
By swyx
Imagine that you work at Magic Money Corp, which runs on just three lines of JavaScript:
let input = { step1: 'collect underpants' }
doStuff(input)
profit(input) // $$$!!!
Now imagine that something's wrong with doStuff and you need to take it down for maintenance. What happens if you temporarily comment out the second line?
Oh no! profit() is erroring all over the place. You've broken your magic money machine!
To solve this, you would now have to read through the entire source code of doStuff to understand what it does and replace critical code for profit to function. Sounds like a lot of work... maybe we should leave it and write a workaround?
When we are afraid of making changes to our code, it starts to ossify and bloat.
Now let's imagine if you had built Magic Money Corp on immutable data structures instead (or used a functional language):
let input = ImmutableMap({ step1: 'collect underpants' })
doStuff(input)
profit(input) // $$$!!!
It looks the same, but now you can remove doStuff, and have no fear of breaking Magic Money Corp.
I've been obsessed with Dan Abramov's concept of Optimizing for Change since he wrote about it two years ago. It clearly articulates a core design principle of React (the rest are here and here). For me, it is one of the 7 lessons that will outlive React that I now try to apply everywhere else.
The main question it doesn't answer, though, is how exactly do you optimize for change?
How to Optimize for Change – TL;DR
- Plan for Common Changes
- Use Simple Values
- Minimize Edit Distance
- Catch Errors Early
Why Optimize for Change
First, an obligatory explanation of this idea:
- Hard-to-delete code drives out easy-to-delete code over time
- Many layers of bandaids over hard-to-delete code cause technical mummification
- Therefore we must try to optimize for change from the earliest design
The inspiration for this idea came from "Easy-to-replace systems tend to get replaced with hard-to-replace systems" (Malte Ubl) and "Write code that is easy to delete, not easy to extend" (tef).
Economics fans will recognize this as an application of Gresham's Law. The idea is the same — a form of anti-entropy where inflexibility increases, instead of disorder.
It's not that we don't know when our systems are hard-to-replace. It is that the most expedient response is usually to slap on a workaround and keep going.
After one too many bandaids, our codebase mummifies. This is the consequence of not allowing room for change in our original designs – a related (but distinct) idea to "technical debt" (which has its own problems).
The reason we must allow for changes is that requirements volatility is a core problem of software engineering.
We devs often fantasize that our lives would be a lot easier if product specs were, well, fully specified upfront. But that's the spherical frictionless cow of programming.
In reality, the only constant is change. We should carefully design our abstractions and APIs acknowledging this fact.
How to Plan for Common Changes
Once you're bought in to the need to optimize for change, it is easy to go overboard and be overcome by analysis paralysis. How do you design for anything when EVERYTHING could change?!
You could overdo it by, for example, putting abstract facades on every interface or making every function asynchronous. It’s clear that doubling the size of your codebase in exchange for no difference in feature set is not desirable either.
A reasonable way to draw the line is to design for small, common tweaks, and not worry about big, infrequent migrations. Hillel Wayne calls these requirement perturbations — small, typical feature requests should not throw your whole design out of whack.
For the probabilistically inclined, the best we can do is make sure our design adapts well to 1-3 "standard deviation" changes. Bigger changes than that are rare (by definition), and justify a more invasive rewrite when they happen.
This way, we also avoid optimizing for change that may never come, which can be a significant source of software bloat and complexity.
Common changes can be accumulated with experience - the humorous example of this is Zawinski's Law, but there are many far less extreme changes that are entirely routine and can be anticipated, whether by Preemptive Pluralization or Business Strategy.
Use Simple Values
Once we have constrained the scope of our ambitions, I like to dive straight into thinking about API design. The end goal is clear. In order to make code easy to change:
- it has to first be easy to delete
- which then makes it easier to cut and paste
- which makes it easier to create and break apart abstractions
- and so on, until you cover all routine maintenance tasks, including logging, debugging, testing, and performance optimization.
Rich Hickey is well known for preaching the Value of Values and Simplicity. It is worth deeply understanding the implications of this approach for API design.
Where you might pass class instances or objects with dynamic references, you could instead pass simple, immutable values. This eliminates a whole class of potential bugs (and unlocks logging, serialization, and other goodies).
 the key slide for Simple vs Complex from "Simple Made Easy"
the key slide for Simple vs Complex from "Simple Made Easy"
Out of these requirements for simple uncomplected values, you can derive from first principles a surprising number of "best" practices — immutable programming, constraining state with a functional core, imperative shell, parse don't validate, and managing function color.
The pursuit of simplicity isn't a cost-free proposition, but a variety of techniques from structural sharing to static analysis can help.
Instead of memorizing a table of good/bad examples, the better approach is to understand that these are all instances of the same general rule: Complexity arises from coupling.
Minimize Edit Distance
I mentally picture the braids from Simple Made Easy now, whenever I think about complexity.

When you have multiple strings next to each other, you can braid them and knot them up. This is complexity — complexity is difficult to unwind. It is only when you have just one string that it becomes impossible to braid.
More to the point, we should try to reduce our reliance on order as much as possible:
- Execution order — If I delete something on line 2, how easily can the developer tell if something in line 3 will blow up? How many changes do I need to make to fix it?
- Resolution order — If concurrent processes resolve out of order, how easily can I correct for or guarantee against race conditions?
- Filesystem order — If I move some code from one place to another, how many other files need to be edited to reflect this?
- Argument order — If I swap the position of some arguments, whether in a function call or a class constructor or a YAML config file, does the program implode?
- this is an ad hoc list; there are probably some big ones I'm missing here, please let me know.
You can even quantify this complexity with the notion of "edit distance":
- If I use multi-arity functions, then I cannot easily add or remove or rearrange parameters without then updating all the callsites, or adding default params I don't actually want. Single arity functions/languages with named params require only essential updates and no more. (This isn't without tradeoffs of course — more discussion here.)
- Turning a stateless component stateful with React (pre-Hooks) used to require edits/additions of 7 lines of code. With React Hooks, it just takes 1.
- Asynchrony and Data Dependency tend to propagate in a codebase. If one requirement changed and something at the bottom needed to be async (for example it needs one data fetch), I used to have to switch between at least 3 files and folders, and add reducers and actions and selectors with Redux to coordinate this. Better to decomplect parent-child relationships — a design goal prominent in React Suspense, Relay Compiler and GraphQL's dataloader.
You could even imagine a complexity measure similar to the CSS specificity formula – a complexity of C(1,0,0,0) would be harder to change than C(0,2,3,4). So optimizing for change would mean reducing the "edit distance" complexity profile of common operations.
I haven't exactly worked out what the formula is yet, but we can feel it when a codebase is hard to change. Development progresses slower as a result.
But that's just the visible effect — because it isn't fun to experiment in the codebase, novel ideas are never found. The invisible cost of missed innovation is directly related to how easy it is to try stuff out or change your mind.
To make code easy to change, make it impossible to "braid" your code.
Catch Errors Early
As much as we can try to contain the accidental complexity of our code by API design and code style, we can never completely eliminate it except for the most trivial programs.
For the remaining essential complexity, we have to keep our feedback loops as short as possible.
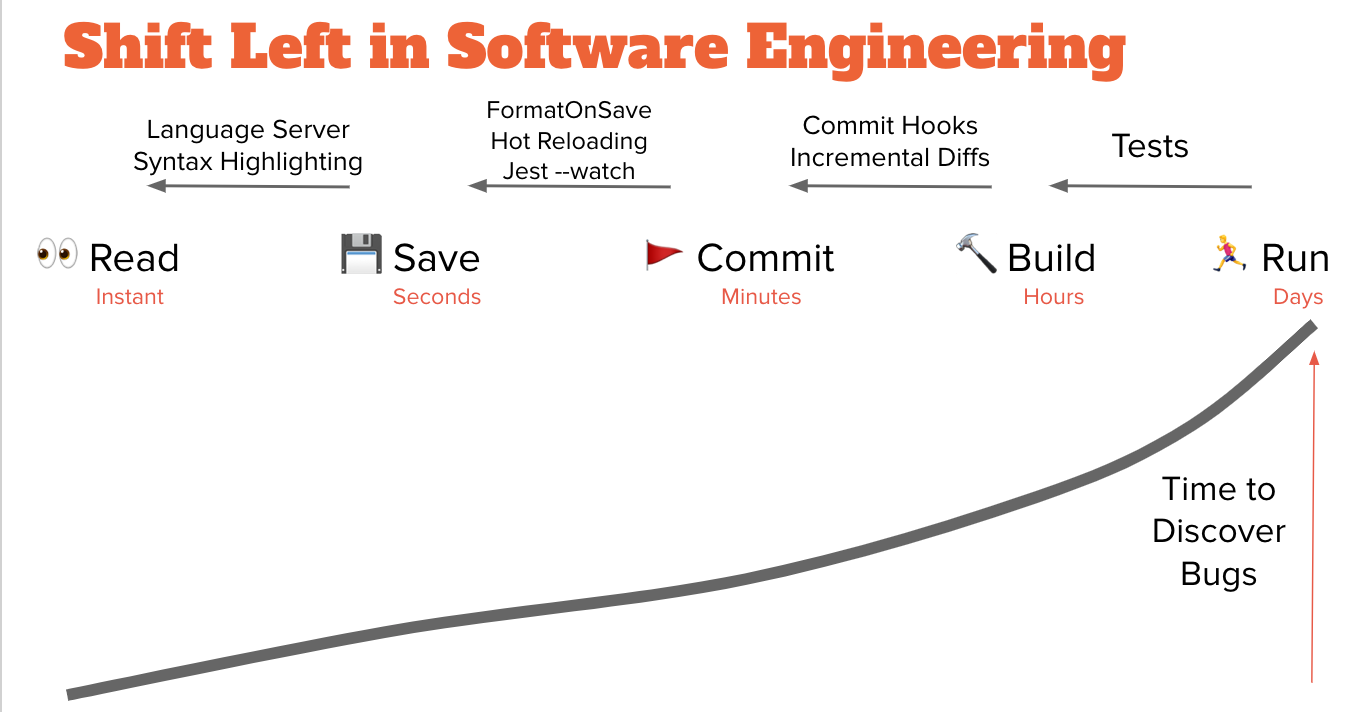
IBM coined the term "Shift Left" after finding that the earlier you catch errors, the cheaper they are to fix.
If you arrange the software development lifecycle from left (design) to right (production), the idea is that if you shift your errors "left" then you'd save actual money by catching errors earlier.
(For more on this, see my discussion and sources in Language Servers are the New Frameworks).
In concrete terms this might translate to:
- unit tests that pinpoint what broke in your code when you refactor
- types that codify the contracts between data and functions
- continuous deploys that take less than 15 minutes (you probably have easy wins to make in frontend or backend)
- local development servers that emulate your cloud environment
- "live" values either provided by language servers or editor plugins or replay recording
The causality may be bidirectional. If you make it easier to change things, you will be able to make changes more frequently.
But it could work the other way too — because you expect to make frequent changes, you are more incentivized to make things easy to change.
An extreme example of this involves not just code, but community. The longer a library (or language) stays on version 1, the harder it is to switch to version 2. Whereas ecosystems that regularly publish breaking versions (in exchange for clear improvements) seem to avoid stasis by sheer exposure.
A caution against too much change
Any good idea turns bad when taken to the extreme. If you change things too much you might be favoring velocity over stability — and stability is very much a feature that your users and code consumers rely on.
Hyrum's law guarantees that with sufficient users and time, even your bugs will be relied on, and people will get upset if you fix them.
That said, overall, I find Optimizing for Change a net win in my programming, product, and system design decisions and am happy that I've boiled it down to four principles:
- Plan for Common Changes
- Use Simple Values
- Minimize Edit Distance, and
- Catch Errors Early.
Thanks for reading!