
By Shittu Olumide
Data is all around us. Every website you visit includes data in a readable format that you can utilize for a project.
And although you can easily copy and paste the data, the best approach for big amounts of data is to perform web scraping.
Learning web scraping can be tricky at first, but with a good web scraping library, things will become much easier.
Web scraping can be a useful tool for gathering data and information, but it is important to ensure that you do it in a safe and legal manner.
Here are some tips for performing web scraping properly:
- Seek permission before you scrape a site.
- Read and understand the website's terms of service and robots.txt file.
- Limit the frequency of your scraping.
- Use web scraping tools that respect website owners' terms of service.
Now that you understand the proper way to approach scraping, let's dive in. In this step-by-step tutorial, we will walk through how to scrape several pages of a website using Python's most user-friendly web scraping module, Beautiful Soup.
This tutorial will be divided into two portions: we will scrape a single page in the first phase. Then in the second section, we'll scrape several pages based on the code used in the first section.
Requirements
Python 3: you'll need to use Python 3 for this tutorial, because the library that we'll use is a Python library. To download and install Python check out the official website.
Beautiful Soup: Beautiful Soup is a Python package for structured data parsing. For parsed pages, it generates a parse tree that you can use to extract data from HTML. It lets you interact with HTML in the same way you can interact with a web page using developer tools.
To begin using it, launch your terminal and install Beautiful Soup:
pip install beautifulsoup4
Requests library: The requests library is the Python standard for making HTTP requests. We'll use this in conjunction with Beautiful Soup to obtain the HTML for a website.
pip install requests
Install a parser: To extract data from HTML text, we need a parser. We'll utilize the lxml parser here. To install this parser, execute the following command:
pip install lxml
Note: You don't have to be a Python professional to follow this tutorial.
How to Scrape a Single Web Page
As I explained earlier, we will start by understanding how to scrape a single web page. Then we'll move on to scraping multiple web pages.
Let's build our first scraper.
Import the libraries
First, let's import the libraries we'll need:
import requests
from bs4 import BeautifulSoup
Get the website HTML
We want to scrape a website with hundreds of pages of movie transcripts. We'll begin by scraping a single page, and then demonstrate how to scrape multiple pages.
First, we'll define the connection. In this example, we'll use the Titanic movie transcript, but you can select any movie you wish.
Then we make a request to the website and receive a response, which we record in the result variable. Following that, we'll use the .text method to retrieve the website's content.
Finally, we'll use the lxml parser to get the soup, which is the object containing all of the data in the nested structure that we'll reuse later.
website = 'https://subslikescript.com/movie/Titanic-120338'
result = requests.get(website)
content = result.text
soup = BeautifulSoup(content, 'lxml')
print(soup.prettify())
Once we have the soup object, we can simply get readable HTML by using .prettify(). Although we may use the HTML printed in a text editor to find elements, it is far easier to go straight to the HTML code of the element we seek. We'll do this in the following phase.
Examine the webpage and HTML code
Before we start writing code, we must first assess the website we want to scrape and the HTML code we got to identify the best strategy to scrape the website. A sample transcript is available below. The things to be scraped are the movie title and transcript.
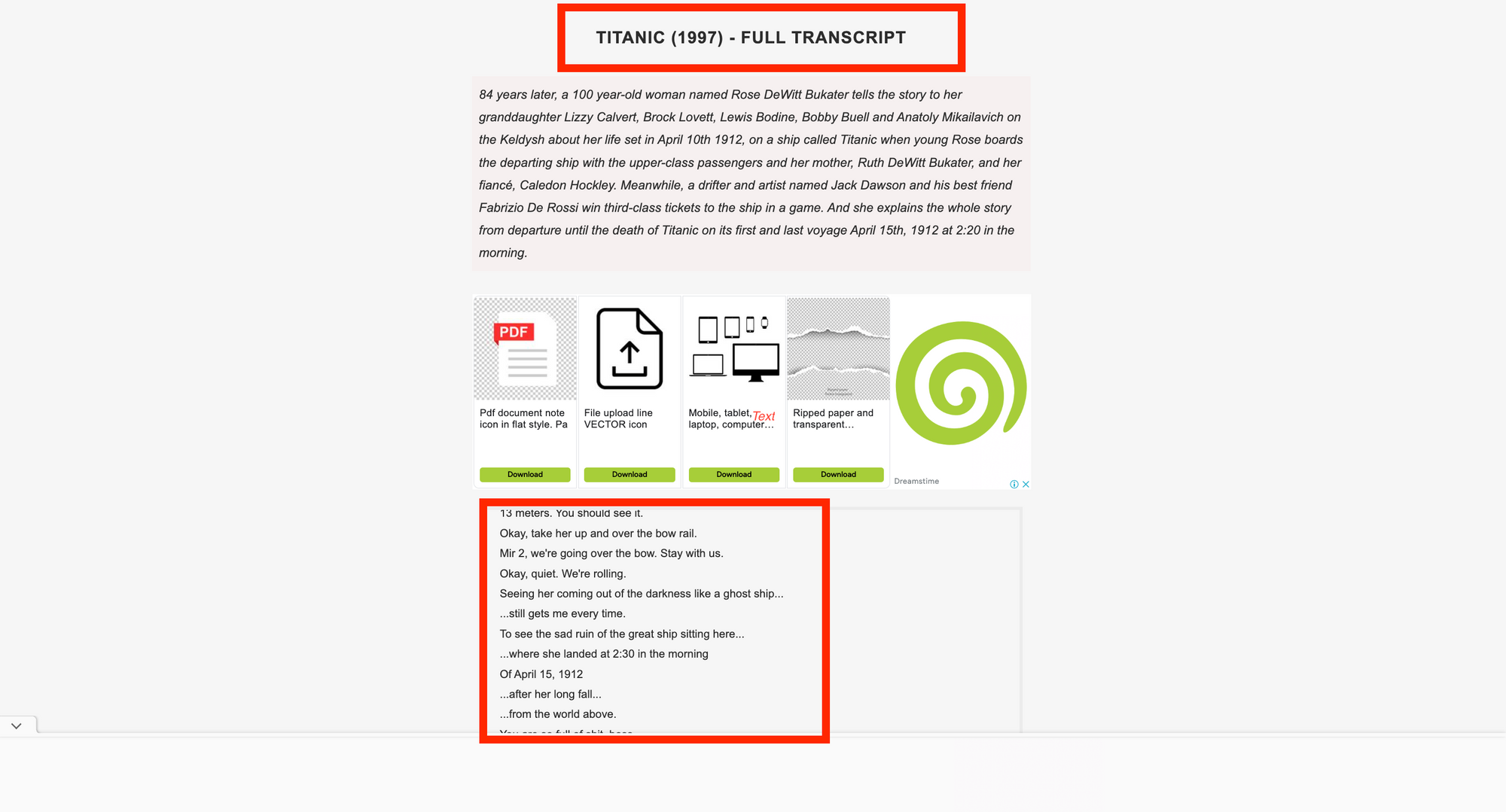 Image showing the title and transcript of the titanic movie.
Image showing the title and transcript of the titanic movie.
To get the HTML code for a given element, perform the following steps:
- Navigate to the Titanic transcript's website.
- Right-click on either the movie title or the transcript. You'll see a list. Select "Inspect" to view the page's source code.
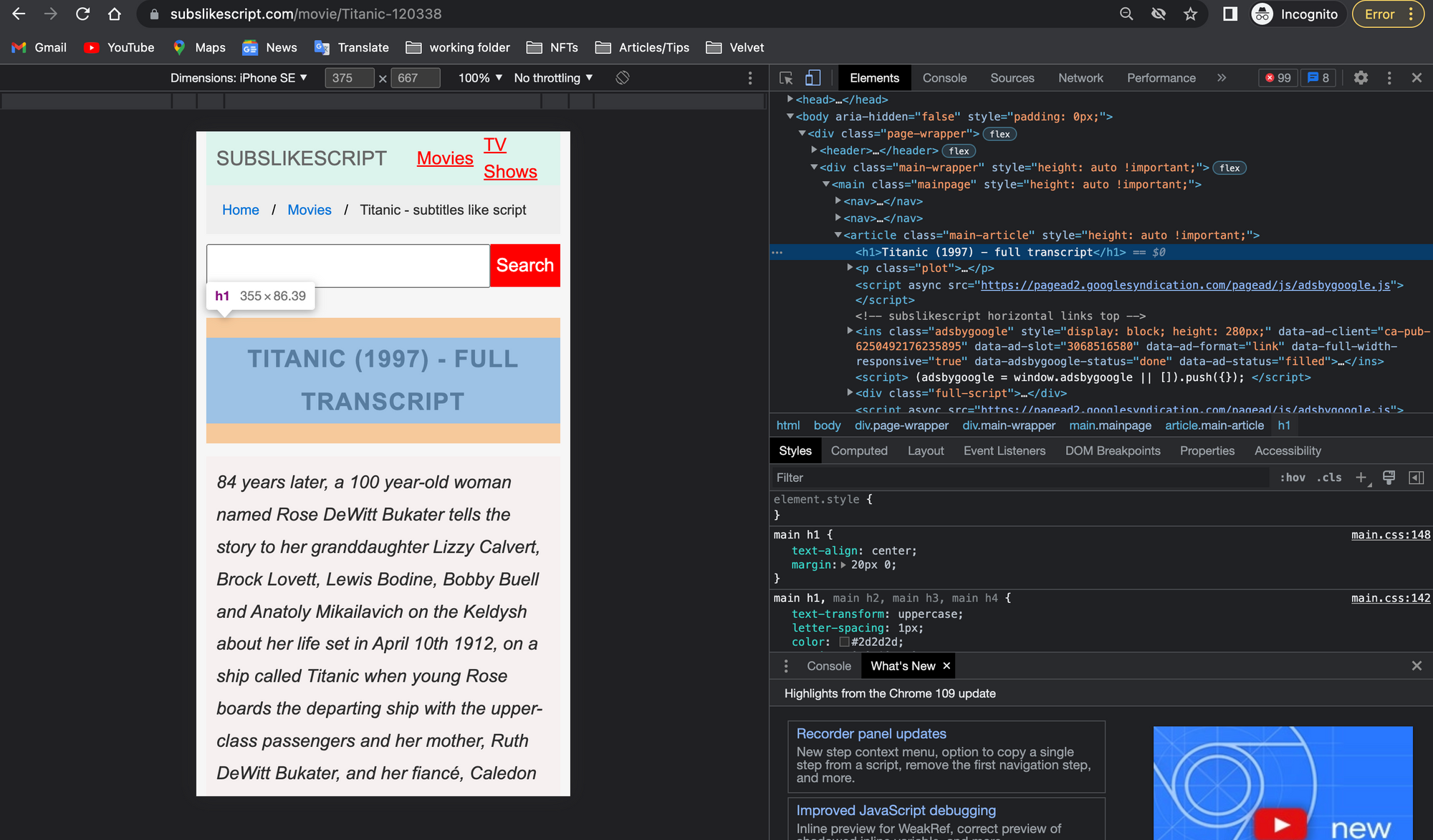 Image showing page source code
Image showing page source code
How to find an element with Beautiful Soup
It's easy to find an element in Beautiful Soup. Simply apply the .find() method to the previously prepared soup.
As an example, find the box containing the movie title, description, and transcript. It's within an article tag and has the class main-article on it. We can use the following code to find that box:
box = soup.find('article', class_='main-article')
The movie title is enclosed in an h1 tag and lacks a class name. After we find it, we use the .get_text() function to retrieve the text within the node:
title = box.find('h1').get_text()
The transcript is included within a div tag and has the class full-script. In this scenario, we'll change the default arguments within the .get_text() function to get the text.
We begin by setting strip=True to eliminate leading and trailing spaces. Then we add a blank space to the separator separator=' ' to ensure that words have a blank space after each new line \n.
transcript = box.find('div', class_='full-script')
transcript = transcript.get_text(strip=True, separator=' ')
So far, we've scraped the data successfully. Print the title and transcript variables to ensure that everything is operating properly.
How to export data into a .txt file
You can store data in CSV, JSON, and other formats. In this example, we'll save the extracted data in a.txt file. To accomplish this, we will use the with keyword, as shown in the code below:
with open(f'{title}.txt', 'w') as file:
file.write(transcript)
Remember to use the f-string to set the file name as the movie title. After running the code, we should have a .txt file in our working directory.
We're ready to scrape transcripts from multiple pages now that we've successfully scraped data from one web page!
How to Scrape Multiple Web Pages
On the transcript page, scroll down and click on the all movie scripts. You can find it at the bottom of the web page.
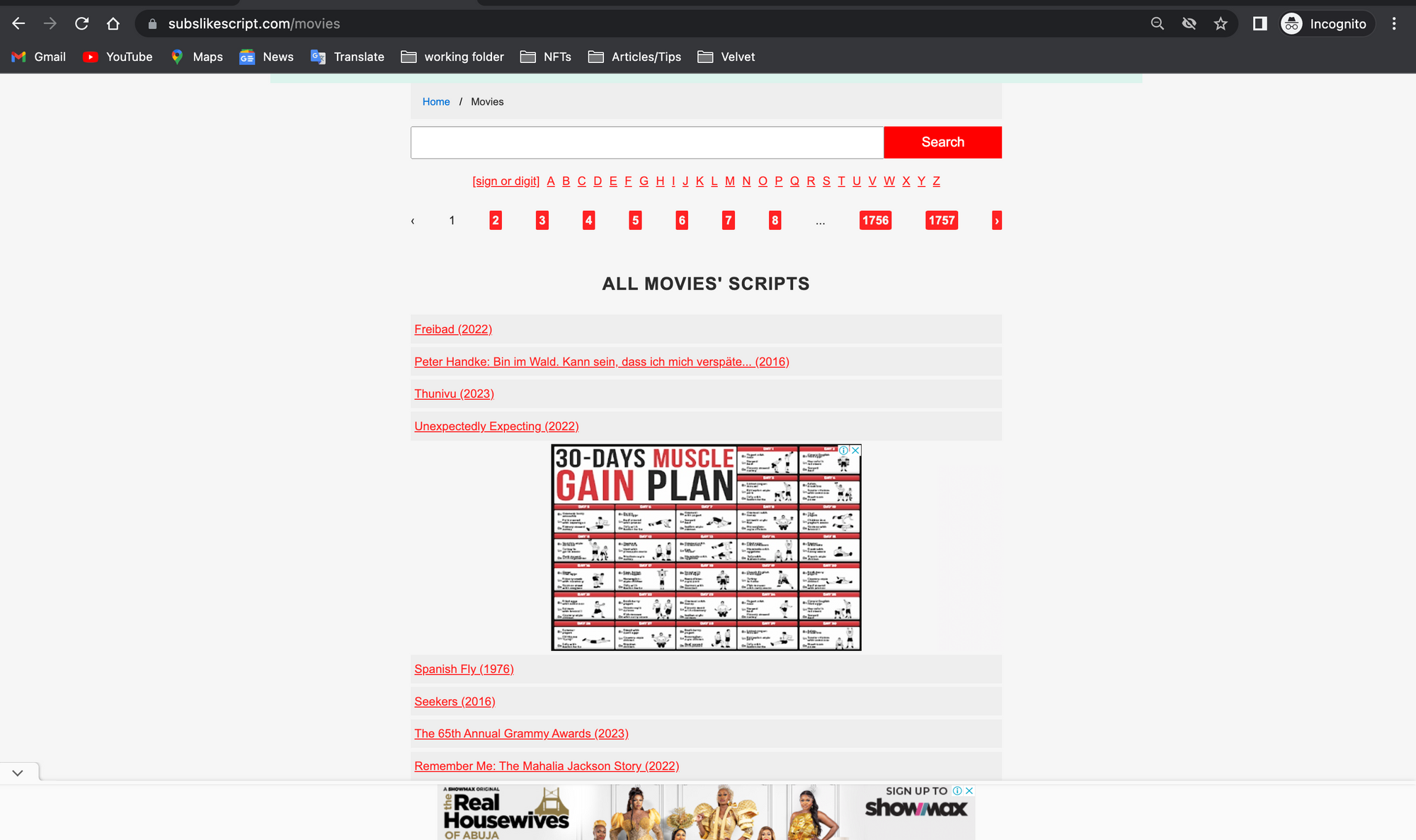 All transcripts page
All transcripts page
The screenshot shows all of the movie transcripts. The website has 1,757 pages, with approximately 30 movie transcripts on each page.
In this section, we will scrape multiple links by obtaining the href attribute of each link. First, we must modify the website to allow scrapin. Our new website variable will be as follows:
root = 'https://subslikescript.com'
website = f'{root}/movies'
The main reason why a root variable is defined in the code is to help scrape multiple web pages later.
How to get the href attribute
Let's start with the href attribute of the 30 movies on one page. Examine any movie title within the "List of Movie Transcripts" box.
Following that, we should have the HTML code. An a tag should be highlighted in blue. Each a tag belongs to a movie title.
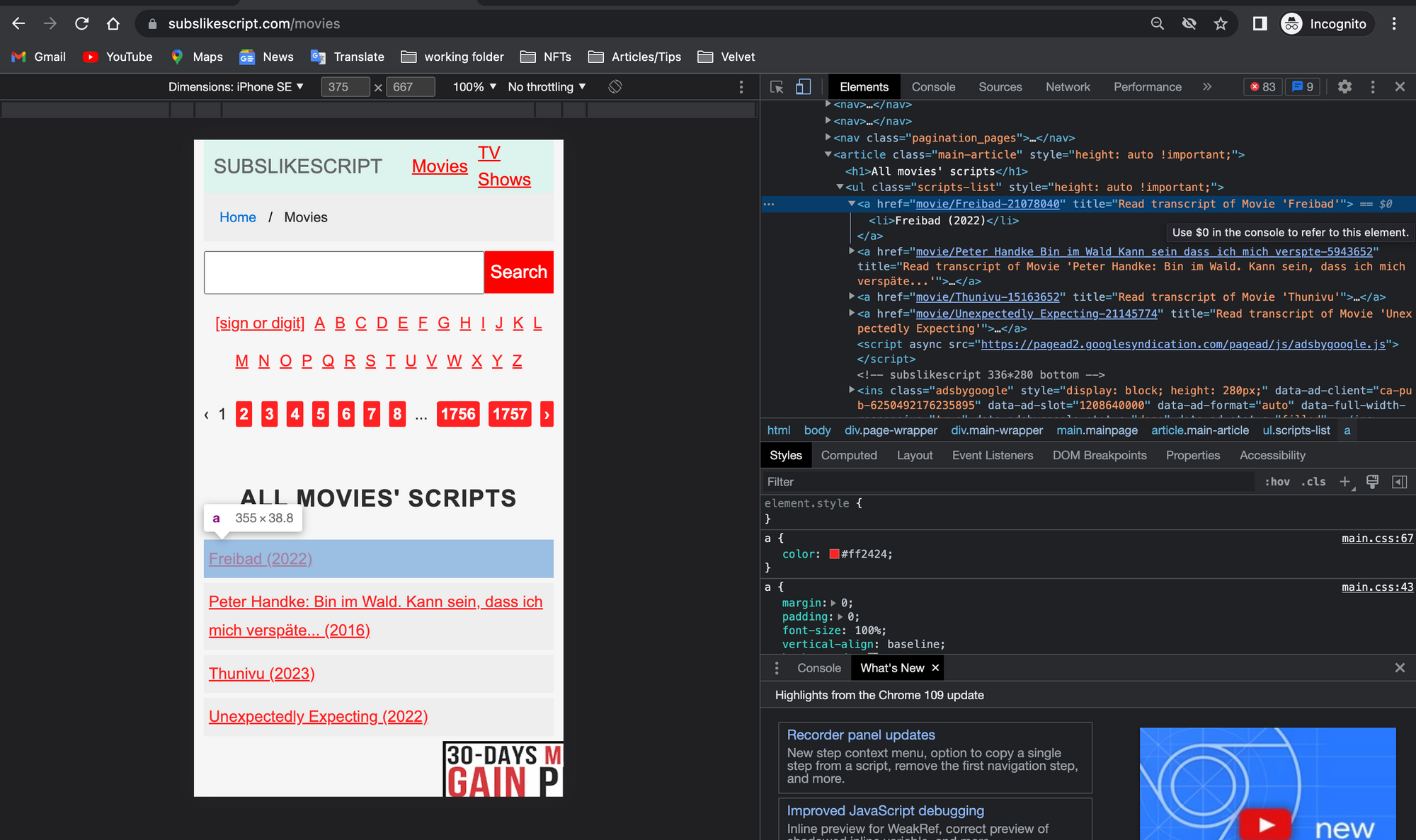
As we can see, the links within the href do not include the root domain subslikescript.com. This is why we created a root variable before concatenating it.
Let's look for all of the a elements on the page.
How to find multiple elements
In Beautiful Soup, we use the .find_all() method to locate multiple elements. To extract the link that corresponds to each movie transcript, we must include the parameter href=True.
box.find_all('a', href=True)
To get the links from the href, add ['href'] to the expression above. However, because the .find_all() method returns a list, we must loop through it and get the hrefs one by one within the loop.
for link in box.find_all('a', href=True):
link['href']
We can use list comprehension to save the links, as shown below:
links = [link['href'] for link in box.find_all('a', href=True)]
print(links)
The links we want to scrape will be visible if you print the links list. In the following step, we'll scrape each page.
How to loop through each link
To scrape the transcript of each link, we'll repeat the steps we used for the first transcript. This time, we'll put those steps inside the for loop below.
for link in links:
result = requests.get(f'{root}/{link}')
content = result.text
soup = BeautifulSoup(content, 'lxml')
As you may recall, the links we previously saved did not include the root subslikescript.com, so we must concatenate it with the expression f'{root}/{link}'.
The rest of the code is identical to what we wrote in the first section of this guide.
Wrapping up
If you want to browse through the web pages, you have two options.
- Check any of the pages that are visible on the webpage (for example, 1, 2, 3, or 1757). Get the
atag with thehrefattribute along with the links for each page. When you have the links, combine them with the root and proceed as described in Section 2 after doing so. - Visit page 2 and copy the link you see there. This is how it ought to appear:
subslikescript.com/movies?page=2. You can see that the website has a consistent format for each page:f'{website}?page={i}'. If you want to go through the first ten pages, you can reuse the website variable and loop between 1 and 10.
Lets connect on Twitter and on LinkedIn. You can also subscribe to my YouTube channel.
Happy Coding!