
By Luca Matteis
Functional reactive programming (FRP) is a paradigm that has gained lots of attention lately, especially in the JavaScript front end world. It’s an overloaded term, but it describes a simple idea:
Everything should be pure so it’s easy to test and reason about (functional), and async behavior should be modeled using values that change over time (reactive).
React in itself is not fully functional, nor is it fully reactive. But it is inspired by some of the concepts behind FRP. Functional components for instance are pure functions with respect to their props. And they are reactive to prop or state changes.
But when it comes to handling side effects, React — being only the view layer — needs help from other libraries, such as Redux.
In this article I’ll talk about redux-cycles, a Redux middleware that helps you to handle side effects and async code in your React apps in a functional-reactive way — a trait which is not yet shared by other Redux side effect models — by leveraging the Cycle.js framework.
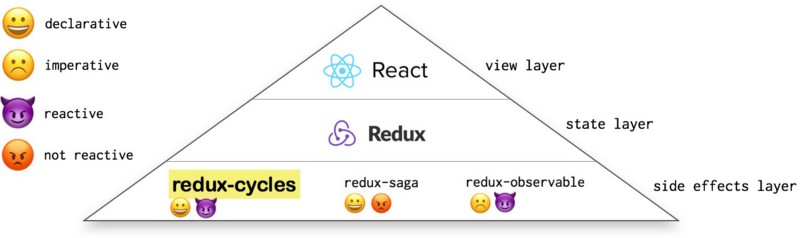
What are side effects?
A side effect modifies the outside world. Everything in your app that deals with making HTTP requests, writing to localStorage, or even manipulating the DOM, is considered a side effect.
Side effects are bad. They are hard to test, complicated to maintain, and generally they are where most of your bugs lie. Your goal is therefore to minimize/localize them.

“In the presence of side effects, a program’s behavior depends on past history; that is, the order of evaluation matters. Because understanding an effectful program requires thinking about all possible histories, side effects often make a program harder to understand.” — Norman Ramsey
Here are several popular ways to handle side effects in Redux:
- redux-thunk — puts your side effects code inside action creators
- redux-saga — makes your side effects logic declarative using sagas
- redux-observable — uses reactive programming to model side effects
The problem is that none of these are both pure and reactive. Some of them are pure (redux-saga) while others are reactive (redux-observable), but none of them share all of the concepts we introduced earlier about FRP.
Redux-cycles is both pure and reactive.

We’ll first explain in more details these functional and reactive concepts — and why you should care. We’ll then explain how redux-cycles works in detail.
Pure side effects handling with Cycle.js
An HTTP request is probably the most common side effect. Here’s an example of an HTTP request using redux-thunk:
function fetchUser(user) { return (dispatch, getState) => fetch(`https://api.github.com/users/${user}`)}
This function is imperative. Yes it’s returning a promise and you can chain it together with other promises, but fetch() is doing a call, at that specific moment in time. It is not pure.
The same applies to redux-observable:
const fetchUserEpic = action$ => action$.ofType(FETCH_USER) .mergeMap(action => ajax.getJSON(`https://api.github.com/users/${action.payload}`) .map(fetchUserFulfilled) );
ajax.getJSON() makes this snippet of code imperative.
To make an HTTP request pure, you shouldn’t think about “make an HTTP request now” but rather “let me describe how I want my HTTP request to look like” and not worry about when it actually happens or who makes it.
In Cycle.js this is essentially how you code all things. Everything you do with the framework is about creating descriptions about what you want to do. These descriptions are then sent to these things called drivers (via reactive streams) which actually take care of making the HTTP request:
function main(sources) { const request$ = xs.of({ url: `https://api.github.com/users/foo`, });
return { HTTP: request$ };}
As you can see from this snippet of code, there’s no function call to actually make the request. If you run this code you’ll see the request happen regardless. So what’s actually happening behind the scenes?
The magic happens thanks to drivers. Cycle.js knows that when your function returns an object with an HTTP key, it needs to handle the messages that it receives from this stream, and perform an HTTP request accordingly (via an HTTP driver).
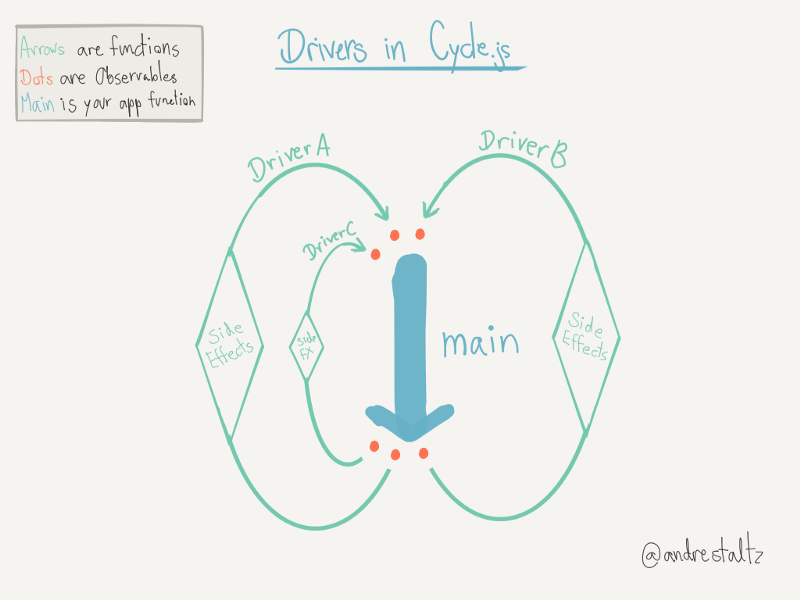
The key point is that you didn’t get rid of the side effect — the HTTP request still needs to happen — but you localized it outside of your application code.
Your functions are much easier to reason about, and are especially much easier to test because you can simply test whether your functions emit the right messages — no weird mocking or timing needed.
Reactive side effects
In the earlier examples we touched on reactivity. There needs to be a way to communicate with these so called drivers about “doing things in the outside world” and be notified about “things that happen in the outside world”.
Observables (aka streams) are the perfect abstraction for this sort of async communication.
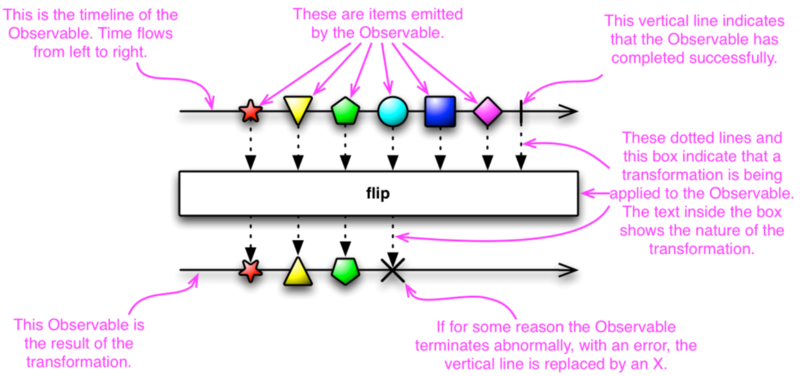
Whenever you want to “do something” you emit to an output stream a description of what you want to do. These output streams are called sinks in the Cycle.js world.
Whenever you want to “be notified about something that happened” you use an input stream (called sources) and simply map over the stream values to learn about what happened.
This forms a sort of reactive loop which requires a different thinking to understand than normal imperative code. Let’s model an HTTP request/response lifecycle using this paradigm:
function main(sources) { const response$ = sources.HTTP .select('foo') .flatten() .map(response => response);
const request$ = xs.of({ url: `https://api.github.com/users/foo`, category: 'foo', });
const sinks = { HTTP: request$ }; return sinks;}
The HTTP driver knows about the HTTP key returned by this function. It’s a stream containing an HTTP request description for a GitHub url. It’s telling the HTTP driver: “I want to make a request to this url”.
The driver then knows to perform the request, and sends the response back to the main function as a source (sources.HTTP) — note that sinks and sources use the same object key.
Let’s explain that again: we use sources.HTTP to “be notified about HTTP responses”. And we return sinks.HTTP to “make HTTP requests”.
To explain this important reactive loop here’s an animation:

This seems counter-intuitive compared to normal imperative programming: why would the code for reading the response exist before the code responsible for the request?
This is because it doesn’t matter where the code is in FRP. All you have to do is send descriptions, and listen for changes. Code order is not important.
This allows for very easy code refactoring.
Introducing redux-cycles

At this point you might be asking, what does all of this have to do with my React app?
You’ve learned about the advantages of making your code pure, by only writing descriptions of what you want to do. And you’ve learned about the advantages of using Observables to communicate with the outside world.
You’ll now see how to use these concepts within your existing React apps to, in fact, go fully functional and reactive.
Intercepting and dispatching Redux actions
With Redux you dispatch actions to tell your reducers that you want a new state.
This flow is synchronous, meaning that if you want to introduce async behavior (for side effects) you need to use some form of middleware that intercepts actions, does the async side effect, and emits other actions accordingly.
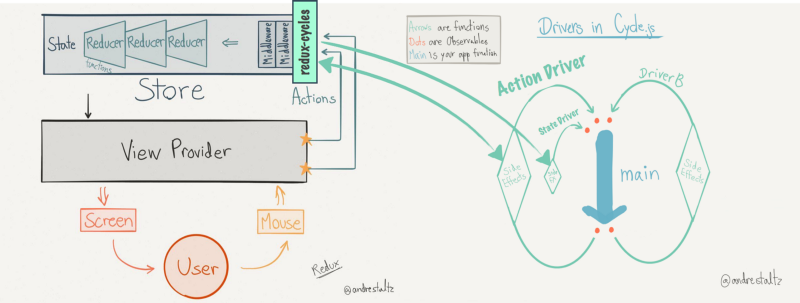
This is exactly what redux-cycles does. It’s a middleware that intercepts redux actions, enters the Cycle.js reactive loop, and allows you to perform other side effects using other drivers. It then dispatches new actions based on the async dataflow described in your functions:
function main(sources) { const request$ = sources.ACTION .filter(action => action.type === FETCH_USER) .map(action => ({ url: `https://api.github.com/users/${action.payload}`, category: 'users', })); const action$ = sources.HTTP .select('users') .flatten() .map(fetchUserFulfilled); const sinks = { ACTION: action$, HTTP: request$ }; return sinks;}
In the above example there’s a new source and sink introduced by redux-cycles — **ACTION**. But the communication paradigm is the same.
It listens to actions being dispatched from the Redux world using sources.ACTION. And it dispatches new actions to the Redux world by returning sinks.ACTION.
Specifically it emits standard Flux Actions objects.
The cool thing is that you can combine stuff happening from other drivers. In the earlier example things happening in the HTTP world actually trigger changes to the ACTION world, and vice-versa.
— Note that communicating with Redux happens entirely through the ACTION source/sink. Redux-cycles’ drivers handle the actual dispatching for you.

What about more complex apps?
How does one develop more complex apps if you’re just writing pure functions that transform streams of data?
Turns out you can do pretty much anything using already built drivers. Or you can easily build your own — here’s a simple driver which logs messages written to its sink.
run(main, { LOG: msg$ => msg$.addListener({ next: msg => console.log(msg) })});
run is part of Cycle.js, which runs your main function (first argument) and passes along all the drivers (second argument).
Redux-cycles introduces two drivers which allow you to communicate with Redux; makeActionDriver() & makeStateDriver():
import { createCycleMiddleware } from 'redux-cycles';
const cycleMiddleware = createCycleMiddleware();const { makeActionDriver, makeStateDriver } = cycleMiddleware;
const store = createStore( rootReducer, applyMiddleware(cycleMiddleware));
run(main, { ACTION: makeActionDriver(), STATE: makeStateDriver()})
makeStateDriver() is a read-only driver. This means you can only read sources.STATE in your main function. You can’t tell it what to do; you can only read data from it.
Every time the Redux state changes, thesources.STATE stream will emit the new state object. This is useful when you need to write specific logic based on the current state of the app.
Complex async data flow
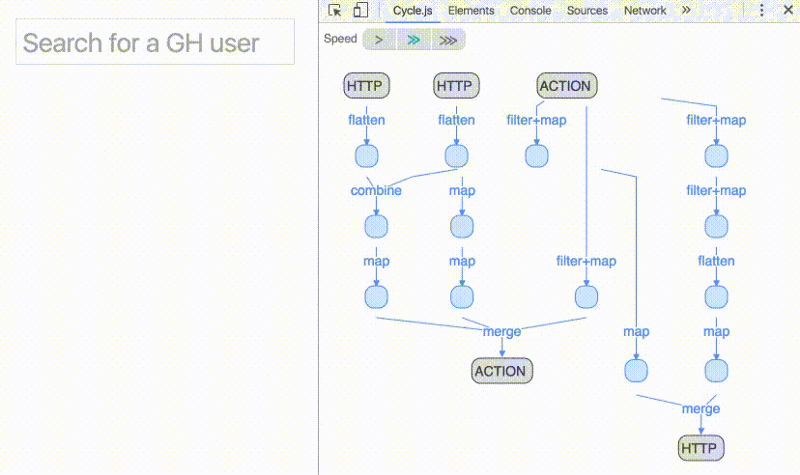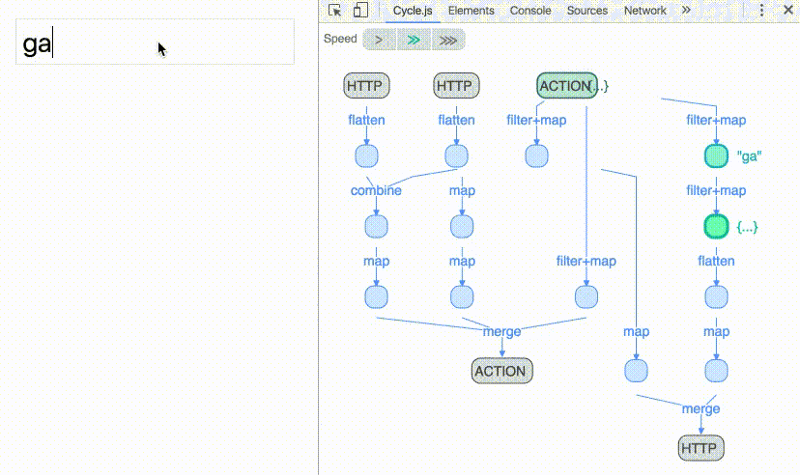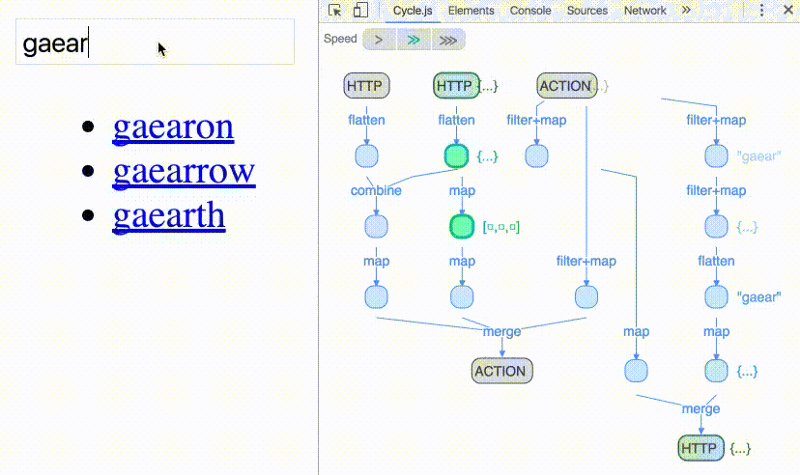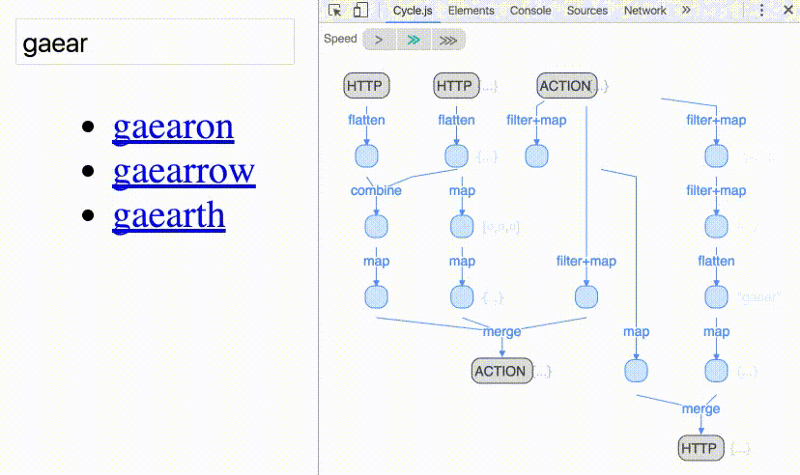
Another great advantage of reactive programming is the ability to use operators to compose streams into other streams — effectively treating them as arrays of values over time: you can [map](https://github.com/Reactive-Extensions/RxJS/blob/master/doc/gettingstarted/categories.md), filter and even reduce them.
Operators make explicit data-flow graphs possible; i.e., reasoning of dependencies between operations. Allowing you to visualize data flowing through various operators like the animation above.
Redux-observable also allows you to write complex async flows — they use a multiplex WebSocket example as their selling point — however, the power of writing these flows in a pure fashion is what really sets Cycle.js apart.
Since everything is pure dataflow we can imagine a future where programming will be nothing other than plugging together blocks of operators.
Testing with marble diagrams
Last but not least comes testing. This is where redux-cycles (and generally all Cycle.js apps) really shines.
Because everything is pure in your app code, to test your main function you simply give it streams as input and expect specific streams as output.
Using the wonderful @cycle/time project, you can even draw marble diagrams and test your functions in a very visual way:
assertSourcesSinks({ ACTION: { '-a-b-c----|': actionSource }, HTTP: { '---r------|': httpSource },}, { HTTP: { '---------r|': httpSink }, ACTION: { '---a------|': actionSink },}, searchUsers, done);
This piece of code executes the [searchUsers](https://github.com/cyclejs-community/redux-cycles/blob/master/example/cycle/index.js#L31) function, passing it specific sources as input (first argument). Given these sources it expects the function to return the provided sinks (second argument). If it doesn’t, the assertion fails.
Defining streams graphically this way is especially useful when you need to test async behavior.
When the HTTP source emits r (response), you immediately expect a (action) to appear in the ACTION sink — they happen at the same time. However, when the ACTION source emits a burst of -a-b-c, you don’t expect anything to appear at that moment in the HTTP sink.
This is because searchUsers is meant to debounce the actions it receives. It’ll only send off an HTTP request after 800 milliseconds of inactivity on the ACTION source stream: it’s implementing an autocomplete functionality.
Testing this sort of async behavior is trivial with pure and reactive functions.
Conclusion
In this article we explained the true power of FRP. We introduced Cycle.js and its novel paradigms. The Cycle.js awesome list is an important resource if you want to learn more about this technology.
Using Cycle.js on its own — without React or Redux — requires a bit of a switch in mentality but can be done if you’re willing to abandon some of the technologies and resources in the React/Redux community.
Redux-cycles on the other hand allows you to continue using all of the great React stuff while getting your hands wet with FRP and Cycle.js.
Special thanks to Gosha Arinich and Nick Balestra for maintaining the project along with myself, and to Nick Johnstone for proof reading this article.