By Flavio H. Freitas
Choosing a good title for an article is an important step in the writing process. The more interesting the title seems, the higher the chance a reader will interact with the whole thing. Furthermore, showing the user content they prefer (to interact with) increases the user’s satisfaction.
This is how my final project from the Machine Learning Engineer Nanodegree specialization started. I just finished it, and I feel so proud and happy ? that I wanted to share with you some insights I’ve had about the whole flow. Also, I promised Quincy Larson this article when I finished the project.
If you want to see the final technical document click here. If you want the implementation of the code, check it out here or fork my project on GitHub. If you just want an overview using layperson’s terms, this is the right place — continue reading this article.
 FreeCodeCamp Medium post on Twitter
FreeCodeCamp Medium post on Twitter
Some of the most used platforms to spread ideas nowadays are Twitter and Medium (you are here!). On Twitter, articles are normally posted including external URLs and the title, where users can access the article and demonstrate their satisfaction with a like or a retweet of the original post.
Medium shows the full text with tags (to classify the article) and claps (similar to Twitter’s likes) to show how much the users appreciate the content. A correlation between these two platforms can bring us valuable information.
The project
The problem that I defined was a classification task using supervised learning: Predict the number of likes and retweets an article receives based on the title.
Correlating the number of likes and retweets from Twitter with a Medium article is an attempt to isolate the effect of the number of reached readers and the number of Medium claps. Because the more the article is shared on different platforms, the more readers it will reach and the more Medium claps it will (likely) receive.
Using only the Twitter statistic, we’d expect that the articles reached initially almost the same number of readers (those readers being the followers of the freeCodeCamp account on Twitter). Their performance and interactions, therefore, would be limited to the characteristics of the tweet — for example, the title of the article. And that is exactly what we want to measure.
I chose the freeCodeCamp account for this project because the idea was to limit the scope of the subject of the articles and better predict the response on a specific field. The same title can perform well in one category (e.g. Technology), but not necessarily in a different one (e.g. Culinary). Also, this account posts the title of the original article and the URL on Medium as the tweet content.
How does the data look?
The first step of this project was to get the information from Twitter and Medium and then correlate it. The dataset can be found here and it has 711 data points. This is how the dataset looks like:
Analyzing and learning with the data
After analyzing the dataset and plotting some graphics, I found interesting information about it. For these analyses, the outliers were removed, and I just considered the 25% top performers for each feature (retweet, like, and clap).
So let’s take a look at what the numbers say for freeCodeCamp articles written on Medium and shared on Twitter.
What is a good title length?
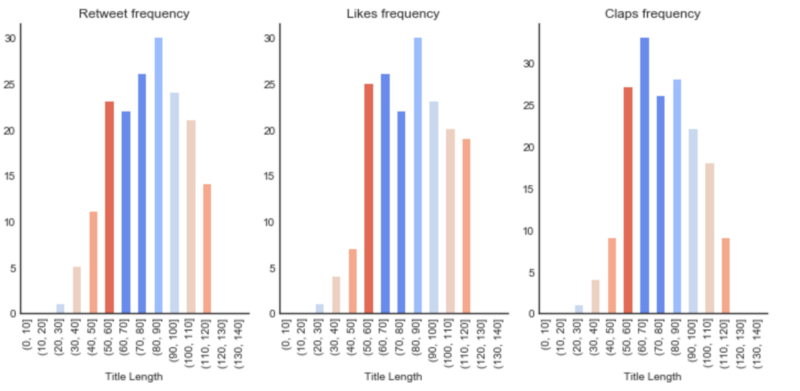 Title length performance
Title length performance
Writing titles that have a length greater than 50 and less than 110 characters helps to increase the chances of a successful article.
What is a good number of words in the title?
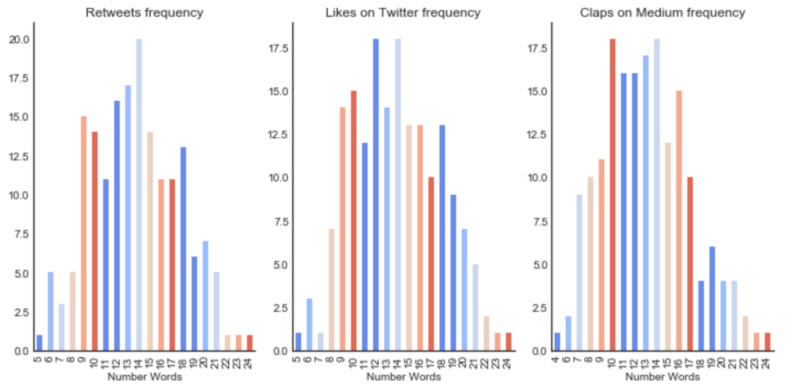 Number of words performance
Number of words performance
The most effective number of words in the title is 9 to 17. To optimize the number of retweets and likes, try something from 9 to 18 words, and for claps from 7 to 17.
Which are the best categories to tag?
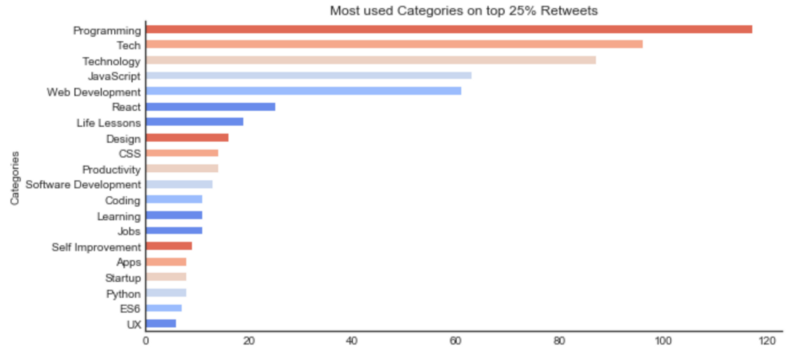
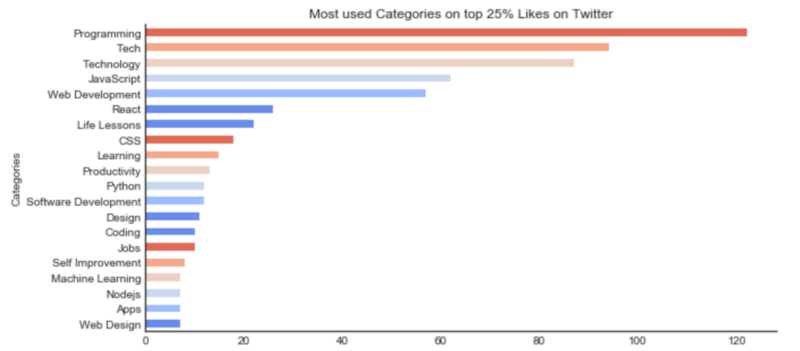
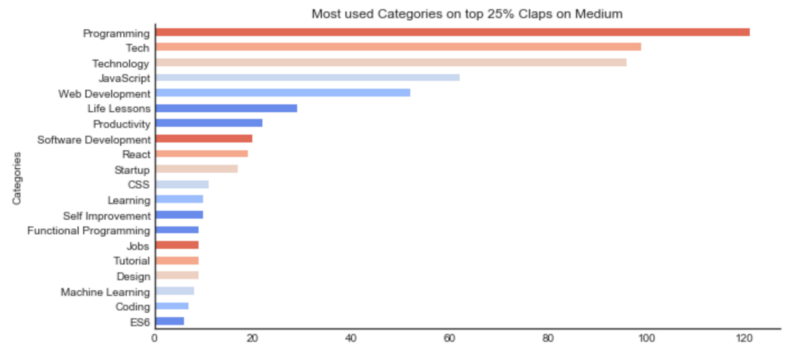
Programming, Tech, Technology, JavaScript and Web Development are categories you should consider when tagging your next article. They appear for all the three features as a good indicator.
Which are the best words to use?
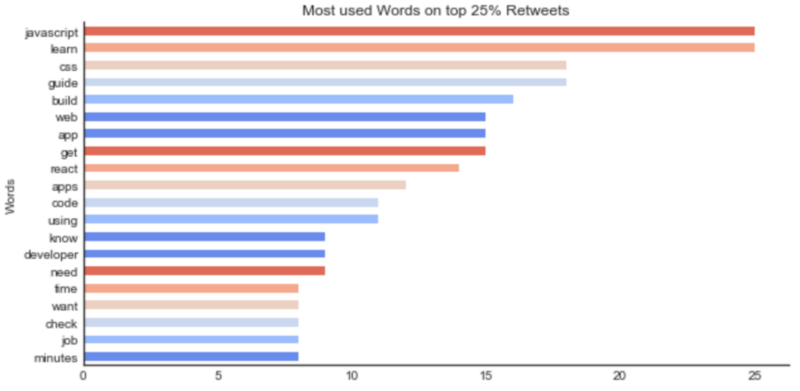
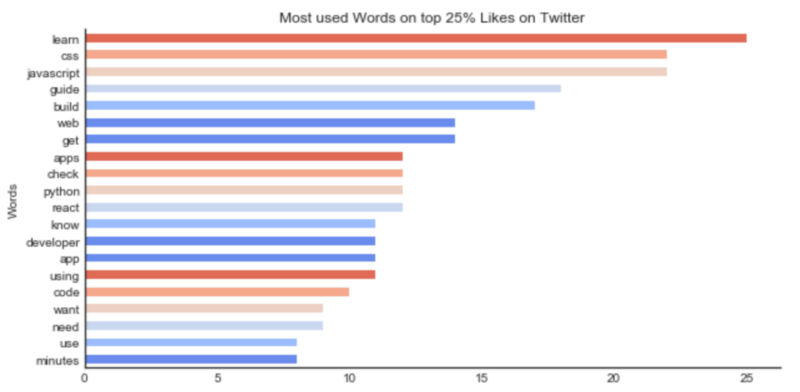
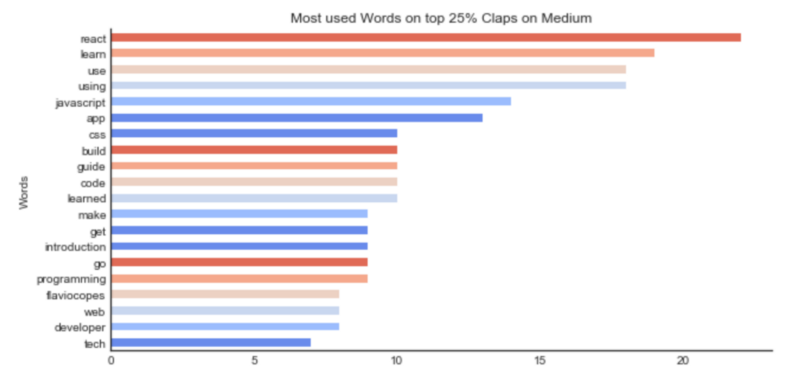
In this lexical analysis, you’ll notice that some words get much more attention on the freeCodeCamp community than others. If the intention is to make the articles reach further in numbers, talking about JavaScript, React or CSS will increase how much it’s appreciated. Using the words “learn” or “guide” to describe will also make the probability higher.
Using Machine Learning
OK! After taking a look at the data and extracting some information from it, the goal was to create a Machine Learning model that makes predictions of the number of retweets, likes, and claps based on the title of the article.
Predicting the number of retweets, likes, and claps of an article can be treated as a classification problem, and that is a common task of machine learning (ML). But for this, we need to use the output as discrete values (a range of numbers). The input will be the title of the articles with each word as a token (t1, t2, t3, … tn), the title length, and the number of words in the title.
The ranges for our features are:
- Retweets: 0–10, 10–30, 30+
- Likes: 0–25, 25–60, 60+
- Claps: 0–50, 50–400, 400+
And finally, after preprocessing our dataset and evaluating some models (everything fully described here), we reached the conclusion that the MultinomialNB model performed better for retweets reaching an accuracy of 60.6%. Logistic regression reached 55.3% for likes and 49% for claps.
As an experiment for this article, I ran the prediction of the title of this article and the model predicted that:
It will have 10–30 retweets and 25–60 favorites on Twitter and 400+ claps on Medium.
How is this prediction? ?
Follow me if you want to read more of my articles ? And if you enjoyed this article, be sure to like it give me a lot of claps — it means the world to the writer.
Flávio H. de Freitas is an Entrepreneur, Engineer, Tech lover, Dreamer and Traveler. Has worked as CTO in Brazil, Silicon Valley and Europe.