

Technology, like human lives, evolves, and with this evolution comes the use of better solutions to existing problems. You might wonder: does this complicate systems or make them more efficient?
In this article, we will discuss some measures you can take to make systems much more efficient and reliable.
What is a Distributed System?
In a very simple way, a distributed system is a group or collection of independent computer nodes connected via a central unit which share and utilise computational resources.
Think of this as a network of systems which can interact and share tasks which they can process collectively as a single unit. Therefore distributed workloads refer to the processes or tasks that run in these systems.
Now, for these systems to interact efficiently, you can make use of some protocols or designs. One of them is a queue, which you'll learn about in the next section.
What is a Queue?
A queue is a data structure which models the First-In-first-Out Principle (FIFO).
To understand this, picture a checkout station in a supermarket. The first person to join the line will be the first to be attended to. Then subsequently, the next person is attended to. This is pretty much how queues works, but now as a data structure what is being processed can be different events or messages which we will identify as workloads.
Typically in a queue system, you have the producer and the consumer. The producer is the service that sends an event or in this context, a workload into the queue. And the consumer is the service that listens and processes it.
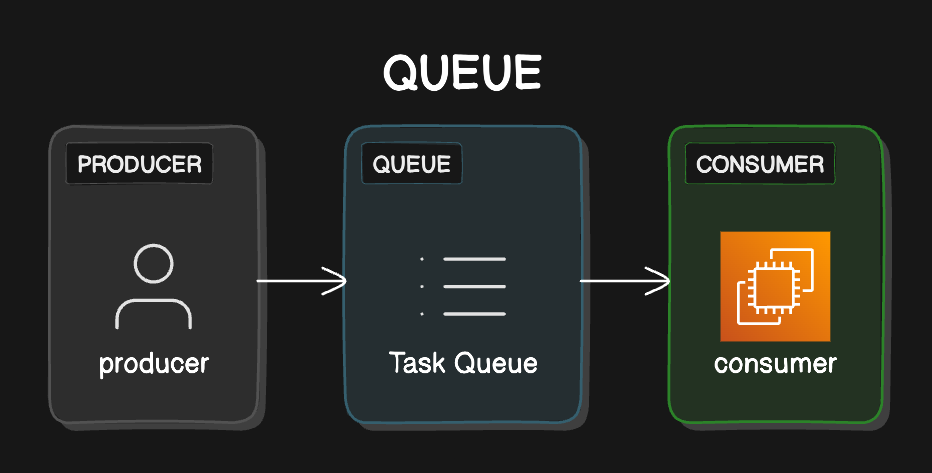 Streamlining Workflows: Producers Feed the Queue, Consumers Process the Flow.
Streamlining Workflows: Producers Feed the Queue, Consumers Process the Flow.
With the very nature of these systems, running queues across this network can be demanding and sometimes you resort to some challenges which will be discussed briefly.
Challenges of Long-Running Queues in a Distributed System.
The goal of a task queue is primarily to handle asynchronous or long-running tasks efficiently.
However, within the distributed system context, running workloads across a network can sometimes prove to be challenging as they become overwhelming for these queues. This can leads to problems such as the following:
- Increase In Network Latency: Distributed systems primarily rely on communications across networks to efficiently coordinate workloads across the different computer nodes. Delayed or long-running tasks can lead to unpredictable response time(latency).
- Difficulty in tracking and monitoring: It can get very complex very quickly to track down each workload especially now that they are shared across different running systems in the network. In order to efficiently manage these you will have to make use of specialised tools such as the ELK Stack.
- Distributed Coordination: Ensuring that workloads being passed to different queues across the network are executed correctly and in the order they ought to is a challenge. Lack of this coordination further leads to data inconsistency.
- Fault Tolerance and Resilience: Processes running in a distributed system will surely contend with breakpoints and node failures. Having workloads in long-running queues can increase these failure points, which can lead to an increase in queue backlogs, data loss or inconsistency.
The question is how best can you combat these issues, or what measures should you take to reduce the possibility of system failures or data inconsistency. An approach to solving this is by making use of partitioned task queues.
What does it mean to partition a Queue?
Partitioning can be defined as breaking down a component into smaller subsections. Using this, you can derive a definition for queue partition as breaking a queue system into smaller, more manageable bits to offload workloads in a faster and more efficient manner.
Picture a centralised queue with various workloads coming with different task types or even priorities.
When traffic or workloads are at a very high rate, this queue will eventually become overwhelmed and keep compiling backlogs.
In order to lift the burden you can divide the queue into various bits to handle different task types. For example, you can have a queue to handle priority tasks or even to process different event types, like notifications.
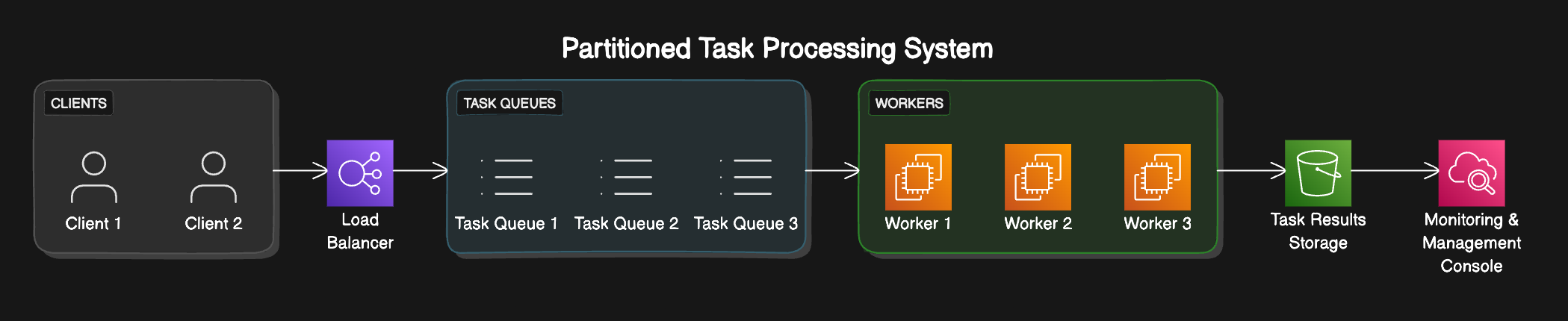 Partitioned Queues in Distributed Systems: Optimizing Workload Management Across Nodes.
Partitioned Queues in Distributed Systems: Optimizing Workload Management Across Nodes.
Primarily the goal of partitioning a queue is to improve system performance and reduce downtimes or data inconsistency. In order to do this, you have to look at different strategies of how to partition queues in other to know the one that is best suitable for your system.
Effective Task Queue Partitioning Strategies
There are various ways in which you can break a queue into subsections, but for you to be able to do that efficiently, you can employ some tested strategies such as Range-based Partitioning, Hash-based partitioning, and so on.
Hash-based partitioning
This form of partitioning allows for the selection of a queue using an assigned hash value.
First off, a parameter in the workload is used to get a hash value. Then, you take the modulo of that value with the number of partitions (queues), which results in a partition index. This index is then used to determine the queue to which the task will be assigned.
const numPartitions = 4;
const queues = Array.from({ length: numPartitions }, (_, i) => ({
name: `Queue ${i + 1}`,
partitionIndex: i + 1,
}));
function getPartitionIndex(hash) {
const partitionIndex = hash % numPartitions;
return partitionIndex + 1;
}
function hashCode(str) {
let hash = 0;
for (let i = 0; i < str.length; i++) {
const char = str.charCodeAt(i);
hash = ((hash << 5) - hash) + char;
}
return Math.abs(hash);
}
const tasks = [
{ id: 1, value: "Emails Task" },
{ id: 2, value: "Transactions Tasks"},
{ id: 3, value: "Orders Tasks" },
{ id: 4, value: "Update Tasks" },
];
tasks.forEach(task => {
const hash = hashCode(task.value);
const partitionIndex = getPartitionIndex(hash);
const assignedQueue = queues.find(queue => queue.partitionIndex === partitionIndex);
console.log(`Task with ID: ${task.id} (content: ${task.value}) assigned to ${assignedQueue ? assignedQueue.name : "no queue"}`);
});
The above example involves hashing a particular value or field in the workload or event that is to be assigned. In this case, the content field was hashed, and its hash value was then used to determine which queue the workload will be assigned to. This hash value might appear random but in truth it is constant, meaning the same input will always produce the same hash value.
Task with ID: 1 (content: Emails Task) assigned to Queue 3
Task with ID: 2 (content: Transactions Tasks) assigned to Queue 4
Task with ID: 3 (content: Orders Tasks) assigned to Queue 4
Task with ID: 4 (content: Update Tasks) assigned to Queue 2
Seeing the output, if you were to change the content of one of these tasks, you will see that they will get another hash value and might be assigned to a different queue.
In a real-life scenario, if you want the workloads to be distributed amongst different queues, you should ensure the hash value is something unique among tasks, like its Identifier. You can make use of an UUID.
Range-based Partitioning
This strategy allows you to spread tasks or workloads coming from a centralised workload into subsections based on a range of task IDs. For example, queue A might only allow a task ID that falls within the range of 1 - 50, while queue B handles the task with an ID ranging from 51- 100.
This strategy ensures that tasks are distributed across each partition in order to efficiently utilise the resources available and ensure workloads are distributed.
Take a look at this code example below that shows how tasks are assigned to a partition based on the range their IDs fall in:
const { v4: uuidv4 } = require("uuid");
const numPartitions = 4;
const partitionRanges = Array.from({ length: numPartitions }, (_, i) => ({
start: i * 250,
end: (i + 1) * 250,
}));
const queues = Array.from({ length: numPartitions }, (_, i) => ({
name: `Queue ${i + 1}`,
partitionIndex: i + 1,
}));
function getPartitionIndex(hash) {
return Math.floor(hash / 250) + 1;
}
const hashCode = (str) => {
let hash = 0;
for (let i = 0; i < str.length; i++) {
const char = str.charCodeAt(i);
hash = (hash << 5) - hash + char;
}
return Math.abs(hash) % 1000;
};
const tasks = Array.from({ length: 4 }, () => ({ id: uuidv4() }));
tasks.forEach((task) => {
const hash = Math.abs(hashCode(task.id));
const partitionIndex = getPartitionIndex(hash);
const assignedQueue = queues.find(
(queue) => queue.partitionIndex === partitionIndex,
);
console.log(
`Task with ID: ${task.id} assigned to ${assignedQueue ? assignedQueue.name : "no queue"}`,
);
});
In this code example, the taskId is a UUID. To match them to a partitioned queue range (each queue has a range of 250), you first hash-code it and then convert it to an absolute value.
Next, you call the PartitionIndex() function with this hash value.
From there, It finds the partitioned queue that the taskId fits within the range.
This is an example output below:
Task with ID: 493fbf04-2f4f-43c0-9486-f5c99313d4e6 assigned to Queue 2
Task with ID: 9bad272f-3369-408e-bb37-5ef00c68b0b6 assigned to Queue 3
Task with ID: e0ec2d06-d66b-4e0e-8e85-04e4755a42be assigned to Queue 1
Task with ID: 960f415b-2e64-4169-b4ee-59b11c33b451 assigned to Queue 4
Round-Robin Partitioning
For this partitioning strategy, tasks are assigned to queues in a cyclic pattern. This means that if a task gets assigned to queue 1, the next task will get assigned to queue 2, until all the queues get assigned a task before starting from queue 1 again, therefore making it to be distributed evenly amongst the queues.
const numPartitions = 4;
let currentPartition = 0;
function getRoundRobinPartitionIndex() {
const partitionIndex = (currentPartition % numPartitions) + 1;
currentPartition++;
return partitionIndex;
}
const tasks = [1, 2, 3, 4, 5];
tasks.forEach(task => {
const partitionIndex = getRoundRobinPartitionIndex();
console.log(`Task with ID: ${task} assigned to Queue ${partitionIndex}`);
});
For this example, a function getRoundRobinPartitionIndex() was defined and it determines the next queue index using a round-robin strategy.
It first calculates the queue index by taking the modular value of currentPartition and numPartitions. It adds 1 to it to ensure the initial index starts from 1, then increments the currentPartition to make sure the next queue to be assigned is greater than the previous. If the modular value is 0, it returns to the queue with index of 1.
Task with ID: 1 assigned to Queue 1
Task with ID: 2 assigned to Queue 2
Task with ID: 3 assigned to Queue 3
Task with ID: 4 assigned to Queue 4
Task with ID: 5 assigned to Queue 1
As you can see, the output above shows that the tasks were distributed to each of the queues and then started from the first queue again.
Dynamic Partitioning
This type of partitioning strategy involves assigning tasks to queues based on changing workloads or system conditions.
For instance, a system has 3 queues actively working and 1 that is free. It checks for the one with the least tasks assigned to it and then assigns a new task to it. By doing this, it ensures that the queues are not overwhelmed and that system resources are efficiently utilised.
const { v4: uuidv4 } = require('uuid');
let numPartitions = 4;
let queues = Array.from({ length: numPartitions }, (_, i) => ({
name: `Queue ${i + 1}`,
tasks: [],
}));
function dynamicPartitioning(task) {
let minLoadQueue = queues[0];
for (let queue of queues) {
if (queue.tasks.length < minLoadQueue.tasks.length) {
minLoadQueue = queue;
}
}
minLoadQueue.tasks.push(task);
console.log(`Task with ID: ${task.id} assigned to ${minLoadQueue.name}`);
}
const tasks = Array.from({ length: 5 }, () => ({ id: uuidv4(), value: `Task content` }));
tasks.forEach(task => {
dynamicPartitioning(task);
});
function addPartition() {
numPartitions++;
queues.push({ name: `Queue ${numPartitions}`, tasks: [] });
console.log(`Added new partition: Queue ${numPartitions}`);
}
setTimeout(() => {
addPartition();
// Assign new tasks to demonstrate dynamic partitioning with the new queue
const newTasks = Array.from({ length: 5 }, () => ({ id: uuidv4(), value: `New task content` }));
newTasks.forEach(task => {
dynamicPartitioning(task);
});
}, 5000);
In this code above, it starts by creating three queues and dynamically assign tasks to the least loaded queue.
After a simulated put-off, a new queue is brought to deal with the elevated workload and new obligations are distributed among all available queues.
This technique ensures that the burden is balanced throughout all queues, and the queue is overloaded, making the machine more efficient and responsive to adjustments in workload.
Task with ID: 396d4fde-830b-4443-b59b-c089f3a1db49 assigned to Queue 1
Task with ID: aa85af19-e46a-4b13-9a9c-2eb3ec535af0 assigned to Queue 2
Task with ID: f93d4cbb-0cad-4b71-a424-4c27a77ed38a assigned to Queue 3
Task with ID: c7e0cc7e-f055-4a38-9869-466406a33ca8 assigned to Queue 4
Task with ID: b49fe153-73e8-45d1-85b3-a5873f836dc9 assigned to Queue 1
Added new partition: Queue 5
Task with ID: a8a5f78e-da7e-4c65-9d74-8cef57f271f3 assigned to Queue 5
Task with ID: 00ce47b0-6098-49d6-ad06-820733ffe16e assigned to Queue 2
Task with ID: 7b1a5dcf-c42c-46dc-8e29-bae1cc5408c1 assigned to Queue 3
Task with ID: 3e31ad34-1a19-4d3c-a8f3-08f765a45f13 assigned to Queue 4
Task with ID: 73d55243-27da-44a4-9192-532a20889373 assigned to Queue 5
There are other strategies, like content-based partitioning, random-based partitioning, or even a user-defined custom type.
All these strategies are good but can still have some issues if not properly managed.
For instance, if you are using the range-based partition strategy and you select an identifier which falls within the set range of a queue, that queue partition will eventually get overwhelmed. It is left up to you to figure out the one that is best for your system requirements.
Conclusion
Processing workloads in distributed systems can be kind of complex and inefficient if not managed properly.
Partitioning queues across the system and having the workloads be distributed to them based on a strategy is one way to improve your system performance.
In this article, some challenges with long running queues were pointed out, and some strategies to relieve them were given. I have been researching distributed systems in run-time environments and databases and this was one of my findings.
I hope you enjoyed reading this because I enjoyed writing this. You can follow me on Twitter(X).