
By Ondrej Polesny
REST API services, SQL databases, markdown files, text files, SOAP services… can you think of yet another way to store and exchange data and content? Production websites usually work with several different services and ways to store data, so how can you keep the implementation clean and maintainable?
Every Node.js website, regardless if it is a single page application or a regular site, needs to connect to a third-party service or system. At the very least it needs to get content from markdown files or a headless CMS. But the need for other services quickly surfaces. First, it’s a contact form — you need to store its submissions. Then it’s a full-text search — you need to find a service that enables you to create indexes and search through them. And the list goes on and on depending on the size of your project.
What is the problem with that? Well, nothing at first. When you are motivated to finish a project you create a component for each of these functionalities. Communication is encapsulated within the respective components, and after a few quick tests, you are happy it all works. The customer is happy the project was delivered before the deadline, and as a side effect, you also became an expert on a Content as a Service API, form submission services, and automatic search index rebuilding.
You got the website up and running so quickly that you got promoted! And the knowledge of the project and its details with you.
In a few weeks, your colleagues are asked to do some changes to the project. The customer wants to use a different search provider as the original one is too expensive. The developers are also working on another project that needs a contact form, so they thought about using the same component, but store the submissions in a different service. So they come to you asking about the specifics of your implementation.

When you finally give up searching your memory, they will need to do the same research as you did originally to figure out the implementation. The UI is so tightly coupled with the functionality, that when they want to reuse the components, they will probably end up implementing them again from scratch (and maybe copy-pasting bits and pieces of the old code).
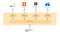
Decoupled infrastructure showing GraphQL communication and specific GraphQL resolvers
The Right Level of Abstraction
So how can we avoid these issues to keep our code maintainable and clean? Take a look at the graphic above where I divided the communication with third-party services and the UI. The specifics of each external service API are implemented in the middleware on the back-end of the website. The components on the front-end all use a single way to fetch and submit data — GraphQL.
GraphQL
So what is GraphQL and why use it to communicate between front-end and back-end? GraphQL is a query language, a protocol, that was founded exactly for this purpose — to decouple the data the website front-end needs from the queries required to fetch them. It is similar to a REST API from a functionality point of view as it enables you to query for data. For more information check out the GraphQL homepage.
The main difference is in the way you ask for the data. Let’s say a new developer on the project is tasked with creating a blog page. The page should display blog posts that are stored within a headless CMS. I am using Kentico Cloud, which is a Content as a Service (CaaS) platform allowing you to store various types of content in clear hierarchical structures and obtain the content via a REST API. Therefore the GET request for data using a REST API could look like this:https://deliver.kenticocloud.com/{projectID}/items?system.type=blog_post
Sample response would be:{
"items":[
{
"system":{
"id":"0282e86e-8c72–47f3–9d3d-2acf93a8986b",
...
"last_modified":"2018–09–18T10:38:19.8406343Z"
},
"elements":{
"title":{
"type":"text",
"name":"Title",
"value":"Hello from new Developer Evangelist"
},
"content":{
...
}
...
}
}
]
}
The response contains data of all blog posts in JSON form. As the page displays only a list of blog posts, a lot of returned data (starting with content field) are redundant as we do not need to display them. To save bandwidth (which you usually pay for), the developer would need to use additional columns filter:https://deliver.kenticocloud.com/{projectID}/items?system.type=blog_post&elements=title,image,teaser
They need to know the specifics of the API and probably have its reference open in another browser window while building the query.
Getting the same data with GraphQL is much easier. Its schema is natively describing what the front-end is capable of rendering. The developer needs to specify what data to fetch in graph notation:query BlogPosts {
getBlogPosts {
elements {
title
image
teaser
}
}
}
(Find more examples of GraphQL queries in this Why GraphQL? article by Shankar Raju.)
Now when you decide to switch the content storage from headless CMS to markdown files or SQL database, the implementation of the blog page will not change. The GraphQL query will still look the same.
How is that possible? Let’s look under the hood for a moment. The separation of the front-end implementation from external services is achieved using the following parts:
GraphQL schema
GraphQL resolvers
Apollo server

GraphQL Schema
GraphQL schema is very much like class diagrams. It specifies the data models, like BlogPost or FormSubmission, and GraphQL queries.

Above you can see an example data models schema of a simple website. Note that there are undefined types like SystemInfo or AssetElement. I omitted them in the graphic as they will be generated later by the headless CMS type generator automatically.

Queries and mutations (calls that may modify and store data) then describe how the data in these models are fetched and manipulated, like getting data for BlogPost or submitting a FormSubmission. It is like a class diagram for the middle data layer of the website.

Resolvers
Resolvers are the actual implementations of the queries defined above, like MySQL resolver, Kentico Cloud resolver, and others. They are assigned to specific queries of the schema and are responsible for processing them. So when a front-end component wants to fetch blog posts using GraphQL query getBlogPosts, the server selects and invokes the registered resolver for that query (Kentico Cloud resolver). The resolver uses REST API of the headless CMS to fetch the content in JSON and provides it as an object array back to the component.

In this simple case, the resolvers are matched to queries and mutations 1:1, but a resolver can be signed up to as many of them as it can handle. The MySQL resolver currently has nothing to do, but later may come handy when the website functionality grows, and we decide to store some sensitive user inputs locally using a database.
Apollo Connects Them All
The last piece of the puzzle is the Apollo server. It’s the glue that connects all these parts. Apollo is a library, a framework, that connects GraphQL schema to a HTTP server in Node.js. I am personally using Express as a HTTP server, but you may also like Connect, Restify or Lambda.
Apollo has two parts — server and client. The server works as a host for the GraphQL schema and handles the GraphQL requests. So whenever the front-end invokes a GraphQL query, Apollo server looks up the right resolver, waits for it to process the data and passes along its response. Apollo server is often used as a simple converter from any service interface to GraphQL when you need to integrate with a system that does not support GraphQL natively.
Apollo client is a module that plugs into the front-end of a website and enables execution of GraphQL queries.
Boilerplate to Speed Things Up
In this article, I explained how to separate concerns, isolate third-party service connectors, and enable rapid development of front-end components using GraphQL without knowing the specifics of all used services.
My next article with live demo dives more into using Apollo with GraphQL schema, shows how to define the schema and implement resolvers. It also presents a boilerplate that has all these tools set up and ready for your development.