Neo4j Streams module + APOC procedures
- Apache Kafka
- Apache Spark
- Apache Zeppelin
By going into Apache Zeppelin @ http://localhost:8080 you’ll find in the directory Medium/Part 1 two notebooks:
- Create a Just-In-Time Data Warehouse: in this notebook, we will build the JIT-DWH
- Query The JIT-DWH: in this notebook, we will perform some queries over the JIT-DWH
The Use-Case:
We’ll create a fake social network like dataset. This will activate the CDC module of Neo4j Stream, and via Apache Spark we’ll intercept this event and persist them on the File System as JSON.
Then we’ll demonstrate how new fields added in our nodes will be automatically added to our JIT-DWL without the modification of the ETL pipeline, thanks to the Schema-On-Read approach.
We’ll execute the following steps:
- Create the fake data set
- Build our data pipeline that intercepts the Kafka events published by the Neo4j Streams CDC module
- Make the first query over our JIT-DWH on Spark
- Add a new field in our graph model
- Show how the new field is automatically exposed in real time thanks to the Neo4j Streams CDC module (without the need for changes over our ETL pipeline thanks to the Schema-On-Read approach).
Notebook 1: Create a Just-In-Time Data Warehouse
We’ll create a fake social network by using the APOC apoc.periodic.repeat procedure that executes this query every 15 seconds:
WITH ["M", "F", ""] AS genderUNWIND range(1, 10) AS idCREATE (p:Person {id: apoc.create.uuid(), name: "Name-" + apoc.text.random(10), age: round(rand() * 100), index: id, gender: gender[toInteger(size(gender) * rand())]})WITH collect(p) AS peopleUNWIND people AS p1UNWIND range(1, 3) AS friendWITH p1, people[(p1.index + friend) % size(people)] AS p2CREATE (p1)-[:KNOWS{years: round(rand() * 10), engaged: (rand() > 0.5)}]->(p2)
If you need more details about the APOC project, please follow this link.
So the resulting graph model is quite straightforward:

Let’s create an index over the Person node:
%neo4jCREATE INDEX ON :Person(id)
Now let’s set the Background Job in Neo4j:
%neo4jCALL apoc.periodic.repeat('create-fake-social-data', 'WITH ["M", "F", "X"] AS gender UNWIND range(1, 10) AS id CREATE (p:Person {id: apoc.create.uuid(), name: "Name-" + apoc.text.random(10), age: round(rand() * 100), index: id, gender: gender[toInteger(size(gender) * rand())]}) WITH collect(p) AS people UNWIND people AS p1 UNWIND range(1, 3) AS friend WITH p1, people[(p1.index + friend) % size(people)] AS p2 CREATE (p1)-[:KNOWS{years: round(rand() * 10), engaged: (rand() > 0.5)}]->(p2)', 15) YIELD nameRETURN name AS created
This background query brings the Neo4j-Streams CDC module to stream related events over the “neo4j” Kafka topic (the default topic of the CDC).
Now let’s create a Structured Streaming Dataset that consumes the data from the “neo4j” topic:
val kafkaStreamingDF = (spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "broker:9093") .option("startingoffsets", "earliest") .option("subscribe", "neo4j") .load())
The kafkaStreamingDF Dataframe is basically a ProducerRecord representation. And in fact its schema is:
root|-- key: binary (nullable = true)|-- value: binary (nullable = true)|-- topic: string (nullable = true)|-- partition: integer (nullable = true)|-- offset: long (nullable = true)|-- timestamp: timestamp (nullable = true)|-- timestampType: integer (nullable = true)
Now let’s create the Structure of the data streamed by the CDC using the Spark APIs in order to read the streamed data:
val cdcMetaSchema = (new StructType() .add("timestamp", LongType) .add("username", StringType) .add("operation", StringType) .add("source", MapType(StringType, StringType, true))) val cdcPayloadSchemaBeforeAfter = (new StructType() .add("labels", ArrayType(StringType, false)) .add("properties", MapType(StringType, StringType, true))) val cdcPayloadSchema = (new StructType() .add("id", StringType) .add("type", StringType) .add("label", StringType) .add("start", MapType(StringType, StringType, true)) .add("end", MapType(StringType, StringType, true)) .add("before", cdcPayloadSchemaBeforeAfter) .add("after", cdcPayloadSchemaBeforeAfter)) val cdcSchema = (new StructType() .add("meta", cdcMetaSchema) .add("payload", cdcPayloadSchema))
The cdcSchema is suitable for both node and relationships events.
What we need now is to extract only the CDC event from the Dataframe, so let’s perform a simple transformation query over Spark:
val cdcDataFrame = (kafkaStreamingDF .selectExpr("CAST(value AS STRING) AS VALUE") .select(from_json('VALUE, cdcSchema) as 'JSON))
The cdcDataFrame contains just one column JSON which is the data streamed from the Neo4j-Streams CDC module.
Let’s perform a simple ETL query in order to extract fields of interest:
val dataWarehouseDataFrame = (cdcDataFrame .where("json.payload.type = 'node' and (array_contains(nvl(json.payload.after.labels, json.payload.before.labels), 'Person'))") .selectExpr("json.payload.id AS neo_id", "CAST(json.meta.timestamp / 1000 AS Timestamp) AS timestamp", "json.meta.source.hostname AS host", "json.meta.operation AS operation", "nvl(json.payload.after.labels, json.payload.before.labels) AS labels", "explode(json.payload.after.properties)"))
This query is quite important, because it represents how the data will be persisted over the filesystem. Every node will be exploded in a number of JSON snippets, one for each node property, just like this:
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"name","value":"Name-5wc62uKO5l"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"index","value":"8"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"id","value":"944e58bf-0cf7-49cf-af4a-c803d44f222a"}
{"neo_id":"35340","timestamp":"2018-12-19T23:07:10.465Z","host":"neo4j","operation":"created","labels":["Person"],"key":"gender","value":"F"}
This kind of structure can be easily turned into tabular representation (we’ll see in the next few steps how to do this).
Now let's write a Spark continuous streaming query that saves the data to the file system as JSON:
val writeOnDisk = (dataWarehouseDataFrame .writeStream .format("json") .option("checkpointLocation", "/zeppelin/spark-warehouse/jit-dwh/checkpoint") .option("path", "/zeppelin/spark-warehouse/jit-dwh") .queryName("nodes") .start())
We have now created a simple JIT-DWH. In the second notebook we’ll learn how to query it and how simple it is to deal with dynamical changes in the data structures thanks schema-on-read.
Notebook 2: Query The JIT-DWH
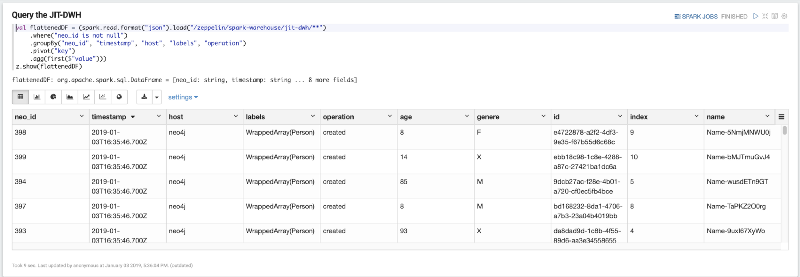
The first paragraph let us query and display our JIT-DWH
val flattenedDF = (spark.read.format("json").load("/zeppelin/spark-warehouse/jit-dwh/**") .where("neo_id is not null") .groupBy("neo_id", "timestamp", "host", "labels", "operation") .pivot("key") .agg(first($"value")))z.show(flattenedDF)
Remember how we saved the data in JSON some row above? The flattenedDF simply pivoted the JSONs over the key field thus grouping the data over 5 columns that represent the “unique key” (_“neoid”, “timestamp”, “host”, “labels”, “operation”). This allows us to have this tabular representation of the source data as follows:
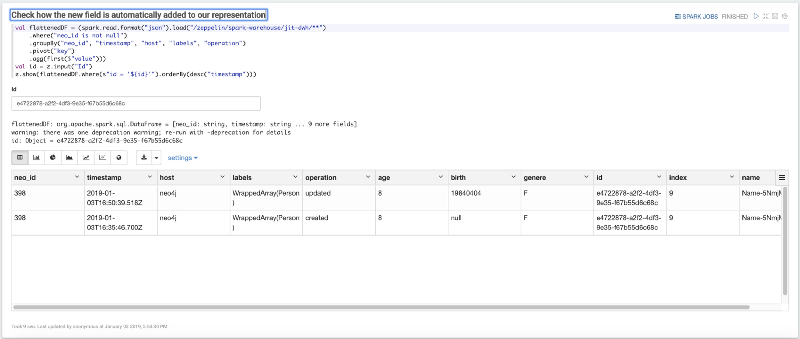
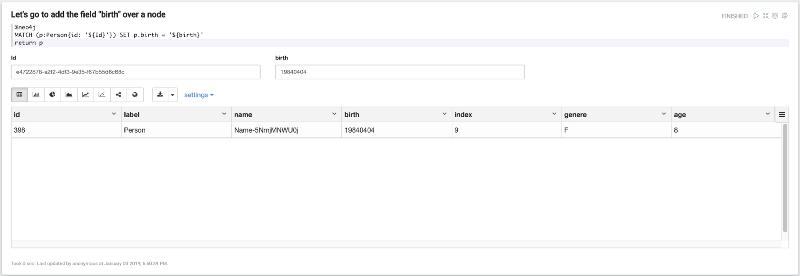
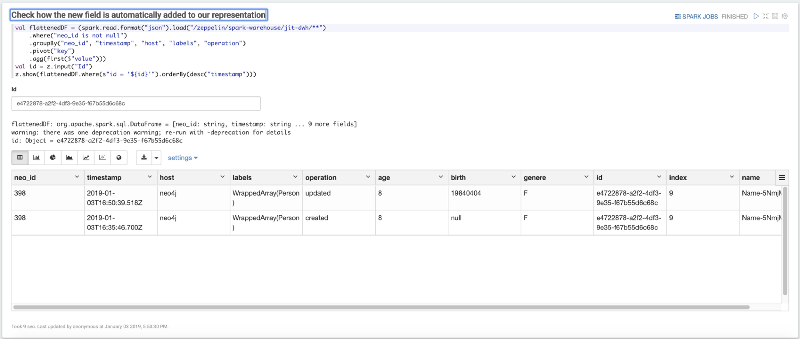
Now imagine that our Person dataset gets a new field: birth. Let's add this new field to one node; in this case, you must choose an id from your dataset and update it with the following paragraph:
Now the final step: reuse the same query and filter the DWH by the id that we have previously changed in order to check how our dataset changed according to the changes made over Neo4j.
Conclusions
In this first part, we learned how to leverage the events produced by Neo4j Stream CDC module in order to build a simple (Real-Time) JIT-DWL that uses the Schema-On-Read approach.
In Part 2 we’ll discover how to use the Sink module in order to ingest data into Neo4j directly from Kafka.
If you have already tested the Neo4j-Streams module or tested it via these notebooks please fill out our feedback survey.
If you run into any issues or have thoughts about improving our work, please raise a GitHub issue.