

Hey everyone! Today, you're going to learn about deploying a Postgres container in Azure Kubernetes Service (AKS) and connecting it to a Node.js application.
In this fast-paced development landscape, deploying via containers, particularly with Kubernetes, is becoming increasingly popular. Some companies perform numerous deployments daily, so it's crucial for you to learn these technologies.
Kubernetes is a popular choice to deploy containerized applications like web servers, databases, and APIs. You can set up Kubernetes either locally or in the cloud. In this tutorial, we'll explore setting up Kubernetes on a cloud platform, specifically Azure.
I'll walk you through the process of setting up Kubernetes using Azure Kubernetes Service (AKS). You'll configure your YAML file using StatefulSet, Persistent Volume, and Services to deploy a PostgreSQL database on Azure Kubernetes. Then, you'll obtain the PostgreSQL database credentials running inside the AKS and use them to establish a connection with a Node.js application.
We'll cover key concepts such as deployment, stateful sets, persistent volumes, and services, preparing you to deploy a Postgres container effectively on AKS. I'll also help you connect your Node.js Express app to the Postgres container within the AKS cluster.
So find a comfortable seat and get ready, as we're about to dive in.
Prerequisites
Before you begin, it's important to understand some basic concepts in Kubernetes like pods, deployments, services, and nodes.
If you're new to this, I recommend checking out the Stashchuk freeCodeCamp video for a beginner-friendly tutorial.
You'll also need an active Azure account and subscription to follow along.
Table of Contents
Challenges We're Trying to Solve
– Deployments
– StatefulSets
– Persistent VolumesAzure Kubernetes Service (AKS)
– Sign in to Your Azure Portal
– Create a Resource
– Create a new container
– Create a new Azure Kubernetes Service(AKS)
– Create a new resource group
– Give your Kubernetes cluster a name
– Navigate to the node pool page
– Enable container logs and set up alerts
– Advanced Section
– TagsConnect to Your AKS Cluster
– Download Azure CLI and kubectl
– Verify if Azure CLI is installed
– Verify if kubectl is installed
– Login to Azure account
– Configure kubectlHow to Create Resources with YAML
– Clone the Repository
– Open the Repository
– Install DependenciesYAML Configuration
– StorageClass
– PersistentVolumeClaim
– ConfigMap
– StatefulSet
– ServiceHow to Deploy YAML Resource to Azure
– Deploy the YAML resourceNode.js Application
– Configure Nodejs
– Run Nodejs Application
– Test the Application
– Open Postman
– Confirm the Data
– Delete Pod
– Data Persistence
Challenges We're Trying to Solve
Firstly, what is Kubernetes? Well, it's like a manager for your software containers. It helps you run and manage lots of containers like web servers, databases, microservices, and APIs which are like little packages holding your applications.
Kubernetes takes care of things like starting, stopping, and scaling these containers, so your apps run smoothly even when there is more load on your application. It's popular because it makes running software in the cloud easier and more reliable.
Now, let's talk about how to tackle some challenges you might face with a real-world application running Postgres in a Kubernetes production cluster.
Imagine that the infrastructure hosting your Postgres crashes, causing you to lose all the services and data stored in the database. Or, picture a scenario where the Postgres database becomes corrupted, leading to data loss.
In both cases, you need a way to back up your application so you can restore it to a working state if disaster strikes.
So, how do you capture a comprehensive application backup that includes all the necessary data? This backup should allow you to restore the entire application, including the database, if you lose your cluster or encounter data loss.
In Kubernetes, think of a Pod as the tiniest unit that you can deploy. It's like a small box that holds one thing, like a web server or a database. So, if your Pod isn't running, your web server or database isn't either.
This means that if the cluster where your Pod runs gets destroyed, all the data in the Pod disappears too. All the nodes (virtual machines that run your application over the network) will also be wiped out.
How can you make a pod stay on one specific node where the data is and never move? And how can you make sure that each pod can be found separately when you're using a load balancer?
One solution is to consider how you deploy your application on Kubernetes. Typically, you create a deployment and expose it using a service, specifying the service type as either Cluster type, NodePort, or LoadBalancer.
But not all applications are the same when it comes to state. Some applications, known as stateless applications, don't rely on storing data locally, so losing their state isn't a big issue.
But for applications like databases or caches, maintaining state is crucial because they rely on storage. In Kubernetes, deploying stateful applications like databases using just deployment isn't ideal. You need a solution that ensures your application's data is safely stored and can be recovered in case of failure.
Deployments
You might be wondering why we can't just use a Kubernetes deployment to deploy Postgres in the Kubernetes cluster? Well, the thing is, many people aren't aware of the difference between a deployment and a stateful set.
Let's imagine you have a pod running in your cluster that you created using a deployment. Then you scaled up to two pods, so you now have Pod A and Pod B.
The problem arises because, by default, pods created as part of the same deployment share the same persistent volume (PV) across the cluster. So, when you scaled up, both instances of Postgres would write to the same storage, which could lead to data corruption.
Another issue arises from a networking perspective. Pods A and B don't have a dependable way to communicate with each other over the network. By default, Kubernetes pods don't have their own DNS names. Instead, you rely on services to expose ports to other applications in the cluster.
If you take a closer look at pod names, you'll notice that pods are assigned a random hash at the end of their names. Because of this, pods lack a consistent network identity. Every time a pod is destroyed and recreated, it receives a new randomized name. This inconsistency isn't ideal for reliable networking.
Postgres isn't naturally made for Kubernetes, and Kubernetes can be tough when handling stateful tasks. To set up a Postgres instance, you've got to know the right Kubernetes setup. You can't just throw it in a pod, because if the pod goes down, so does your data. But, for a quick integration, a pod could work fine.
Deployments aren't ideal either, since you don't want your pod randomly placed on a node. But for testing, deployments are handy if you just need a Postgres instance to run temporarily.
What you really want is a pod that sticks to a particular node where your data resides, and stays put. Plus, you also want your pod to be individually addressable. for this we need what we called a statefulSet.
StatefulSets
When you update your deployment to become a StatefulSet, Kubernetes introduces some improvements for deploying stateful workloads. One major change is how it handles scaling.
If you specify that you want three replicas of your StatefulSet, Kubernetes won't create all three pods at once. Instead, it creates them one by one. Each pod gets its own unique DNS name, starting with the pod's name followed by an ordinal number starting from zero. So, when you scale up, the ordinal number increases for each new pod.
Here's the cool part: if a pod like Pod-0 is destroyed and needs to be remade, it will return with the same name. This means each pod has a specific address, even if it's replaced.
And here's another cool feature: each pod in a StatefulSet gets its own persistent volume (PV). This lets you keep the same storage even if you scale up or down. This brings us to another concept called persistent volumes.
Persistent Volumes
Let's forget about pods, deployment, and containers for a moment. What exactly is "state"? In simple terms, state is the data that your applications need to work properly.
Now, when we talk about processes, there are two types: stateless and stateful. Stateless processes don't rely on any data to work. They just do their thing without needing any specific information. On the other hand, stateful processes need data or state to function properly.
Now, where do you store this state? There are two main places: memory and disk. Memory allows for quick access to data, which is great for applications like Redis, MongoDB, Postgres, or MySQL. They store their state on memory for quick access. But for persistent, they store it on disk on the file system (for more permanent storage).
Why the file system? Because it's the only way to keep the state persistent even when the system reboots. So, when a process dies and gets recreated, it can read its state from the file system.
I like breaking things down because I used to teach tech stuff. Now, let's get into setting up Kubernetes in Azure.
Azure Kubernetes Service (AKS)
In this section, I'll guide you through setting up a Kubernetes cluster on Azure.
Step 1: Sign in to your Azure portal
To begin, you will have to sign into your Azure portal. Once logged in, you should see a dashboard similar to this:
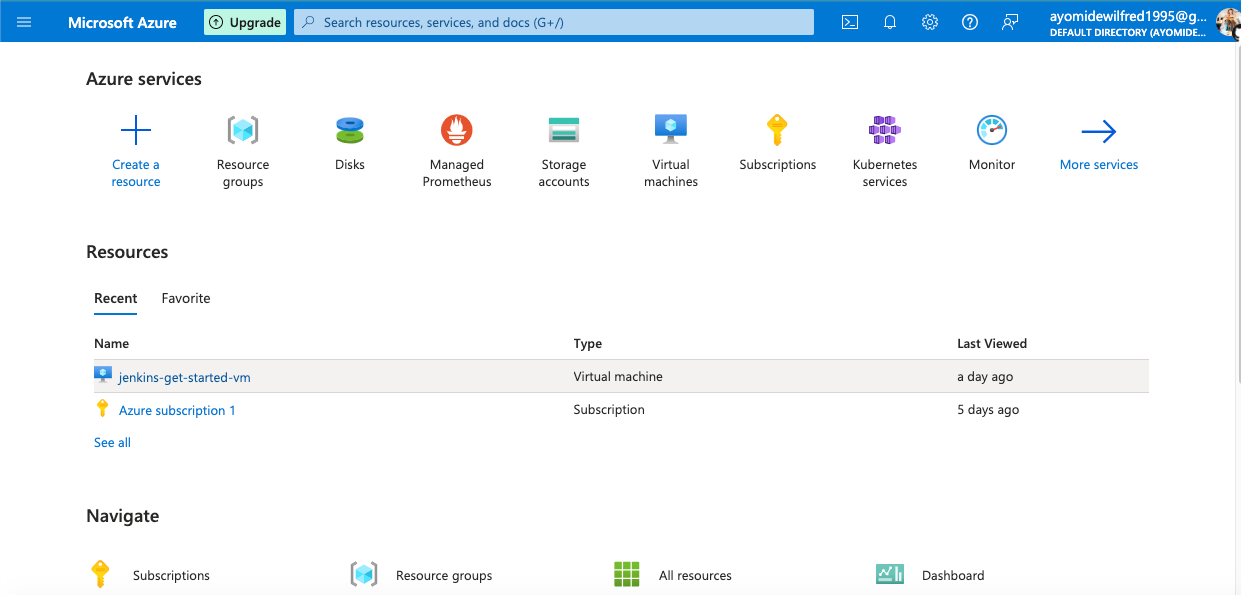
Azure portal homepage
Step 2: Create a resource
Click on "create a resource" to create a resource.
Resources are the various services, components, and assets that you can create and manage within the Azure cloud platform. These resources can include virtual machines, databases, storage accounts, networking components, web applications, and more.

Creating a resource in Azure portal
Step 3: Create a new container
Next, navigate to the "Containers" category from the options available on the left pane. Click on Containers as shown by the arrow in the screenshot.
Again, Kubernetes is a container orchestration platform. It manages and orchestrates the deployment, scaling, and operation of application containers across clusters of machines. Kubernetes provides a framework for automating the deployment, scaling, and management of containerized applications.

Creating new container (Kubernetes) in Azure
Step 4: Create a new Azure Kubernetes Service (AKS)
Select "Azure Kubernetes Service (AKS)" from the list of available container services and click Create. This will take you to the AKS creation page.
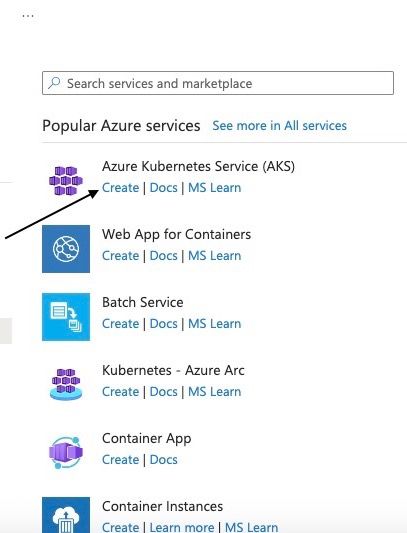
Creating a new Azure Kubernetes service
Step 5: Create a new resource group
In the "Resource group" section, click on "Create new" to create a new resource group for your Azure Kubernetes Service (AKS) deployment.
In Azure, a "resource group" is a logical container used to group together related Azure resources. It serves as a way to organize and manage these resources collectively, rather than individually.
When you create resources such as virtual machines, databases, storage accounts, or any other Azure service, you typically associate them with a resource group.
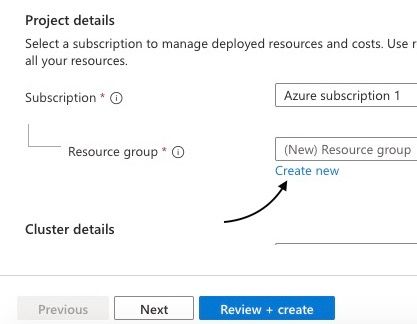
Creating a new resource group in azure portal
Let's name the resource group "AZURE-POSTGRES-RG" as shown below. You can name it anything you like. Then click ok.
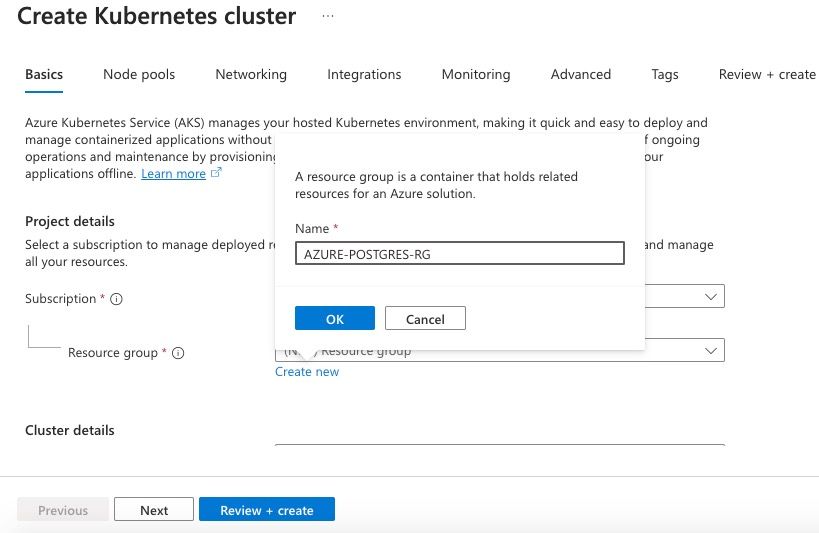
Inputting name for the resource group
Step 6: Give your Kubernetes cluster a name
Now let's name the session for configuring the Kubernetes cluster "Kubernetes Cluster Name".
In Azure, a Kubernetes cluster is a managed container orchestration service provided by Azure Kubernetes Service (AKS). It allows you to deploy, manage, and scale containerized applications using Kubernetes without having to manage the underlying infrastructure.
Give it a name like "AZURE-POSTGRES-KC" and and select a region that's close to you. In my case I select (Asia Pacific) East Asia and click next.
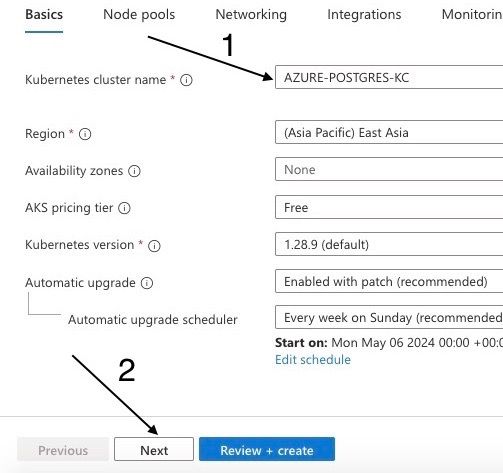
Naming the Kubernetes cluster name
Step 7: Navigate to the node pool page
Now it's time to configure the node pool session by clicking on the agentpool.
In Azure, a node pool is a group of virtual machines (VMs) that are provisioned and managed together within an Azure Kubernetes Service (AKS) cluster. Each node pool runs a specific version of Kubernetes and has its own set of configurations, such as VM size, OS image, and node count.
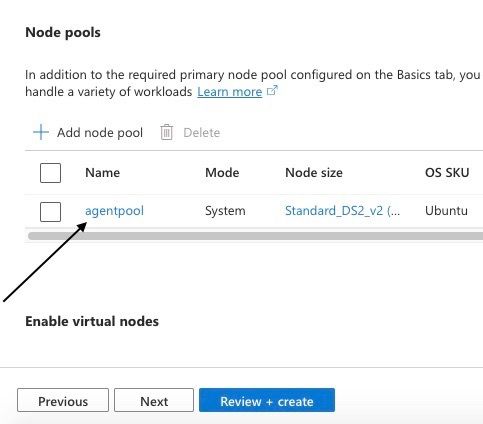
Editing agentpool
Set the minimum node count to 1, maximum node count to 2, and the maximum pods per node to 30 to minimise cost. Then click update.
These parameters help control the size and behavior of the node pool in an Azure Kubernetes Service (AKS) cluster:
Minimum Node Count: Ensures a minimum number of nodes are always available for consistent performance and availability, even during low-demand periods.
Maximum Node Count: Sets an upper limit on the number of nodes in the node pool to manage costs and prevent over-provisioning.
Maximum Pods per Node: Defines the maximum number of pods that can run on each node, optimizing resource utilization and preventing overcrowding.
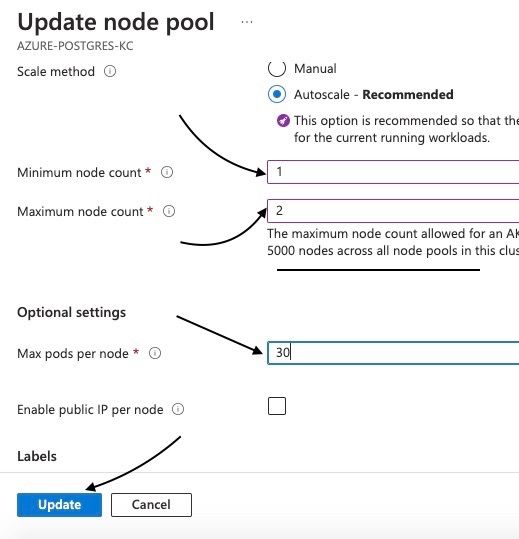
Updating agentpool details
Once you've clicked "Update," you'll be directed to the "Networking" section as shown below. Keep the page as is and proceed by clicking "Next." This will take you to Integration session.
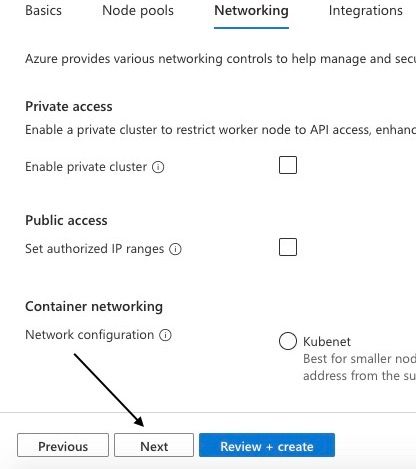
Navigating to Next Page
Azure Container Registry (ACR) is a fully managed private Docker registry service provided by Microsoft Azure. It enables developers to store, manage, and deploy Docker container images securely within their Azure environment.
You will need a place to store the Docker image that's pulled.
To begin, select "Create New" to set up a new container registry. This action will bring up a page where you can input the necessary details, as illustrated on the right side of the image below. Enter the details as indicated by the arrows and then click "Okay." Once you're done, proceed by clicking "Next."
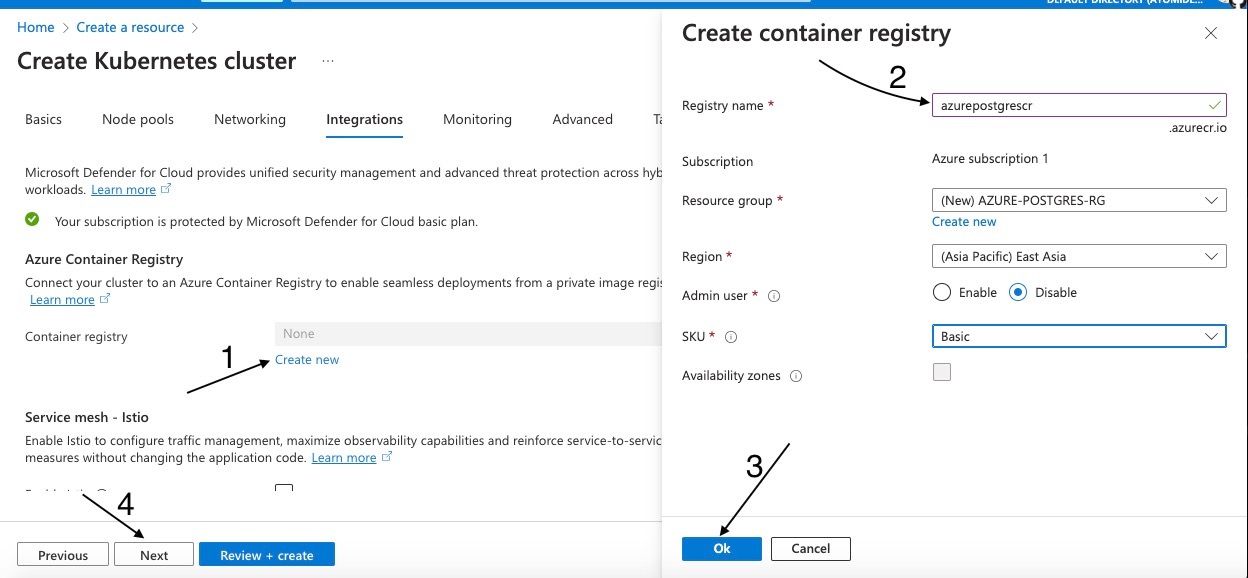
Naming and editing Azure Container Registry details
Step 8: Enable container logs and set up alerts
The Enable Container Logs option allows you to turn on logging for your containers. Logging records important information about what's happening inside your containers, like errors, warnings, and other events. It's useful for troubleshooting and monitoring your applications.
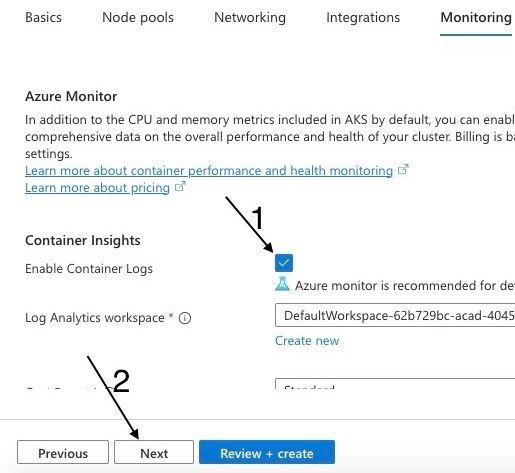
Choosing container logs
Step 9: Advanced section
Keep the Monitoring section unchanged and proceed by clicking "Next."
Navigating to Next Page
Step 10: Tags
Keep the Tags section unchanged and proceed by clicking "Next."
Navigating to Next Page
Step 11: Click "Review + create" to finalize the deployment
Once completed, your resource group, Azure Kubernetes Service (AKS), Azure Container Registry, and Kubernetes cluster will be created.
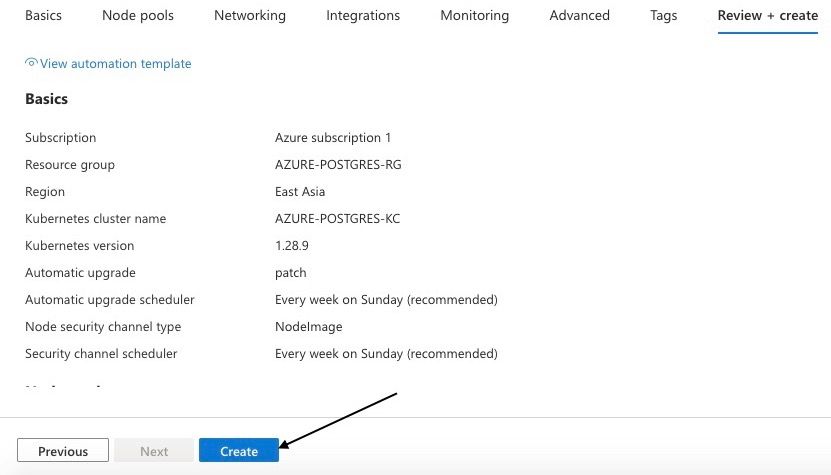
Completing Azure Kubernetes Setup
The screenshot below shows that the deployment was successful.
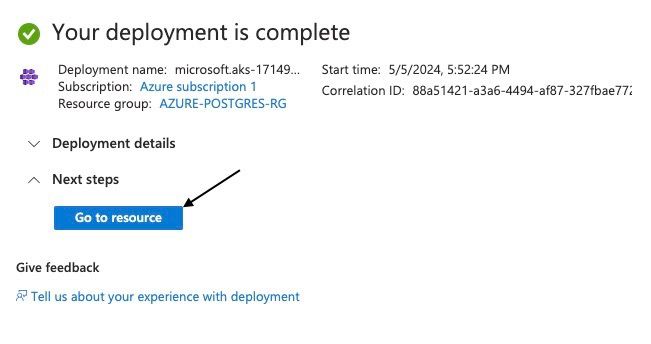
Successful Deployment
You've just successfully created an Azure Kubernetes Service from the Azure portal. Congrats!
How to Connect to Your AKS Cluster Using the Command Line
After successfully creating a new AKS in the Azure portal, the next step is to establish a connection to that cluster.
In this section, I'll guide you through Azure login, configuring kubectl to use the current context, and creating the YAML file for our Postgres container. This file will include StatefulSet, persistent volume, persistent volume claim, config map, and using Azure File for data storage.
I'll also show you how to run a Node.js Express application locally, use Postman to test the endpoints, and receive a response confirming that data was sent to the database successfully.
Download Azure CLI and kubectl
To start, you'll need to download the Azure CLI and kubectl.
Azure CLI (Command-Line Interface): a command-line tool provided by Microsoft for managing Azure resources. It allows users to interact with Azure services and resources directly from the command line, making it easy to automate tasks, create scripts, and manage Azure resources programmatically.
kubectl: a command-line tool for managing Kubernetes clusters, used to deploy, scale, and manage containerized applications. It allows users to perform operations like deploying applications, managing pods, services, and deployments, inspecting cluster resources, scaling applications, and debugging issues, simplifying management of containerized workloads in a Kubernetes environment.
I'm using the warp terminal. Warp is the terminal reimagined with AI and collaborative tools for better productivity. You can run the command using PowerShell on Windows or Terminal on Mac. I'm using a MacBook.
Verify if the Azure CLI is installed by typing the command az --version
Once the download finishes, verify whether Azure CLI is installed on your computer by running the command az --version. If the installation is successful, you should see an output similar to this:
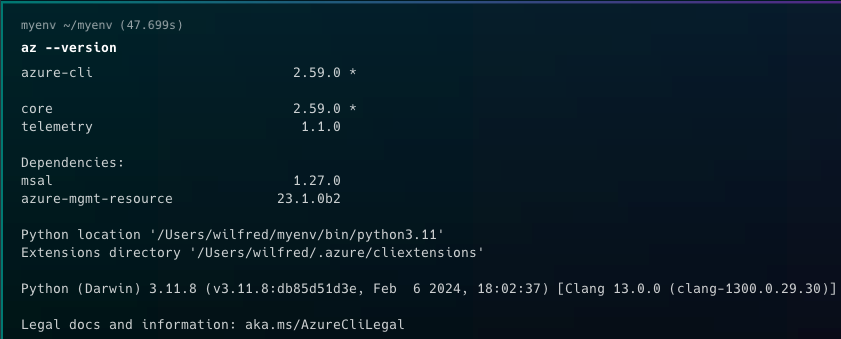
Verifying Azure CLI Installation
Verify if kubectl is installed
To check if kubectl is installed, just type kubectl version in the command line.

Verifying Kubectl Installation
Login to your Azure account
Enter az login in the command line. This will open your browser and prompt you to sign in to your Azure account.
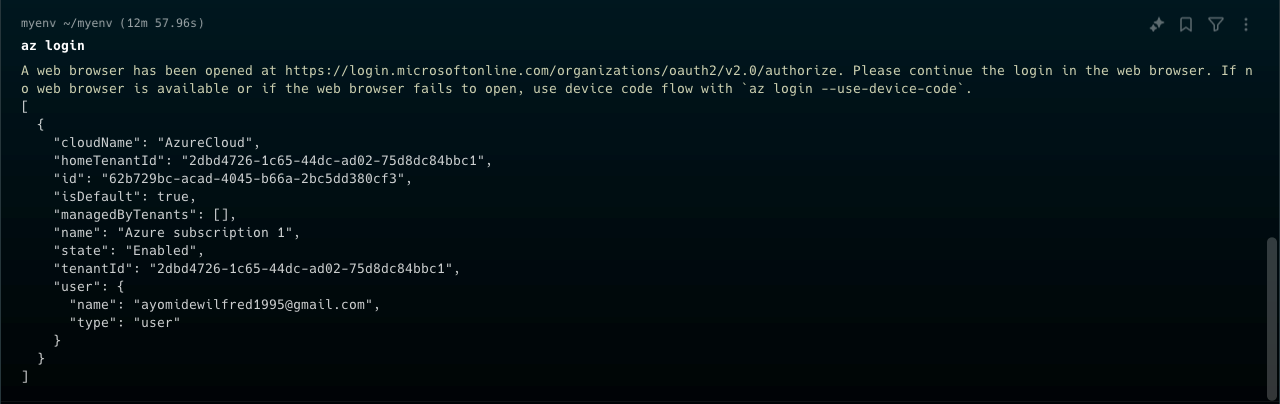
Logging into Azure
After signing in, it shows details about your Azure subscription, including the subscription name, ID, and user information.
Select an Azure subscription
Azure subscriptions are logical containers used to provision resources in Azure. You'll need to locate the subscription ID that you plan to use in this module. Use the command to list your Azure subscriptions:
az account list --output table
Use the following command to ensure you're using an Azure subscription that allows you to create resources for the purpose of this module, substituting your subscription ID (SubscriptionId):
az account set --subscription "Name of the subscription"
Configure kubectl to connect to your Azure Kubernetes
Replace Your_Azure_Resource_groups_name in the code below with the name you chose when creating a resource group. Also, replace your_azure_kubernetes_service_name with the name of your Kubernetes cluster. Then, execute the following command:
az aks get-credentials --resource-group [Your_Azure_Resource_groups_name] --name [your_azure_kubernetes_service_name]
The output should look like this:

Merging kubectl with Azure Kubernetes Service
Verify if kubectl has been merged successfully
Run the following command kubectl get nodes:

Verifying if merged is successful
When you run this command, Kubernetes communicates with the cluster's control plane to fetch a list of all the nodes that are part of the cluster you created. As you can see, this is the node that was running in the Kubernetes cluster we created inside Azure.

Virtual Node running in AKS cluster
Run the command kubectl get pods

Displaying Pod Information
When you run the command kubectl get pods, Kubernetes attempts to retrieve information about all pods within the default namespace of your cluster. But in this case, the output indicates that there are no resources (pods) found within the default namespace, implying that no pods currently exist in that namespace.
A namespace in Kubernetes is a virtual cluster environment within which resources like pods, services, and deployments are organized and isolated. It's a way to divide cluster resources between multiple users, teams, or projects. Namespaces provide a scope for names and make it easier to manage and control access to resources.
By default, Kubernetes starts with a "default" namespace, but you can create additional namespaces to organize and manage resources more effectively. Namespaces help prevent naming conflicts and provide a logical separation of resources, allowing different teams or projects to work independently within the same Kubernetes cluster.
Create a namespace

Creating Namespace
When you run the command kubectl create namespace database, Kubernetes creates a new namespace named "database." The output "namespace/database created" confirms that the namespace has been successfully created.
You can now use this namespace to organize and manage resources related to databases within the Kubernetes cluster.
Confirm the namespace
The command kubectl get namespace lists all namespaces in the Kubernetes cluster including the database namespace we just created, showing their names, status (active), and age.

Confirming namespace
Get pod information in database namespace

Displaying Pod Information related to database namespace
This command, kubectl get pods -n database, attempts to fetch information about pods specifically within the "database" namespace. But the output No resources found in database namespace indicates that there are currently no pods deployed in the "database" namespace.
How to Create Resources with YAML
Let's explore creating resources with YAML to provision our PostgreSQL database running in an Azure Kubernetes cluster. But first, what exactly is YAML?
Kubernetes YAML is a configuration file written in YAML (YAML Ain't Markup Language). They define how Kubernetes resources like pods, deployments, and services should be set up within a cluster. These files are easy to read and specify details like resource names, types, specifications, labels, and annotations. They're crucial for deploying applications and infrastructure on Kubernetes clusters.
YAML is what you will use to create Kubernetes resources that will run Postgres.
First, you need to clone this GitHub repository. Inside, you'll find a Node.js Express application and a YAML file. The Node.js app allows users to register with their email, password, and full name, and also enables them to log in by verifying their details in the database. If their details are found, it displays a success message.
Clone the repository
Create a new folder on your computer and then clone this repository into it.
Open your terminal or PowerShell, go to the folder you want, and use the command below to clone the repository into your computer in that location.
git clone https://github.com/ayowilfred95/Azure-k8s-postgres.git
Open the cloned repository in any text editor
I'm using Visual Studio Code, but feel free to use any text editor you prefer. Here's the structure of the project:
Project folder structure
Install project dependencies
Open the terminal in VS Code and go to the main directory of the project. Next, execute the command npm install to install all the required packages and dependencies for the project:
npm install
Since the backend application is a Node.js Express app, you use npm to install dependencies (similar to how we use maven clean install in Java).
After the dependencies are installed, open the file named "postgres.yaml". It holds all the YAML configurations required to set up your PostgreSQL database that will run in the Kubernetes cluster.
YAML Configuration
In the postgres.yaml file, there are five configurations separated by ---. It's important to use this "---" symbol when declaring different types of Kubernetes resources. If you forget to do this, you'll encounter an error.
StorageClass
The first one is the StorageClass. This YAML configuration defines a StorageClass in Kubernetes for managing storage resources.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azuredisk-premium-retain
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Retain # Retain or Delete
volumeBindingMode: WaitForFirstConsumer # WaitForFirstConsumer or Immediate
allowVolumeExpansion: true # true or false
parameters:
storageaccounttype: Premium_LRS # Premium or Standard
kind: Managed
Let's break down what each part means:
kind: StorageClass: Indicates the type of Kubernetes resource being defined, which is aStorageClass. AStorageClassdefines the class of storage offered by a cluster.apiVersion: storage.k8s.io/v1: Specifies the Kubernetes API version being used for this resource.metadata: name: azuredisk-premium-retain: Provides metadata for theStorageClass, including its name, which in this case is "azuredisk-premium-retain".provisioner: kubernetes.io/azure-disk: Specifies the provisioner responsible for provisioning storage. In this case, it's "kubernetes.io/azure-disk", indicating that Azure Disk will be used as the storage provisioner.reclaimPolicy: Retain: Defines the reclaim policy for the storage resources. It specifies what action should be taken when the associated persistent volume is released. Here, it's set to "Retain", meaning the volume is retained even after it's no longer used by a pod.volumeBindingMode: WaitForFirstConsumer: Specifies the volume binding mode, which determines when volume binding should occur. In this case, it's set to "WaitForFirstConsumer", meaning the volume will be bound when the first pod using it is created.allowVolumeExpansion: true: Indicates whether volume expansion is allowed. Setting it to "true" means that the size of the volume can be increased if needed.parameters: Contains additional parameters specific to the provisioner. Here, it specifies the storage account type as "Premium_LRS" and the kind of storage as "Managed".
Overall, this configuration sets up a StorageClass named "azuredisk-premium-retain" using Azure Disk as the provisioner, with specific policies and parameters tailored for Azure storage.
PersistentVolumeClaim
The second configuration in the postgres.yaml file is the persistent volume claim.
This YAML configuration defines a PersistentVolumeClaim (PVC) in Kubernetes, which is used to request storage resources.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: azure-managed-disk-pvc
spec:
accessModes:
- ReadWriteOnce # ReadWriteOnce, ReadOnlyMany or ReadWriteMany
storageClassName: azuredisk-premium-retain
resources:
requests:
storage: 4Gi
Let's break down what each part means:
apiVersion: v1: Specifies the Kubernetes API version being used for this resource.kind: PersistentVolumeClaim: Indicates the type of Kubernetes resource being defined, which is a PersistentVolumeClaim. A PVC is used by pods to request storage resources.metadata: name: azure-managed-disk-pvc: Provides metadata for the PersistentVolumeClaim, including its name, which is "azure-managed-disk-pvc".spec: Describes the desired state of the PersistentVolumeClaim.accessModes: - ReadWriteOnce: Specifies the access mode for the volume. Here, it's set to "ReadWriteOnce", meaning the volume can be mounted as read-write by a single node at a time.storageClassName: azuredisk-premium-retain: Specifies theStorageClassto use for provisioning the volume. This PVC will use theStorageClassnamed "azuredisk-premium-retain" defined previously.resources: requests: storage: 4Gi: Specifies the desired storage capacity for the volume. Here, it requests 4 gigabytes (Gi) of storage.
Overall, this configuration sets up a PersistentVolumeClaim named "azure-managed-disk-pvc" requesting storage resources with specific access modes, storage class, and storage capacity.
ConfigMap
The third configuration in the postgres.yaml file is the config map. This YAML configuration defines a ConfigMap in Kubernetes, which is used to store configuration data in key-value pairs.
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
labels:
app: postgres
data:
POSTGRES_DB: freecodecamp
POSTGRES_USER: freecodecamp1
POSTGRES_PASSWORD: freecodecamp@
PGDATA: /var/lib/postgresql/data/pgdata
Let's break down what each part means:
apiVersion: v1: Specifies the Kubernetes API version being used for this resource.kind: ConfigMap: Indicates the type of Kubernetes resource being defined, which is aConfigMap. AConfigMapis used to store non-confidential data in key-value pairs.metadata: name: postgres-config: Provides metadata for theConfigMap, including its name, which is "postgres-config".labels: app: postgres: Labels are key-value pairs used to organize and select resources. Here, a label "app" with the value "postgres" is applied to theConfigMap.data: Contains the key-value pairs of configuration data.POSTGRES_DB: pisonitsha: Specifies the name of the PostgreSQL database as "pisonitsha".POSTGRES_USER: pisonitsha1: Specifies the username for accessing the PostgreSQL database as "pisonitsha1".POSTGRES_PASSWORD: pisonitsha@: Specifies the password for accessing the PostgreSQL database as "pisonitsha@".PGDATA: /var/lib/postgresql/data/pgdata: Specifies the location of PostgreSQL data directory as "/var/lib/postgresql/data/pgdata".
Overall, this configuration sets up a ConfigMap named "postgres-config" containing key-value pairs of configuration data, such as database name, username, password, and data directory location, which can be used by other Kubernetes resources.
Note: It's recommended to avoid hardcoding secret variables such as POSTGRES_DB, POSTGRES_PASSWORD,PGDATA and instead store them in secret files, for the sake of simplicity in this tutorial, we'll keep them hardcoded.
StatefulSet
The fourth configuration is the stateful set.This YAML configuration defines a StatefulSet in Kubernetes, which is used to manage stateful applications like databases.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres
selector:
matchLabels:
app: postgres
replicas: 1
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:10.4
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5432
envFrom:
- configMapRef:
name: postgres-config
volumeMounts:
- name: azure-managed-disk-pvc
mountPath: /var/lib/postgresql/data
volumes:
- name: azure-managed-disk-pvc
persistentVolumeClaim:
claimName: azure-managed-disk-pvc
```
Let's break down what each part means:
* `apiVersion: apps/v1`: Specifies the Kubernetes API version being used for this resource.
* `kind: StatefulSet`: Indicates the type of Kubernetes resource being defined, which is a `StatefulSet`. `StatefulSets` are used to manage stateful applications by providing unique **identities** and stable **network** identities to each pod.
* `metadata: name: postgres`: Provides metadata for the `StatefulSet`, including its name, which is "postgres".
* `spec`: Describes the desired state of the `StatefulSet`.
* `serviceName: postgres`: Specifies the name of the Kubernetes service that will be used to access the `StatefulSet` pods.
* `selector: matchLabels: app: postgres`: Selects the pods controlled by this `StatefulSet` based on the label "app: postgres".
* `replicas: 1`: Specifies the desired number of replicas (instances) of the StatefulSet, which is 1 in this case.
* `template`: Defines the pod template used to create pods managed by the `StatefulSet`.
* `metadata: labels: app: postgres`: Labels applied to the pods created from this template.
* `spec`: Describes the specification of the containers within the pod.
* `containers`: Specifies the containers running in the pod.
* `name: postgres`: Defines the name of the container as "postgres".
* `image: postgres:10.4`: Specifies the Docker image used for the container, which is "postgres:10.4".
* `imagePullPolicy: "IfNotPresent"`: Specifies the policy for pulling the container image, which is "IfNotPresent", meaning it will only pull the image if it's not already present on the node.
* `ports: containerPort: 5432`: Specifies the port that the PostgreSQL service inside the container is listening on.
* `envFrom: configMapRef: name: postgres-config`: Injects environment variables from a ConfigMap named "**postgres-config**" that you defined earlier.
* `volumeMounts: name: azure-managed-disk-pvc mountPath: /var/lib/postgresql/data`: Mounts a persistent volume claim named "azure-managed-disk-pvc" to the container at the specified path.
* `volumes: name: azure-managed-disk-pvc persistentVolumeClaim: claimName: azure-managed-disk-pvc`: Defines the persistent volume claim named "azure-managed-disk-pvc" to be used by the pod.
Overall, this configuration sets up a StatefulSet named "postgres" with one replica, running a PostgreSQL container with specific settings and mounted persistent storage.
### Service
The fifth configuration is the **service**. This YAML configuration defines a **Service** in Kubernetes, which is used to expose the `StatefulSet` we declared earlier as a network service.
```bash
apiVersion: v1
kind: Service
metadata:
name: postgres
labels:
app: postgres
spec:
type: LoadBalancer
selector:
app: postgres
ports:
- protocol: TCP
name: https
port: 5432
targetPort: 5432
Let's break down what each part means:
apiVersion: v1: Specifies the Kubernetes API version being used for this resource.kind: Service: Indicates the type of Kubernetes resource being defined, which is a Service. Services allow pods to be accessed by other pods or external users.metadata: name: postgres: Provides metadata for the Service, including its name, which is "postgres".labels: app: postgres: Labels are key-value pairs used to organize and select resources. Here, a label "app" with the value "postgres" is applied to the Service.spec: Describes the desired state of the Service.type: LoadBalancer: Specifies the type of Service, which is "LoadBalancer". This type allows the Service to be exposed externally with a cloud provider's load balancer.selector: app: postgres: Selects the pods controlled by the Service based on the label "app: postgres".ports: Specifies the ports that the Service will listen on.protocol: TCP: Specifies the protocol used for the port, which is TCP.name:https: Specifies a name for the port, which is "https".port: 5432: Specifies the port number on which the Service will listen, which is 5432.targetPort: 5432: Specifies the target port on the pods to which traffic will be forwarded, which is also 5432. This means that traffic received on port 5432 of the Service will be forwarded to port 5432 on the pods.
Overall, this configuration sets up a Service named "postgres" with a LoadBalancer type, forwarding traffic on port 5432 to pods labeled with "app: postgres".
How to Deploy YAML Resource to Azure Kubernetes Service (AKS)
You've previously connected "kubectl" with the Azure Kubernetes Service (AKS) you set up. Let's double-check it.
In your VS Code terminal, rerun the command kubectl get nodes. You'll see an output like this, though your node's value will be different.

Displaying node information running in Azure Kubernetes cluster
Next, verify the namespace you previously created by executing the command: kubectl get namespace database. Your output should resemble this:

Retrieving Namespace Information
Deploy the YAML resource
Once you've confirmed everything is set, you can deploy the YAML resource. This will establish your PostgreSQL database in the Azure Kubernetes cluster you've configured.
Run the below command in the main directory where the configuration file is located. Currently, I'm in the project's root directory (azure-k8s-postgres). To deploy the database, just execute this command below:
kubectl apply -n database -f postgres.yaml
Your output should look like this. This output confirms that all these components have been successfully created in Kubernetes.

Applying Configuration to Namespace
Execute the command below to verify that the pod is running:
kubectl get pods -n database
Your output should look like this:

Fetching Pods in Namespace
This output confirms that a pod name "postgres-0" is running in your Azure Kubernetes Cluster. But it was not the only pod you created. As I said earlier, to connect to a pod, you need what is called service. And you have declared a service resource in our configuration file which has also been deployed into your Kubernetes.
To get the status of the service, run this command:
kubectl get services -n database
Your output should look like this:

Retrieving Services in Namespace
This output displays the services in the "database" namespace, including a service named "postgres" with the type "LoadBalancer," its internal cluster IP, external IP, and port mappings. You'll utilize the external IP along with the Postgres port "5432" to connect your database with the Node.js application. Note that your external IP will differ from mine.
Node.js Application
In this section, I'll guide you through setting up your Node.js app to connect to a PostgreSQL database in your Azure Kubernetes Service.
We'll cover sending data into the database and retrieving it using Postman. Also, I'll demonstrate how to check if the data remains in the database even if the pod running PostgreSQL in the cluster is deleted.
Configure your Node.js application
Go to the database folder and open the database.js file. Replace the host with your EXTERNAL-IP obtained from the service, and leave the rest unchanged since you've already defined those variables in your config map.
Your database.js file should resemble the CodeSnap below:

CodeSnap of database.js Configuration
Run your Node.js application
In your VS Code terminal, execute this command to start the Node.js application locally:
npm start
Your output should look like this if the connection is established successfully.

Server Listening on Port 4000
If your output looks the same as mine, it indicates that you've successfully connected your Node.js application to the PostgreSQL database running in your Azure Kubernetes cluster. Congratulations! 🎉
Test the application
Testing is a fundamental principle in DevOps operations. It helps us understand the state of the application we've built before releasing it to users. Any application that doesn't pass the testing stage will not be deployed. This is a rule in DevOps.
For this tutorial, you'll be using Postman. You can download Postman here. Postman enables you to test API endpoints by receiving status responses.
Check out this post on how to use Postman to test APIs. If you want to learn more, here's a full course on the subject.
Open your Postman application
To begin using Postman, start by creating a new API request in your preferred workspace. Choose POST. POST requests add new data to the database or server. Then, paste the endpoint URL (localhost:4000/api/v1/admin/register) for your Postman test.
The below screenshot illustrates how you will create a POST request.

Postman URL Endpoint Configuration
In the body, paste the JSON data shown below inside it as shown below:
{
"fullName":"Azure postgres freecodecamp",
"email":"freecodecamp@gmail.com",
"password":"freecodecamp"
}
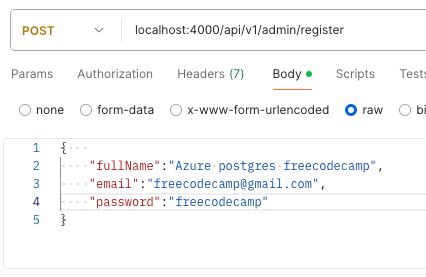
Postman Request Body
Once you've set up the request, just click the "Send" button to send it. Postman will then show you status codes, and the response payload as shown below.
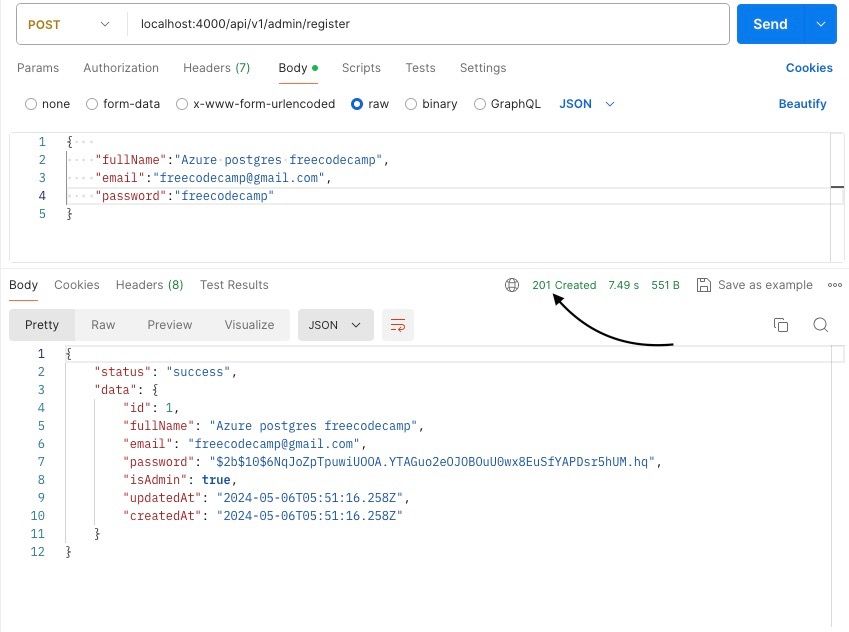
Postman API Response
Confirm the data
To confirm that the data you sent into the database exists, make a GET request to this endpoint URL: localhost:4000/api/v1/admin/freecodecamp@gmail.com
Postman GET Request URL Endpoint
When you click send, Postman will then show you status codes and the response payload as shown below. Notice that we didn't put anything in the body because this is a GET request.
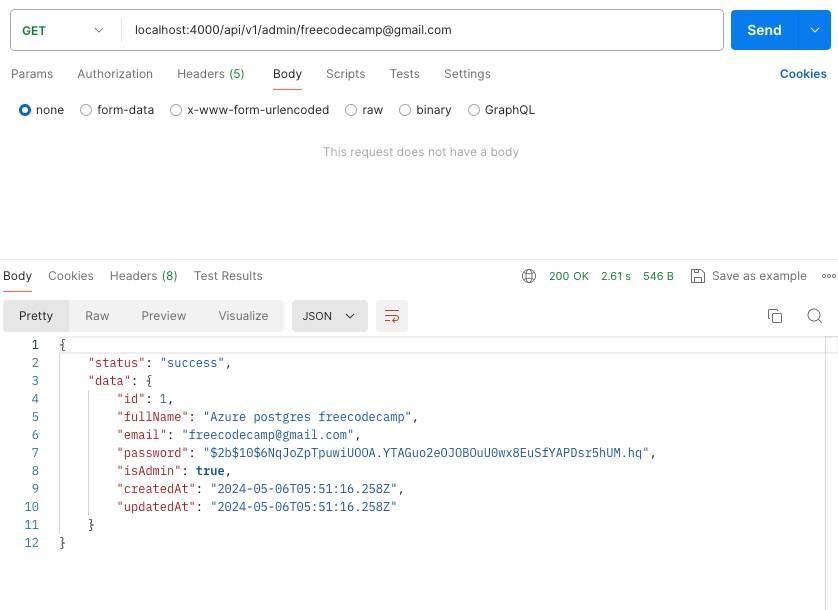
Postman GET Request by Email Retrieval Response
Delete the pod to confirm data persistence
We chose to create our PostgreSQL database using a StatefulSet to ensure that data persists even if the pod is destroyed. Let's test this by deleting the pod and checking if the data remains intact.
In your VS Code terminal, execute the command: kubectl delete pod -n database postgres-0.
This command deletes a pod named "postgres-0" in the "database" namespace from your Kubernetes cluster. Your output should look like this.

Deleting Pod in Namespace:
Pod recreation
Kubernetes has a built-in feature called replication controllers or replica sets that ensure a specified number of pod replicas are running at any given time. If a pod is deleted, Kubernetes will automatically recreate it to maintain the desired number of replicas, ensuring high availability
If you run kubectl get pods -n database, you'll notice that Kubernetes has created a new pod with the same name, "postgres-0", to replace the one that was deleted. This ensures that the application remains available and continues to function as expected.

Pod Recreated back in Namespace
Data persistence
Navigate back to Postman and make a GET request to the endpoint URL localhost:4000/api/v1/admin/freecodecamp@gmail.com.
You should get the same response as before. So under the hood, when we delete the pod, the storage disk was not deleted. The storage disk is inside the Azure disk. How do we know that? If you run this command:
kubectl get pvc -n database
you should get this output:

Persistennce Volume Claim details in namespace
This shows details about a storage called "azure-managed-disk-pvc" in your Kubernetes. It's currently in use and has 4 gigabytes of space available. It's set up to be read and written to by one system at a time. This storage is provided by a service called "azuredisk-premium-retain" that we configured earlier.
Clean up resources
In this tutorial, you created Azure resources in a resource group. If you won't need these resources later, delete the resource group from the Azure portal or run the following command in your terminal:
az group delete --name AZURE-POSTGRES-RG --yes
This command might take a minute to run.
Conclusion
We've gone on quite a journey here! You've learned how to deploy a Postgres container in Azure Kubernetes Service (AKS) and integrate it with a Node.js application.
In this tutorial, I guided you through the process of configuring Kubernetes using Azure Kubernetes Service (AKS). You learned to customize YAML files utilizing StatefulSet, Persistent Volume, and Services to deploy a PostgreSQL database on Azure Kubernetes. You also acquired PostgreSQL database credentials running within AKS to establish connectivity with a Node.js application. I then provided detailed instructions on connecting your Node.js Express app to the Postgres container within the AKS cluster.
Thank you for reading!